How ignorant are you?
Do you know?
Do you know how much don’t you know?
It seems hard to accurately estimate your lack of knowledge. It even seems hard to say precisely how hard it is. But the cool thing is, we can actually extract an interesting math question from this problem. And one answer to this question leads to the following conclusion:
There’s no unbiased way to estimate how ignorant you are.
But the devil is in the details. So let’s see the details!
The Shannon entropy of a probability distribution is a way of measuring how ignorant we are when this probability distribution describes our knowledge.
For example, suppose all we care about is whether this ancient Roman coin will land heads up or tails up:

If we know there’s a 50% chance of it landing heads up, that’s a Shannon entropy of 1 bit: we’re missing one bit of information.
But suppose for some reason we know for sure it’s going to land heads up. For example, suppose we know the guy on this coin is the emperor Pupienus Maximus, a egomaniac who had lead put on the back of all coins bearing his likeness, so his face would never hit the dirt! Then the Shannon entropy is 0: we know what’s going to happen when we toss this coin.
Or suppose we know there’s a 90% it will land heads up, and a 10% chance it lands tails up. Then the Shannon entropy is somewhere in between. We can calculate it like this:
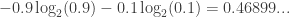
so that’s how many bits of information we’re missing.
But now suppose we have no idea. Suppose we just start flipping the coin over and over, and seeing what happens. Can we estimate the Shannon entropy?
Here’s a naive way to do it. First, use your experimental data to estimate the probability that that the coin lands heads-up. Then, stick that probability into the formula for Shannon entropy. For example, say we flip the coin 3 times and it lands head-up once. Then we can estimate the probability of it landing heads-up as 1/3, and tails-up as 2/3. So we can estimate that the Shannon entropy is

But it turns out that this approach systematically underestimates the Shannon entropy!
Say we have a coin that lands up a certain fraction of the time, say 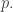

Of course, our estimate will depend on the luck of the game. But on average, it will be less than the actual Shannon entropy, which is

We can prove this mathematically. But it shouldn’t be surprising. After all, if 
If we play the game with more coin flips, the error gets less severe. In fact it approaches zero as the number of coin flips gets ever larger, so that 
One moral here is that naively generalizing on the basis of limited data can make you feel more sure you know what’s going on than you actually are.
I hope you knew that already!
But we can also say, in a more technical way, that the naive way of estimating Shannon entropy is a biased estimator: the average value of the estimator is different from the value of the quantity being estimated.
Here’s an example of an unbiased estimator. Say you’re trying to estimate the probability that the coin will land heads up. You flip it 
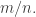
Statisticians like to think about estimators, and being unbiased is one way an estimator can be ‘good’. Beware: it’s not the only way! There are estimators that are unbiased, but whose standard deviation is so huge that they’re almost useless. It can be better to have an estimate of something that’s more accurate, even though on average it’s a bit too low. So sometimes, a biased estimator can be more useful than an unbiased estimator.
Nonetheless, my ears perked up when Lou Jost mentioned that there is no unbiased estimator for Shannon entropy. In rough terms, the moral is that:
There’s no unbiased way to estimate how ignorant you are.
I think this is important. For example, it’s important because Shannon entropy is also used as a measure of biodiversity. Instead of flipping a coin repeatedly and seeing which side lands up, now we go out and collect plants or animals, and see which species we find. The relative abundance of different species defines a probability distribution on the set of species. In this language, the moral is:
There’s no unbiased way to estimate biodiversity.
But of course, this doesn’t mean we should give up. We may just have to settle for an estimator that’s a bit biased! And people have spent a bunch of time looking for estimators that are less biased than the naive one I just described.
By the way, equating ‘biodiversity’ with ‘Shannon entropy’ is sloppy: there are many measures of biodiversity. The Shannon entropy is just a special case of the Rényi entropy, which depends on a parameter 

