About 10,800 BC, something dramatic happened.
The last glacial period seemed to be ending quite nicely, things had warmed up a lot — but then, suddenly, the temperature in Europe dropped about 7 °C! In Greenland, it dropped about twice that much. In England it got so cold that glaciers started forming! In the Netherlands, in winter, temperatures regularly fell below -20 °C. Throughout much of Europe trees retreated, replaced by alpine landscapes, and tundra. The climate was affected as far as Syria, where drought punished the ancient settlement of Abu Hurerya. But it doesn’t seem to have been a world-wide event.
This cold spell lasted for about 1300 years. And then, just as suddenly as it began, it ended! Around 9,500 BC, the temperature in Europe bounced back.
This episode is called the Younger Dryas, after a certain wildflower that enjoys cold weather, whose pollen is common in this period.
What caused the Younger Dryas? Could it happen again? An event like this could wreak havoc, so it’s important to know. Alas, as so often in science, the answer to these questions is "we’re not sure, but…."
We’re not sure, but the most popular theory is that a huge lake in Canada, formed by melting glaciers, broke its icy banks and flooded out into the Saint Lawrence River. This lake is called Lake Agassiz. At its maximum, it held more water than all lakes in the world now put together:
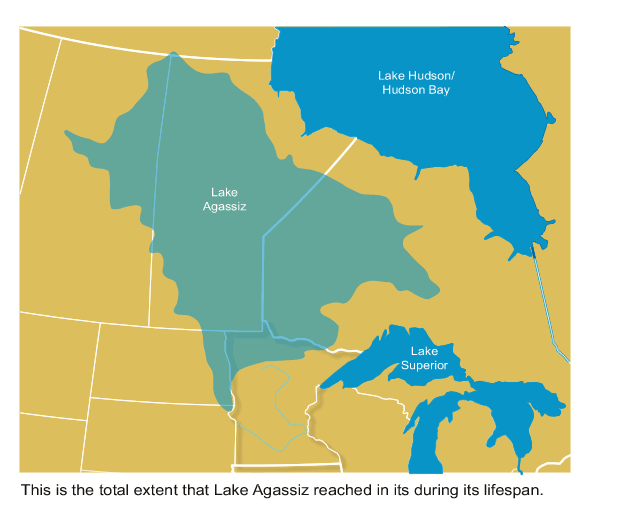
In a massive torrent lasting for years, the water from this lake rushed out to the Labrador Sea. By floating atop the denser salt water, this fresh water blocked a major current that flows in the Altantic: the Atlantic Meridional Overturning Circulation, or AMOC. This current brings warm water north and helps keep northern Europe warm. So, northern Europe was plunged into a deep freeze!
That’s the theory, anyway.
Could something like this happen again? There are no glacial lakes waiting to burst their banks, but the concentration of fresh water in the northern Atlantic has been increasing, and ocean temperatures are changing too, so some scientists are concerned. The problem is, we don’t really know what it takes to shut down the Atlantic Meridional Overturning Circulation!
To make progress on this kind of question, we need a lot of insight, but we also need some mathematical models. And that’s what Nathan Urban will tell us about now. First we’ll talk in general about climate models, Bayesian reasoning, and Monte Carlo methods. We’ll even talk about the general problem of using simple models to study complex phenomena. And then he’ll walk us step by step through the particular model that he and a coauthor have used to study this question: will the AMOC run amok?
Sorry, I couldn’t resist that. It’s not so much "running amok" that the AMOC might do, it’s more like "fizzling out". But accuracy should never stand in the way of a good pun.
On with the show:
JB: Welcome back! Last time we were talking about the new work you’re starting at Princeton. You said you’re interested in the assessment of climate policy in the presence of uncertainties and "learning" – where new facts come along that revise our understanding of what’s going on. Could you say a bit about your methodology? Or, if you’re not far enough along on this work, maybe you could talk about the methodology of some other paper in this line of research.
