My grad student Mike Stay and I have published this paper:
• John Baez and Mike Stay, Algorithmic thermodynamics, Mathematical Structures in Computer Science 22 (2012), 771–787.
Mike has a masters degree in computer science, and he’s working for Google on a project called Caja. This is a system for letting people write programs in JavaScript while protecting the end users from dirty tricks the programmers might have tried. With me, he’s mainly working on the intersection of computer science and category theory, trying to bring 2-categories into the game. But Mike also knows a lot about algorithmic information theory, a subject with fascinating connections to thermodynamics. So, it was natural for us to work on that too.
Let me just tell you a little about what we did.

Around 1948, the electrical engineer Claude Shannon came up with a mathematical theory of information. Here is a quote that gives a flavor of his thoughts:
The whole point of a message is that it should contain something new.
Say you have a source of information, for example a mysterious radio transmission from an extraterrestrial civilization. Suppose every day you get a signal sort of like this:
How much information are you getting? If the message always looks like this, presumably not much:
Shannon came up with a precise formula for the information. But beware: it’s not really a formula for the information of a particular message. It’s a formula for the average information of a message chosen from some probability distribution. It’s this:
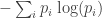
where we sum over all possible messages, and 
So, for example, suppose you keep getting the same message. Then every message has probability 0 except for one message, which has probability 1. Then either 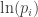
That seems vaguely plausible in the example where every day we get this message:
It may seem less plausible if every day we get this message:
It looks like the aliens are trying to tell us which numbers are prime! 1 is not prime, 2 is, 3 is, 4 is not, 5 is, and so on. Aren’t we getting some information?
Maybe so: this could be considered a defect of Shannon information. On the other hand, you might be willing to admit that if we keep getting the same message every day, the second time we get it we’re not getting any new information. Or, you might not be willing to admit this — it’s actually a subtle issue, and I don’t feel like arguing.
But at the very least, you’ll probably admit that the second time you get the same message, you get less new information than the first time. The third time you get even less, and so on. So it’s quite believable that in the long run, the average amount of new information per message approaches 0 in this case. For Shannon, information means new information.
On the other hand, suppose we are absolutely unable to to predict each new bit we get from the aliens. Suppose our ability to predict the next bit is no better than our ability to predict whether a fair coin comes up heads or tails. Then Shannon’s formula says we are getting the same amount of new information with every bit: namely,
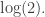
If we take the logarithm using base 2 here, we get 1 — so we say we’re getting one bit of information. If we take it using base e, as physicists prefer, we get 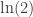
There’s a long road from these reflections to a full justification of the specific formula for Shannon information! To begin marching down that road you can read his original paper, A mathematical theory of communication.
Anyway: it soon became clear that Shannon’s formula was almost the same as the usual formula for “entropy”, which goes back to Josiah Willard Gibbs. Gibbs was actually the first engineer to get a Ph.D. in the United States, back in 1863… but he’s mainly famous as a mathematician, physicist and chemist.

Entropy is a measure of disorder. Suppose we have a box of stuff — solid, liquid, gas, whatever. There are many possible states this stuff can be in: for example, the atoms can be in different positions, and have different velocities. Suppose we only know the probability that the stuff is in any one of the allowed states. If the 
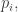

Here 
There’s a wonderful story here, which I don’t have time to tell in detail. The way I wrote Shannon’s formula for information and Gibbs’ formula for entropy, you’d think only a moron would fail to instantly grasp that they’re basically the same. But historically, it took some work.
The appearance of Bolzmann’s constant hints at why. It shows up because people had ideas about entropy, and the closely related concept of temperature, long before they realized the full mathematical meaning of these concepts! So entropy traditionally came in units of “joules/kelvin”, and physicists had a visceral understanding of it. But dividing by Boltzmann’s constant, we can translate that notion of entropy into the modern, more abstract way of thinking of entropy as information!
Henceforth I’ll work in units where 
Closely related to information and entropy is a third concept, which I will call Kolmogorov complexity, though it was developed by many people — including Martin-Löf, Solomonoff, Kolmogorov, Levin, and Chaitin — and it has many names, including descriptive complexity, Kolmogorov-Chaitin complexity, algorithmic entropy, and program-size complexity. You may be intimidated by all these names, but you shouldn’t be: when lots of people keep rediscovering something and giving it new names, it’s usually because this thing is pathetically simple.