As
Also, I should add that biodiversity is better captured by the ‘Hill numbers’, which are functions of the Rényi entropy, than by the Rényi entropy itself. (See here for the formulas.) Since these functions are nonlinear, the lack of an unbiased estimator for Rényi entropy doesn’t instantly imply the same for the Hill numbers. So there are also some obvious questions about unbiased estimators for Hill numbers. Do you know answers to those?
Here are some papers on estimators for entropy. Most of these focus on estimating the Shannon entropy of a probability distribution on a finite set.
This old classic has a proof that the ‘naive’ estimator of Shannon entropy is biased, and estimates on the bias:
• Bernard Harris, The statistical estimation of entropy in the non-parametric case, Army Research Office, 1975.
He shows the bias goes to zero as we increase the number of samples: the number I was calling 


Using this idea, he shows that you can find a less biased estimator if you have a probability distribution 



The problem is that in practice you don’t know ahead of time how many probabilities are nonzero! In applications to biodiversity this would amount to knowing ahead of time how many species exist, before you go out looking for them.
But what about the theorem that there’s no unbiased estimator for Shannon entropy? The best reference I’ve found is this:
• Liam Paninski, Estimation of entropy and mutual information, Neural Computation 15 (2003) 1191-1254.
In Proposition 8 of Appendix A, Paninski gives a quick proof that there is no unbiased estimator of Shannon entropy for probability distributions on a finite set. But his paper goes far beyond this. Indeed, it seems like a pretty definitive modern discussion of the whole subject of estimating entropy. Interestingly, this subject is dominated by neurobiologists studying entropy of signals in the brain! So, lots of his examples involve brain signals.
Another overview, with tons of references, is this:
• J. Beirlant, E. J. Dudewicz, L. Györfi, and E. C. van der Meulen, Nonparametric entropy estimation: an overview.
This paper focuses on the situation where don’t know ahead of time how many probabilities are nonzero:
• Anne Chao and T.-J. Shen, Nonparametric estimation of Shannon’s index of diversity when there are unseen species in sample, Environmental and Ecological Statistics 10 (2003), 429&–443.
In 2003 there was a conference on the problem of estimating entropy, whose webpage has useful information. As you can see, it was dominated by neurobiologists:
• Estimation of entropy and information of undersampled probability distributions: theory, algorithms, and applications to the neural code, Whistler, British Columbia, Canada, 12 December 2003.
By the way, I was very confused for a while, because these guys claim to have found an unbiased estimator of Shannon entropy:
• Stephen Montgomery Smith and Thomas Schürmann, Unbiased estimators for entropy and class number.
However, their way of estimating entropy has a funny property: in the language of biodiversity, it’s only well-defined if our samples include at least one species of each organism. So, we cannot compute this estimate for an arbitary list of
To wrap up, let me state Paninski’s result in a mathematically precise way. Suppose 



Here we can use whatever base for the logarithm we like: earlier I was using base 2, but that’s not sacred. Define an estimator to be any function

The idea is that given 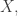
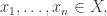

If the samples are independent and distributed according to the distribution 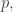

The bias of the estimator is the difference between the sample mean of the estimator and actual value of
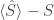
The estimator 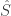
Proposition 8 of Paninski’s paper says there exists no unbiased estimator for entropy! The proof is very short…
Okay, that’s all for today.
I’m back in Singapore now; I learned so much at the Mathematics of Biodiversity conference that there’s no way I’ll be able to tell you all that information. I’ll try to write a few more blog posts, but please be aware that my posts so far give a hopelessly biased and idiosyncratic view of the conference, which would be almost unrecognizable to most of the participants. There are a lot of important themes I haven’t touched on at all… while this business of entropy estimation barely came up: I just find it interesting!
If more of you blogged more, we wouldn’t have this problem.