NU: To continue the direction of discussion, I’ll respond by talking about the methodology of a few papers along the lines of what I hope to work on here at Princeton, rather than about my past papers on uncertainty quantification. They are Keller and McInerney on learning rates:
• Klaus Keller and David McInerney, The dynamics of learning about a climate threshold, Climate Dynamics 30 (2008), 321-332.
Keller and coauthors on learning and economic policy:
• Klaus Keller, Benjamin M. Bolkerb and David F. Bradford, Uncertain climate thresholds and optimal economic growth, Journal of Environmental Economics and Management 48 (2004), 723-741.
and Oppenheimer et al. on "negative" learning (what happens when science converges to the wrong answer):
• Michael Oppenheimer, Brian C. O’Neill and Mort Webster, Negative learning, Climatic Change 89 (2008), 155-172.
The general theme of this kind of work is to statistically compare a climate model to observed data in order to understand what model behavior is allowed by existing data constraints. Then, having quantified the range of possibilities, plug this uncertainty analysis into an economic-climate model (or "integrated assessment model"), and have it determine the economically "optimal" course of action.
So: start with a climate model. There is a hierarchy of such models, ranging from simple impulse-response or "box" models to complex atmosphere-ocean general circulation models. I often use the simple models, because they’re computationally efficient and it is therefore feasible to explore their full range of uncertainties. I’m moving toward more complex models, which requires fancier statistics to extract information from a limited set of time-consuming simulations.
Given a model, then apply a Monte Carlo analysis of its parameter space. Climate models cannot simulate the entire Earth from first principles. They have to make approximations, and those approximations involve free parameters whose values must be fit to data (or calculated from specialized models). For example, a simple model cannot explicitly describe all the possible feedback interactions that are present in the climate system. It might lump them all together into a single, tunable "climate sensitivity" parameter. The Monte Carlo analysis runs the model many thousands of times at different parameter settings, and then compares the model output to past data in order to see which parameter settings are plausible and which are not. I use Bayesian statistical inference, in combination with Markov chain Monte Carlo, to quantify the degree of "plausibility" (i.e., probability) of each parameter setting.
With probability weights for the model’s parameter settings, it is now possible to weight the probability of possible future outcomes predicted by the model. This describes, conditional on the model and data used, the uncertainty about the future climate.
JB: Okay. I think I roughly understand this. But you’re using jargon that may cause some readers’ eyes to glaze over. And that would be unfortunate, because this jargon is necessary to talk about some very cool ideas. So, I’d like to ask what some phrases mean, and beg you to explain them in ways that everyone can understand.
To help out — and maybe give our readers the pleasure of watching me flounder around — I’ll provide my own quick attempts at explanation. Then you can say how close I came to understanding you.
First of all, what’s an "impulse-response model"? When I think of "impulse response" I think of, say, tapping on a wineglass and listening to the ringing sound it makes, or delivering a pulse of voltage to an electrical circuit and watching what it does. And the mathematician in me knows that this kind of situation can be modelled using certain familiar kinds of math. But you might be applying that math to climate change: for example, how the atmosphere responds when you pump some carbon dioxide into it. Is that about right?
NU: Yes. (Physics readers will know "impulse response" as "Green’s functions", by the way).
The idea is that you have a complicated computer model of a physical system whose dynamics you want to represent as a simple model, for computational convenience. In my case, I’m working with a computer model of the carbon cycle which takes CO2 emissions as input and predicts how much CO2 is left in the air after natural sources and sinks operate on what’s there. It’s possible to explicitly model most of the relevant physical and biogeochemical processes, but it takes a long time for such a computer simulation to run. Too long to explore how it behaves under many different conditions, which is what I want to do.
How do you build a simple model that acts like a more complicated one? One way is to study the complex model’s "impulse response" — in this case, how it behaves in response to an instantaneous "pulse" of carbon to the atmosphere. In general, the CO2 in the atmosphere will suddenly jump up, and then gradually relax back toward its original concentration as natural sinks remove some of that carbon from the atmosphere. The curve showing how the concentration decreases over time is the "impulse response". You derive it by telling your complex computer simulation that a big pulse of carbon was added to the air, and recording what it predicts will happen to CO2 over time.