So, what is Kolmogorov complexity? It’s a way of measuring the information in a single message rather than a probability distribution of messages. And it’s just the length of the shortest computer program that prints out this message.
I suppose some clarification may be needed here:
1) I’m only talking about programs without any input, that either calculate, print out a message, and halt… or calculate forever and never halt.
2) Of course the length of the shortest program that prints out the desired message depends on the programming language. But there are theorems saying it doesn’t depend “too much” on the language. So don’t worry about it: just pick your favorite language and stick with that.
If you think about it, Kolmogorov complexity is a really nice concept. The Kolmogorov complexity of a string of a million 0’s is a lot less than a million: you can write a short program that says “print a million 0’s”. But the Kolmogov complexity of a highly unpredictable string of a million 0’s and 1’s is about a million: you basically need to include that string in your program and then say “print this string”. Those are the two extremes, but in general the complexity will be somewhere in between.
Various people — the bigshots listed above, and others too — soon realized that Kolmogorov complexity is deeply connected to Shannon information. They have similar properties, but they’re also directly related. It’s another great story, and I urge you to learn it. For that, I recommend:
• Ming Li and Paul Vitanyi, An Introduction to Kolmogorov Complexity and Its Applications, Springer, Berlin, 2008.
To understand the relation a bit better, Mike and I started thinking about probability measures on the set of programs. People had already thought about this — but we thought about it a bit more the way physicists do.
Physicists like to talk about something called a Gibbs ensemble. Suppose we have a set 
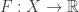
Then the Gibbs ensemble is the probability distribution on 
So, to find the Gibbs ensemble, we need to find a probability distribution 
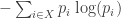
subject to the constraint that
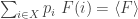
where 
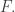
What you really need to know is something more important: why Gibbs invented the Gibbs ensemble! He invented it to solve some puzzles that sound completely impossible at first.
For example, suppose you have a box of stuff and you don’t know which state it’s in. Suppose you only know the expected value of its energy, say 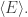
This may sound like an insoluble puzzle: how can we possibly know? But Gibbs proposed an answer! He said, basically: find the probability distribution 
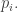
In other words: use the Gibbs ensemble.
Now let’s come back to Kolmogorov complexity.
Imagine randomly picking a program out of a hat. What’s the probability that you pick a certain program? Again, this sounds like an impossible puzzle. But you can answer it if you know the expected value of the length of this program! Then you just use the Gibbs ensemble.
What does this have to do with Kolmogorov complexity? Here I’ll be a bit fuzzy, because the details are in our paper, and I want you to read that.
Suppose we start out with the Gibbs ensemble I just mentioned. In other words, we have a program in a hat, but all you know is the expected value of its length.
But now suppose I tell you the message that this program prints out. Now you know more. How much more information do you have now? The Kolmogorov complexity of the message — that’s how much!
(Well, at least this is correct up to some error bounded by a constant.)
The main fuzzy thing in what I just said is “how much more information do you have?” You see, I’ve explained information, but I haven’t explained “information gain”. Information is a quantity you compute from one probability distribution. Information gain is a quantity you compute from two. More precisely,
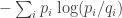
is the information you gain when you thought the probability distribution was 
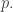
In fact, we argue that information gain is more fundamental than information. This is a Bayesian idea: 
But I digress. To help you remember the story so far, let me repeat myself. Up to a bounded error, the Kolmogorov complexity of a message is the information gained when you start out only knowing the expected length of a program, and then learn which message the program prints out.
But this is just the beginning of the story. We’ve seen how Kolmogorov complexity is related to Gibbs ensembles. Now that we have Gibbs ensembles running around, we can go ahead and do thermodynamics! We can talk about quantities analogous to temperature, pressure, and so on… and all the usual thermodynamic relations hold! We can even take the ideas about steam engines and apply them to programs!