Over on G+, Adam Liss wrote:
That’s the effect where “unskilled individuals suffer from illusory superiority, mistakenly rating their ability much higher than average.”
It might be related. Suppose perfectly rational agents were doing their best to estimate their skill at some simple task—to keep it really simple, some silly task that you can’t improve at, like guessing which face of a perfectly fair coin will land up the next time you toss it.
Then they could use an unbiased estimator of the probability of success: just count the successes divided by the number of trials. And, you’d find that beginners would have wildly different estimates: for example, somebody who succeeded the first time might guess they were always going to succeed, while someone who failed the first time might guess they’d always fail.
But the average of all these beginners’ estimates would typically almost equal the estimate of someone who’d done the task lots of times.
On the other hand, the Dunning–Kruger effect would suggest that real human beginners will tend to overestimate their chances.
But maybe my simple model here is inappropriate. Maybe somehow our estimate of our abilities is based on some estimate of how much we know about what’ll happen if we do something. That could involve an estimate of entropy, i.e., ignorance. And maybe people tend to use an estimator that’s biased towards underestimating ignorance… and thus overestimating skill. Typically this sort of bias will be bigger with a smaller sample. So yeah.
Wikipedia says of Dunning–Kruger effect, “This bias is attributed to a metacognitive inability of the unskilled to recognize their mistakes.” And that could indeed be a form of underestimating ignorance!
The Hill number for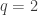 is the inverse of the probability of “collision”. That is, suppose I spot an organism at random in the population and find it is of species
is the inverse of the probability of “collision”. That is, suppose I spot an organism at random in the population and find it is of species  . The probability that doing the same thing a second time will find an organism which is also of species
. The probability that doing the same thing a second time will find an organism which is also of species  is, by definition,
is, by definition,  . Averaging this over all possible values of
. Averaging this over all possible values of  gives
gives 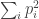 . If this
. If this
is true, then we should be able to get an unbiased estimate of the collision probability by performing the double experiment times and counting how many times the two organisms belong to the same species.
times and counting how many times the two organisms belong to the same species.
(I’ve read that the Gini–Simpson index, which is just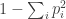 , has an unbiased estimator, so this argument may not be completely wrong.)
, has an unbiased estimator, so this argument may not be completely wrong.)
Jost points to this paper, which I should read but don’t have time to at the moment:
A. Chao and T.-J. Shen (2003), “Nonparametric estimation of Shannon’s index of diversity when there are unseen species in sample” Environmental and Ecological Statistics 10, 4: 429–43. DOI: 10.1023/A:1026096204727.
Hey—great point Blake! I agree with your argument that the two-fold collision probability
should have an unbiased estimator. The same argument should work for the -fold collision probability
-fold collision probability
for all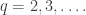 In his talk, Ben Allen pointed out that we can use this
In his talk, Ben Allen pointed out that we can use this  -fold collision probability to compute the Rényi entropy:
-fold collision probability to compute the Rényi entropy:
Unfortunately, since the logarithm function is nonlinear, an unbiased estimator for the -fold collision probability won’t give one for the Rényi entropy—since we can’t push an expectation value through a nonlinear function. So we get an estimator, but not an unbiased one.
-fold collision probability won’t give one for the Rényi entropy—since we can’t push an expectation value through a nonlinear function. So we get an estimator, but not an unbiased one.
Then there’s the Hill number:
which is even more important in biodiversity studies. Again it’s a function of the -fold collision probability. But again, the nonlinearity of this function keeps us from turning an unbiased estimator for the
-fold collision probability. But again, the nonlinearity of this function keeps us from turning an unbiased estimator for the  -fold collision probability into one for the Hill number!
-fold collision probability into one for the Hill number!
But as you note, something nice happens when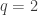 : we get an unbiased estimator for the inverse of the
: we get an unbiased estimator for the inverse of the 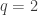 Hill number, which is also called the Gini–Simpson index:
Hill number, which is also called the Gini–Simpson index:
Somehow the case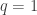 is the most pathological of all from this ‘collision’ viewpoint, while being the nicest of all from other viewpoints.