The trick in impulse response theory is to treat an arbitrary CO2 emissions trajectory as the sum of a bunch of impulses of different sizes, one right after another. So, if emissions are 1, 3, and 7 units of carbon in years 1, 2, and 3, then you can think of that as a 1-unit pulse of carbon in year one, plus a 3-unit pulse in year 2, plus a 7-unit pulse in year 3.
The crucial assumption you make at this point is that you can treat the response of the complex model to this series of impulses as the sum of the "impulse response" curve that you worked out for a single pulse. Therefore, just by running the model in response to a single unit pulse, you can work out what the model would predict for any emissions trajectory, by adding up its response to a bunch of individual pulses. The impulse response model makes its prediction by summing up lots of copies of the impulse repsonse curve, with different sizes and at different times. (Techincally, this is a convolution of the impulse response curve, or Green’s function, with the emissions trajectory curve.)
JB: Okay. Next, what’s a "box model"? I had to look that up, and after some floundering around I bumped into a Wikipedia article that mentioned "black box models" and "white box models".
A black box model is where you’ve got a system, and all you pay attention to is its input and output — in other words, what you do to it, and what it does to you, not what’s going on "inside". A white box model, or "glass box model", lets you see what’s going on inside but not directly tinker with it, except via your input.
Is this at all close? I don’t feel very confident that I’ve understood what a "box model" is.
NU: No, box models are the sorts of things you find in "systems dynamics" theory, where you have "stocks" of a substance and "flows" of it in and out. In the carbon cycle, the "boxes" (or stocks) could be "carbon stored in wood", "carbon stored in soil", "carbon stored in the surface ocean", etc. The flows are the sources and sinks of carbon. In an ocean model, boxes could be "the heat stored in the North Atlantic", "the heat stored in the deep ocean", etc., and flows of heat between them.
Box models are a way of spatially averaging over a lot of processes that are too complicated or time-consuming to treat in detail. They’re another way of producing simplified models from more complex ones, like impulse response theory, but without the linearity assumption. For example, one could replace a three dimensional circulation model of the ocean with a couple of "big boxes of water connected by pipes". Of course, you have to then verify that your simplified model is a "good enough" representation of whatever aspect of the more complex model that you’re interested in.
JB: Okay, sure — I know a bit about these "box models", but not that name. In fact the engineers who use "bond graphs" to depict complex physical systems made of interacting parts like to emphasize the analogy between electrical circuits and hydraulic systems with water flowing through pipes. So I think box models fit into the bond graph formalism pretty nicely. I’ll have to think about that more.
Anyway: next you mentioned taking a model and doing a "Monte Carlo analysis of its parameter space". This time you explained what you meant, but I’ll still go over it.
Any model has a bunch of adjustable parameters in it, for example the "climate sensitivity", which in a simple model just means how much warmer it gets per doubling of atmospheric carbon dioxide. We can think of these adjustable parameters as knobs we’re allowed to turn. The problem is that we don’t know the best settings of these knobs! And even worse, there are lots of allowed settings.
In a Monte Carlo analysis we randomly turn these knobs to some setting, run our model, and see how well it does — presumably by comparing its results to the "right answer" in some situation where we already know the right answer. Then we keep repeating this process. We turn the knobs again and again, and accumulate information, and try to use this to guess what the right knob settings are.
More precisely: we try to guess the probability that the correct knob settings lie within any given range! We don’t try to guess their one "true" setting, because we can’t be sure what that is, and it would be silly to pretend otherwise. So instead, we work out probabilities.
Is this roughly right?
NU: Yes, that’s right.
JB: Okay. That was the rough version of the story. But then you said something a lot more specific. You say you "use Bayesian statistical inference, in combination with Markov chain Monte Carlo, to quantify the degree of "plausibility" (or probability) of each parameter setting."
So, I’ve got a couple more questions. What’s "Markov chain Monte Carlo"? I guess it’s some specific way of turning those knobs over and over again.