But for that, please read our paper. Here’s the abstract, which says what we really do:
Algorithmic entropy can be seen as a special case of entropy as studied in statistical mechanics. This viewpoint allows us to apply many techniques developed for use in thermodynamics to the subject of algorithmic information theory. In particular, suppose we fix a universal prefix-free Turing machine and let X be the set of programs that halt for this machine. Then we can regard X as a set of ‘microstates’, and treat any function on X as an ‘observable’. For any collection of observables, we can study the Gibbs ensemble that maximizes entropy subject to constraints on expected values of these observables. We illustrate this by taking the log runtime, length, and output of a program as observables analogous to the energy E, volume V and number of molecules N in a container of gas. The conjugate variables of these observables allow us to define quantities which we call the ‘algorithmic temperature’ T, ‘algorithmic pressure’ P and `algorithmic potential’ μ, since they are analogous to the temperature, pressure and chemical potential. We derive an analogue of the fundamental thermodynamic relation dE = T dS – P d V + μ dN, and use it to study thermodynamic cycles analogous to those for heat engines. We also investigate the values of T, P and μ for which the partition function converges. At some points on the boundary of this domain of convergence, the partition function becomes uncomputable. Indeed, at these points the partition function itself has nontrivial algorithmic entropy.


Beautiful intro.
I love this stuff. If I ever became independently wealthy and no longer needed to work for sustenance, comfort, etc., I would spend the rest of my days meditating about this stuff.
Looking forward to reading the paper!
Glad you like the intro! Hope you like the paper!
I’ve been thinking about Gibbs entropy and Shannon information and Kolmogorov complexity ever since I was a student. My college friend Bruce Smith and I learned about information gain (also known as “relative entropy”) from Everett’s thesis on quantum mechanics. Later, my friend Mark Smith (unrelated) did his Ph.D. thesis on computation and thermodynamics, and gave me Reif’s book Fundamentals of Statistical and Thermal Physics. I never took a class on thermodynamics — I learned it from that book! Sometimes you learn things just because they seem interesting, and never plan to work on them… but then, years later, the opportunity comes along.
By the way, some folks here might want to see the earlier discussion of this paper on the n-Category Café. We’ve made a few changes since then…
here is the link to the ZMATH database entry with links to reviews of the first two editions.
I’m not sure I understand the “programs without any input” – part. If you have a message “42” then one of the candidate programs would be
print(“42”)
right? (I mean “simnply print the message”). And the Kolmogorov complexity of a message of n random bits would be n, because “simply print the message” is the simplest program that prints this message, and we silently forget the constant part of the “print” statement. Therefore the “program” consists of key words of the programming language (instructions executed by the machine) and input data.
Epiphany: Is the answer: Candidate programs may not use any input parameters of any kind, so that (e.g. in C) all programs have to look like this:
public static void main(String[] args)
{
// have to ignore all input parameters “args”
args = null;
println(“42”);
}
Yes, that’s the basic idea.
That’s right, Tim. As I’d said:
Since I’m not a computer scientist, I don’t know the difference between this and what you wrote:
But I think you know what I mean now: I’m talking about programs like Turing machines, that don’t receive information from a “user” as they run.
And you’ve got the right idea here:
More precisely, the Kolmogorov complexity of any message of n bits will be bounded above by some function of the form n + c, if we write both our messages and our programs as bit strings. Here c is the “overhead”: the length of the “print” command. And, a message whose Kolmogorov complexity reaches this upper bound can be considered perfectly random.
Interestingly, while it is easy to prove that infinitely many bit strings of length n must have Kolmogorov complexity ≥ n, there are only finitely many bit strings for which you can prove they have this property!
For a long time I considered this the most amazing fact in the universe. It’s possible that I still do: I’ve gotten used to this one, but I haven’t found a more amazing one yet.
Here’s another way to put it: There exists a constant K such that you cannot prove any bit string has Kolmogorov complexity > K, even though infinitely many bit strings have this property.
For a proof, go here.
In a rough hand-waving sort of way, this result says that there’s a certain level of complexity such that we cannot prove anything is more complicated than this, even though lots of things are.
(At least, not without adding extra axioms to our system of logic. The constant K depends on our system of logic! However, to boost the number K by a certain amount N, we need to add N bits of independent axioms to our system of logic. And since these axioms must be independent, we can’t be sure we aren’t making our system inconsistent by adding them.)
Obviously it was a very idiosyncratic problem of mine, here is what I thought:
Let’s say we have a Turing machine.
A “Program” for this machine is simply a finite string of characters. Some of those characters form “key words” that the machine recognizes as a command of its programming language, some of those are simply string literals to the machine, which means it does not know what to do with those and therefore will pass these as parameters to the previously parsed command.
Example:
println(“42”);
This will print ’42’ to the output stream (let’s say the command line).