is the most pathological of all from this ‘collision’ viewpoint, while being the nicest of all from other viewpoints.
Thanks for pointing out that Chao–Shen reference. I’m gonna copy it into the main blog article, since Anne Chao was a speaker at the conference!
I believe your formula for the Gini–Simpson index should be
Also, you’ve a stray ampersand in the Chao–Shen reference in the main post.
It’s interesting how some topics keep recurring in new contexts. I first learned about collision probabilities and Rényi entropies when I was writing my undergraduate thesis, “Relation of Electron Scattering Cross Sections to Drift Measurements in Noble Gases“. It was somewhat incidental to the topic I was supposed to be writing about: the nominal goal of my thesis was to study steady-state flow properties of charge pulses being driven through gases, and I used the Rényi entropy ideas to say a bit about the decay of the transient behaviour on the way to the steady state. I learned about using the Rényi entropies, computed from collision counts, to estimate the Shannon index, because Shang-Keng Ma said a bit about a special case of it in his textbook, Statistical Mechanics (1985). The generalisation I used came from here:
A. Bialas and W. Czyz (2000), “Event by event analysis and entropy of multiparticle systems” Physical Review D 61: 074021 [arXiv:hep-ph/9909209].
They weren’t thinking about charge pulses or species in a rainforest, but rather collisions of atomic nuclei in particle accelerators.
A year or so later, I was studying random geometric graphs to see if they provided a workable “null model” for the 3D structures of proteins. Collision probabilities and Rényi entropies showed up there again: properties of the graphs built by throwing down vertices at random according to some probability distribution depend on Rényi entropies of that distribution. I learned about this from here:
C. Herrmann et al. (2003), “Connectivity distribution of spatial networks” Physical Review E 68: 026128 [arXiv:cond-mat/0302544].
The idea is basically that in all these other contexts, we’ve been talking about “coincidences” or “collisions”, where doing an experiment times gives the same result each time. The analogue in the random-graph scenario is a subset of
times gives the same result each time. The analogue in the random-graph scenario is a subset of  vertices in the graph all connected to one another.
vertices in the graph all connected to one another.
Collisions of ideas… Maybe I only know one or two things and keep seeing them everywhere…
Cool!
People at the biodiversity conference were wondering if they could use collision counts to estimate Shannon entropy, somehow extrapolating Rényi entropy from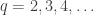 down to
down to  Being a decent pure mathematician I quickly saw that Rényi entropy for probability measures on any given finite set is the kind of function whose values at the point
Being a decent pure mathematician I quickly saw that Rényi entropy for probability measures on any given finite set is the kind of function whose values at the point 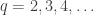 determine its value for all
determine its value for all  But that’s different than getting a practical, robust, method of estimating the Shannon entropy from collision counts. Do you know the state of the art on that?
But that’s different than getting a practical, robust, method of estimating the Shannon entropy from collision counts. Do you know the state of the art on that?
Anne Chao has such a result, and it will lead to the best available estimator of entropy! Stay tuned….
John, I just gave a talk yesterday afternoon here in Barcelona (we all miss you!!!) about estimation of species richness, entropy, and Hill numbers. I suggested a way to “tune” the observed relative abundances (which sum to unity) by noting that their true values must sum to the coverage deficit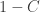 , where
, where  is the Good–Turing coverage, the population share of the species detected in the sample. The coverage deficit can be estimated from the sample as
is the Good–Turing coverage, the population share of the species detected in the sample. The coverage deficit can be estimated from the sample as  where
where 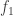 is the number of singletons in the sample and n is sample size.
is the number of singletons in the sample and n is sample size.
Chao and Shen use this method to tune all observed frequencies by a correction factor However, I later realized (and Anne agreed) that this is not quite correct (though it works very well anyway), because the relative uncertainty in the estimate of
However, I later realized (and Anne agreed) that this is not quite correct (though it works very well anyway), because the relative uncertainty in the estimate of  is very small for the large
is very small for the large  but is large for the small
but is large for the small 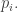 For example, a species represented only once in the sample, with frequency