The characters ‘println(“‘ and ‘”)’ form a command, the characters ’42’ form the input of the command. Now I got confused what “a program without any input” was supposed to be :-)
Here is what I understand now, and a question:
If I get it, you meant “we consider programs only that do not use any additional input parameters”. But couldn’t you equally well say “we consider programs that take input parameters (from the command line or whatever) and define the Kolmogorov complexity as the shortest concatenation of (program + suitable input parameters)” ?
(Suitable input parameters are those of course that make the program print the desired output).
Why do we need to distinguish “program” and “input data” or “input parameters”?
P.S.: Sorry to trip over details in the introduction and not getting any near the real flesh of your paper, once again.
P.P.S.: Did someone turn on spell checking? Thanks!
Sorry, somehow I did not see that part of the answer when I wrote my last comment: Ok, got it!
Good! Perhaps part of the problem is that I’m trying to explain these concepts in everyday language, instead of using jargon like “prefix-free Turing machines”.
If you like statistical mechanics, and you aren’t worn out already, you might enjoy the “real flesh” of our paper, where we bring in concepts like “algorithmic temperature” and “algorithmic pressure”, and prove these obey relations familiar from thermodynamics. That’s the cool part.
Maybe, but last time I did not understand what a “prefix-free Turing machine” is :-)
But this paper of Mike Stay helped me a lot in this regard:
Very Simple Chaitin Machines for Concrete AIT.
Tim wrote:
The definition is in the paper; I bet you just didn’t know why it’s interesting. And it’s actually not very interesting — it’s just a useful trick.
There are lots of ways to list programs. We say such a way is “prefix-free” if the name of one program that halts never appears as the initial part of the name of another one that halts. For example, you can’t have a program that halts named
01010
if you also have one named
01010110
It’s easy to accomplish this: just require that every program ends with a string that means “END”, say for example 1111, and require that this string only shows up at the end of the program. So, you might have a program named
0010101111
but then you can’t have one named
0010101111001111
None of this stuff is very important or profound. It’s just a standard trick for defining a “probability” for programs! Suppose the probability of a program is 2-N when its name has N bits. Then if the naming system is prefix-free, the sum of the probabilities of all programs that halt is ≤ 1. You can imagine flipping a coin until the bit string it generates is the name of a program, and the chance you got that sequence of coin flips is the measure of your program.
(There may also be cases where you keep flipping the coin and never get a name of a program that halts.)
(You’ll note that sometimes I say “program that halts” and sometimes I say “program”. Again, this is just technical baloney.)
Interesting article.
It occurs to me that Kolmogorov complexity could be just as well defined as a length of the shortest description sufficient for the reader to recreate the message.
The problem I see with Kolmogorov complexity (however defined) is that it is highly subjective.
For example let’s say we have a message which consists of two “1” followed by a thousand “0” and another 3 “1”. We can encode it in a pretty short program because we can just say 1000 x “0”.
But now imagine that the same message is analyzed by some primitive alien civilization which doesn’t know multiplication or such software constructs as loops, to them this message will contain much more information because they won’t be able to use the 1000 x “0” trick.
But now imagine that we have information that looks like a thousand completely random bits and all we can figure is to put the message into the program itself.
But the alien civilization may have a single word for this particular sequence since it has some special significance for them. Or perhaps they have discovered some short mathematical formula which produces precisely this sequence.
Or another example let’s say we have a message which consists of first 10^100 digits of pi, we can encode it in a very compact way, as I just did, but we send the message to aliens and since they live in a highly curved space they never developed euclidean geometry and don’t know pi. So for them the message will contain a whole lot of information. This shows that the difference in complexity can be arbitrarily large.
So Kolmogorov complexity is a highly subjective measure and only quantifies complexity with respect to some baseline knowledge like a common language for example.
Quantifying this baseline information is next to impossible however, for example how much information does it take to teach a newborn the first word? And of course it would still be very subjective as newborns differ significantly. Using computers doesn’t help either as those computers have to be made to some specification described in some language.
AI said:
Good point! Trying natural languages would certainly fail, just like you pointed out.
The solution to this paradox was alluded to by JB when he said:
What’s implicit in this statement is that all programming languages running on any machine that we talk about are “equivalent to” a Universal Turing Machine and a smallest universal set of commands. That implies that we do have a universal language that our alien friends could discover for themselves. (“Equivalent” in this context means that the Kolmogorov complexity calculated with regard to any programming language is the same as the one calculated with any other programming language modulo a constant term.)
And, in addition, they could come with a program that calculates (or execute one that we send them) despite the fact that they do not know Euclidean geometry (there are many other ways to discover
(or execute one that we send them) despite the fact that they do not know Euclidean geometry (there are many other ways to discover  in mathematics, it’s almost inevitable :-).
in mathematics, it’s almost inevitable :-).
That’s the theorem John mentioned about it not mattering “too much” which language you pick.
A Turing-complete programming language (or “universal Turing machine”) is one where given any language
(or “universal Turing machine”) is one where given any language  , there exists a constant
, there exists a constant  such that for any program
such that for any program  in the language
in the language  there’s a program
there’s a program  in the language
in the language  such that
such that
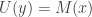
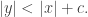
and
One popular way of constructing universal machines is to write a compiler that translates from the language of to the language of
to the language of  . Then
. Then  is the size of the compiler.
is the size of the compiler.
In order to teach a newborn anything, you're assuming that it's already running software that allows it to learn. If you also assume the Church-Turing hypothesis, there's a program for that will simulate the newborn. Whether and to what extent the newborn can simulate
that will simulate the newborn. Whether and to what extent the newborn can simulate  depends on your choice of newborn :)
depends on your choice of newborn :)
Using natural languages would not fail, every calculation doable by a Turing machine can of course be described in natural language, so using Turing machine doesn’t really offer any benefit from what I can see. And whether you use the machine or not you can still can only define complexity up to a constant c as is clear from the theorem provided by Mike (as you can simulate a natural language on a machine).
And besides the subjectivity I am talking about is there even in cases where we are using the same universal Turing machine as a baseline. I was trying to point that out with the pi example but maybe it wasn’t clear. True, one may be able to derive pi in non geometrical so I should have picked something less trivial.
Let’s say we take pi, ignore the first 10^20 digits, rise it to 19th power and then starting from position 73^81 of the resulting decimal sequence we take every X th digit with X starting as 13 and increasing by 1 each time unless X is prime in which case we increase it by 17^(21*X+3). So in this convoluted way we can create an arbitrarily large message which will (I think) look completely random to anyone who doesn’t know the above prescription.
So the Kolmogorov complexity of such a sequence will vary greatly depending on the knowledge of the person calculating it.
Now the reverse problem is also interesting, can every finite message be encoded as some relatively simple sequence of operations on pi?
AFAIK every finite sequence is contained in pi, but if the offset is so large that encoding it takes more place that encoding the message itself then of course it doesn’t help. But what if we consider not only pi but all the possible mathematical operations on it? If the message is long enough then we may very well be able to find a sequence which will be close enough that defining the sequence in terms of constants and adding corrections will take less space then encoding the message in other ways. Of course finding such encoding would be a monumental task.
So I would say that even assuming the same baseline language (and therefore avoiding the constant problem) Kolmogorov complexity is still very subjective and is only really reliable as an upper bound of complexity since for most possible messages it would be impossible to prove that a given program reproducing the message is truly the minimum one.
AI wrote:
No: the Kolmogorov complexity of this message is defined as the length of the shortest program that prints it out. This doesn’t depend on any particular person’s knowledge: it only depends on the programming language.
In other words, the Kolmogorov complexity doesn’t care if you know the shortest program that prints out the given message. So it is not ‘subjective’ in the sense of depending on a person. It is the same for everyone, given the programming language.
But you do have a valid insight, and I think we can phrase it more correctly as follows:
The Kolmogorov complexity of a message can be smaller than you know it is. If I ask you to estimate the Kolmogorov complexity of a message, you can easily provide an upper bound, just by writing any program that prints out that message. (You can always find some program that does this.) But you cannot easily find a lower bound.
You could try: you could go through all programs, one by one, starting with the shortest one, and try to see which ones print out the desired message. You could try to find the shortest one that does the job, and say “this is the Kolmogorov complexity”.
Unfortunately, some programs never halt. If a program keeps chugging away, how can you tell when it will halt? If you can’t tell when it will halt, how can you tell whether it will ever print out the desired message?
In fact there is no computer program which can correctly decide which computers halt and which don’t. The halting problem is undecidable!
So, perhaps it’s not suprising that there is no computer program that will correctly compute the Kolmogorov of any message you hand it!
In the language of theoretical computer science, we say that Kolmogorov complexity is not a computable function of the message. (We can compute it for some messages, but not in a systematic way for all messages.)
I haven’t given a proof of this: just a plausibility argument. For a proof, read this.