For example, a species represented only once in the sample, with frequency  could easily have been missed or been found twice; its true frequency in the population might easily be
could easily have been missed or been found twice; its true frequency in the population might easily be  or
or 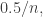 so our relative uncertainty in its value is huge. Contrast this with a species which makes up 50% of the sample. Using the binomial formula for standard deviation, we can show that the precision of this estimate is very high if
so our relative uncertainty in its value is huge. Contrast this with a species which makes up 50% of the sample. Using the binomial formula for standard deviation, we can show that the precision of this estimate is very high if  is large. We don’t have the right to tune that frequency very much. We should tune all frequencies in proportion to their uncertainty. It turns out to be easy to write a simple formula for this.
is large. We don’t have the right to tune that frequency very much. We should tune all frequencies in proportion to their uncertainty. It turns out to be easy to write a simple formula for this.
Tuning only solves half the problem, though. In the case of entropy, the abundance distribution of the unseen species has a largish effect on the value of entropy. That part still needs more work. Hopefully Anne’s innovation will make this unnecessary.
The most recent thing I’ve seen in the tradition I was talking about is this:
A. Bialas, W. Czyz, K. Zalewski (2006), “Measurement of Renyi entropies in multiparticle production: a DO-LIST II” Acta Physica Polonica B 37: 2713–28 [arXiv:hep-ph/0607082].
It is often pointed out to me that I self-select audiences and make assumptions without any awareness, that is, ignorance of what I am doing. Assumptions love small data sets. And yeah, you other scientists, BLOG MORE ABOUT YOUR WORK.
A proof for no unbiased entropy estimator claim is given in Liam Paninski’s neural computation paper. See proposition 8 and proof.
http://www.stat.columbia.edu/~liam/research/abstracts/info_est-nc-abs.html
http://www.stat.columbia.edu/~liam/research/info_est.html
Oh, you added the reference already.
Thanks! I just noticed that Proposition 8 hidden in the appendix a little while ago. I’m confused because it seems to contradict this paper:
• Stephen Montgomery Smith and Thomas Schürmann, Unbiased estimators for entropy and class number.
I’ve updated my blog entry but I’ll probably have to keep updating it after I get a night of sleep. I seem to have underestimated my ignorance.
Actually I’ve seen the same (or very similar) entropy estimator as in the Smith and Schürmann paper you mentioned. And the unbiasedness proof seems to be right, given that we have enough data to observe every symbol at least once (for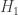 ) while Paninski’s proof assumes a fixed
) while Paninski’s proof assumes a fixed  number of symbols observed. Given infinite data, most entropy estimators are in fact asymptotically unbiased.
number of symbols observed. Given infinite data, most entropy estimators are in fact asymptotically unbiased.
BTW, if the number of symbols (or species) is known, entropy is always bounded by![[0, \log K]](https://s0.wp.com/latex.php?latex=%5B0%2C+%5Clog+K%5D&bg=ffffff&fg=333333&s=0&c=20201002) , so the variance cannot be infinite. When it is unknown, it is a different story.
, so the variance cannot be infinite. When it is unknown, it is a different story.
Thanks! I believe the new version of my blog article gets the facts straight—if you see any actual errors please let me know.
I believe the usual definition of ‘estimator’ requires that you’re able to compute an estimate from samples of data no matter what those samples are. As you note, Smith and Schürmann’s result evades Paninski’s theorem by relaxing this definition of ‘estimator’: their formula only lets you compute an estimate if your samples obey some condition. One might call this a ‘conditional estimator’. I imagine some statisticians have already thought hard about this idea.
samples of data no matter what those samples are. As you note, Smith and Schürmann’s result evades Paninski’s theorem by relaxing this definition of ‘estimator’: their formula only lets you compute an estimate if your samples obey some condition. One might call this a ‘conditional estimator’. I imagine some statisticians have already thought hard about this idea.
I just wanted to add that the paper by myself and Schürmann has a second estimator, where you don’t need to observe every symbol at least once.
But it doesn’t violate Prop 8 of Liam Paninski’s paper. Prop 8 requires that the sample size be given in advance, whereas our estimators have no a priori bound on the sample size.
Interesting, thanks! I’ll have to get back to this subject sometime… I’ve been distracted by other projects.
BTW, we have yet another discrete entropy estimator that doesn’t assume . It’s a nonparametric Bayesian estimator based on a Pitman-Yor process prior.
. It’s a nonparametric Bayesian estimator based on a Pitman-Yor process prior.
Paper: Evan Archer*, Il Memming Park*, Jonathan Pillow. Bayesian Entropy Estimation for Countable Discrete Distributions. arXiv:1302.0328 (2013)