So, I would rephrase your intuition as follows:
While Kolmogorov complexity is not subjective (its definition does not depend on a choice of person), it is also not computable (there is no systematic method for us to determine it for all messages).
This makes Kolmogorov complexity less useful than one might wish. It is theoretically fascinating… and I have only just begun to describe some of its shocking properties. But it’s not very ‘practical’.
Luckily there is a variant of Kolmogorov complexity, the Levin complexity, which is computable. It plays an important role in our paper.
“Information is any difference that makes a difference.”
This is referred to as a quote from Shannon. I would be glad to find it in Shannon’s writings but I think it actually comes from Gregory Bateson. For instance, in Bateson, Gregory 1972. Steps to an Ecology of Mind. New York: Ballantine, he says: “A ‘bit’ of information is defined as a difference which makes a difference.” (p. 315), or in Bateson, Gregory 1979. Mind and nature: A necessary unity. New York: Dutton, he says: “Information consists of differences that make a difference.” (p. 110).
Hi, David! If you click on that picture of Shannon above, you’ll see my source for that quote. But it’s not a very scholarly source… and indeed, a quick Google tour suggests the quote may be due to Bateson.
So, I’ll remove that quote, and hope the other one is really due to Shannon. Certainly Shannon had some ideas along these general lines…
I like the quote and wish it was directly from Shannon! The idea that information is essentially about differences is developed in the simple notion of “logical entropy” or “logical information content” of a partition. One can develop an extended analogy between the notion of “elements of a subset” and “distinctions of a partition” where a “distinction” is a pair of elements from distinct blocks of a partition. Then just as finite probability theory was started by taking the probability assigned to a subset as the normalized number of elements, so one can take the logical entropy of a partition on a finite set as the relative (or normalized) number of distinctions of the partition. The logical entropy formula: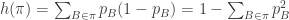 has a long history summarized in my blog at: http://www.mathblog.ellerman.org/2010/02/history-of-the-logical-entropy-formula/ . The longer Synthese paper giving the precise connections with Shannon’s notion of entropy is available at: http://www.ellerman.org/Davids-Stuff/Maths/Counting-Dits-reprint.pdf. Also Rao defined a notion of quadratic entropy which depends on some “distance function” and when one defines the logical distance between two points as being 0 or 1 depending on them being in the same or different blocks of a partition, then the quadratic entropy of the partition is the logical entropy.
has a long history summarized in my blog at: http://www.mathblog.ellerman.org/2010/02/history-of-the-logical-entropy-formula/ . The longer Synthese paper giving the precise connections with Shannon’s notion of entropy is available at: http://www.ellerman.org/Davids-Stuff/Maths/Counting-Dits-reprint.pdf. Also Rao defined a notion of quadratic entropy which depends on some “distance function” and when one defines the logical distance between two points as being 0 or 1 depending on them being in the same or different blocks of a partition, then the quadratic entropy of the partition is the logical entropy.
[…] explained entropy back here, so let me say a word about the uncertainty principle. It’s a limitation on how accurately […]
[…] where we take the logarithm of a positive operator just by taking the log of each of its eigenvalues, while keeping the same eigenvectors. This formula for entropy should remind you of the one that Gibbs and Shannon used — the one I explained a while back. […]
[…] This shouldn’t be surprising: after all, we’re talking about maximum entropy, but entropy is related to information. But I want to gradually make this idea more […]
[…] are my lecture notes for a talk at the CQT. You can think of this as a followup to my first post on this subject, though it overlaps a lot with that previous […]
This is my talk for the Santa Fe Institute workshop on Statistical Mechanics, Information Processing and Biology:
• Algorithmic thermodynamics.
It’s about the link between computation and entropy. I take the idea of a Turing machine for granted, but starting with that I explain recursive functions, the Church-Turing thesis, Kolomogorov complexity, the relation between Kolmogorov complexity and Shannon entropy, the uncomputability of Kolmogorov complexity, the ‘complexity barrier’, Levin’s computable version of complexity, and finally my work with Mike Stay on algorithmic thermodynamics.
For more details, read our paper:
• John Baez and Mike Stay, Algorithmic thermodynamics, Math. Struct. Comp. Sci. 22 (2012), 771-787.
or these blog articles:
• Algorithmic thermodynamics (part 1).
• Algorithmic thermodynamics (part 2).
They all emphasize slightly different aspects!