Code available: https://github.com/pillowlab/PYMentropy
Typo alert: $O(1/n^2)$ is missing a “latex”.
Thanks, fixed. I’ve been updating this section near the end of the blog article as I keep learning new things. I’m pretty confused right now—see my reply to ‘memming’ above.
I think there’s a problem in your reasoning. When you say “Say we have a coin that lands up a certain known fraction of the time”, how would we know this? Are you saying that we have a coin that *has landed up* a certain known fraction *in the past*, or do you have some way to know that it *will land up* a certain known fraction of the time *in the future*?
When you use phrases like “the true value” alarm bells go off in my head. You are viewing the probability of heads as a physical property of the coin instead of an information theoretic property of your *knowledge* about the coin.
I thought I’d deleted the word “known” in that sentence, to lessen the confusion. I’ll do it now.
Of course there’s a huge debate on what probabilities actually mean, with subjective Bayesians religiously avoiding phrases like “the true probability”—and for good reasons. It’s an important debate that I’ve spent a lot of time on. I’m actually a subjective Bayesian with mild reservations concerning the possibility that even this position doesn’t seem to get to the bottom of certain issues.
But here I was trying to explain the concept of an unbiased estimator without getting too technical. This is a mathematical issue that largely sidesteps the debate about what probabilities mean. But the problem is that when you talk using words, it’s hard to avoid seeming like you’re taking a position on that debate—and it’s a lot simpler to talk like someone who believes probabilities are an objective feature of reality.
So, in anything I write, you should be able to take phrases like “the true probability distribution” and replace them with “the probability distribution that models Fred’s beliefs” without anything bad happening.
Allowing myself to get more technical, the math goes like this:
Suppose is a probability distribution on a finite set
is a probability distribution on a finite set  . Its entropy is
. Its entropy is
Define an estimator for entropy to be a function
The idea is that given samples from the set $X$, the estimator gives a number
samples from the set $X$, the estimator gives a number  that’s supposed to be an estimate of entropy. If these samples are independent and distributed according to the distribution
that’s supposed to be an estimate of entropy. If these samples are independent and distributed according to the distribution  , the mean estimated entropy will be
, the mean estimated entropy will be
The bias of the estimator is the difference between the mean estimated entropy and the actual entropy of :
:
The estimator is unbiased if the bias is zero for all .
.
Proposition 8 of Paninski’s paper says there exists no unbiased estimator for entropy.
People often think of the ‘true’ probability distribution, whose entropy the estimator is seeking to estimate on the basis of samples distributed according to that distribution. But the math doesn’t care about the word ‘true’, and since the definition of ‘unbiased estimator’ involves a property that’s supposed to hold for all
the ‘true’ probability distribution, whose entropy the estimator is seeking to estimate on the basis of samples distributed according to that distribution. But the math doesn’t care about the word ‘true’, and since the definition of ‘unbiased estimator’ involves a property that’s supposed to hold for all  , we don’t even need any way to specify a particular one.
, we don’t even need any way to specify a particular one.
Typo alert: $X$ is missing its “latex”.
(I had a more substantial comment to make here, but I realised I should explicitly work through the de-Finetti-theorem-related stuff I was thinking about before I started yapping on over it.)
Thanks, I’ll fix this. I’ll be interested to hear what you’re thinking about.
A tangential thought: an “estimator” can be viewed as an example of a “machine learning model” that just happens to have no adjustable parameters at all. But in machine learning it’s a common viewpoint that if you want to reduce (even minimise) the generalisation error when using your model there are terms in the error which can be grouped as “due to bias” and which can be grouped as “due to variance”, and in general it’s trading off these effectively that gives the best performance on new data (see here). Now admittedly for such a “trivial” case it may be possible to do an analysis/optimisation that goes further, but is it possible that neither unbiased nor minimal variance estimators are the most appropriate, but some trade-off between the two that minimises the statistic’s error when applied to finite sets of samples from experiments?
[…] They computed the first-order bias of the information (related to the Miller–Madow correction) […]
[…] It’s all over the place! If you rerun the simulation again and again,you get a different distribution of these values, but they always seem to be >.3 and never settle at 1 (tit-for-tat)! We can measure how diverse the distribution is by the entropy of possible […]