NU: Yes. For physicists, it’s a "random walk" way of turning the knobs: you start out at the current knob settings, and tweak each one just a little bit away from where they currently are. In the most common Markov chain Monte Carlo (MCMC) algorithm, if the new setting takes you to a more plausible setting of the knobs, you keep that setting. If the new setting produces an outcome that is less plausible, then you might keep the new setting (with a likelihood proportional to how much less plausible the new setting is), or you might stay at the existing setting and try again with a new tweaking. The MCMC algorithm is designed so that the sequence of knob settings produced will sample randomly from the probability distribution you’re interested in.
JB: And what’s "Bayesian statistical inference"? I’m sorry, I know this subject deserves a semester-long graduate course. But like a bad science journalist, I will ask you to distill it down to a few sentences! Sometime I’ll do a whole series of This Week’s Finds about statistical inference, but not now.
NU: I can distill it to one sentence: in this context, it’s a branch of statistics which allows you to assign probabilities to different settings of model parameters, based on how well those settings cause the model to reproduce the observed data.
The more common "frequentist" approach to statistics doesn’t allow you to assign probabilities to model parameters. It has a different take on probability. As a Bayesian, you assume the observed data is known and talk about probabilities of hypotheses (here, model parameters). As a frequentist, you assume the hypothesis is known (hypothetically), and talk about probabilities of data that could result from it. They differ fundamentally in what you treat as known (data, or hypothesis) and what probabilities are applied to (hypothesis, or data).
JB: Okay, and one final question: sometimes you say "plausibility" and sometimes you say "probability". Are you trying to distinguish these, or say they’re the same?
NU: I am using "probability" as a technical term which quantifies how "plausible" a hypothesis is. Maybe I should just stick to "probability".
JB: Great. Thanks for suffering through that dissection of what you said.
I think I can summarize, in a sloppy way, as follows. You take a model with a bunch of adjustable knobs, and you use some data to guess the probability that the right settings of these knobs lie within any given range. Then, you can use this model to make predictions. But these predictions are only probabilistic.
Okay, then what?
NU: This is the basic uncertainty analysis. There are several things that one can do with it. One is to look at learning rates. You can generate "hypothetical data" that we might observe in the future, by taking a model prediction and adding some "observation noise" to it. (This presumes that the model is perfect, which is not the case, but it represents a lower bound on uncertainty.) Then feed the hypothetical data back into the uncertainty analysis to calculate how much our uncertainty in the future could be reduced as a result of "observing" this "new" data. See Keller and McInerney for an example.
Another thing to do is decision making under uncertainty. For this, you need an economic integrated assessment model (or some other kind of policy model). Such a model typically has a simple description of the world economy connected to a simple description of the global climate: the world population and the economy grow at a certain rate which is tied to the energy sector, policies to reduce fossil carbon emissions have economic costs, fossil carbon emissions influence the climate, and climate change has economic costs. Different models are more or less explicit about these components (is the economy treated as a global aggregate or broken up into regional economies, how realistic is the climate model, how detailed is the energy sector model, etc.)
If you feed some policy (a course of emissions reductions over time) into such a model, it will calculate the implied emissions pathway and emissions abatement costs, as well as the implied climate change and economic damages. The net costs or benefits of this policy can be compared with a "business as usual" scenario with no emissions reductions. The net benefit is converted from "dollars" to "utility" (accounting for things like the concept that a dollar is worth more to a poor person than a rich one), and some discounting factor is applied (to downweight the value of future utility relative to present). This gives "the (discounted) utility of the proposed policy".
So far this has not taken uncertainty into account. In reality, we’re not sure what kind of climate change will result from a given emissions trajectory. (There is also economic uncertainty, such as how much it really costs to reduce emissions, but I’ll concentrate on the climate uncertainty.) The uncertainty analysis I’ve described can give probability weights to different climate change scenarios. You can then take a weighted average over all these scenarios to compute the "expected" utility of a proposed policy.
Finally, you optimize over all possible abatement policies to find the one that has the maximum expected discounted utility. See Keller et al. for a simple conceptual example of this applied to a learning scenario, and this book for a deeper discussion:
• William Nordhaus, A Question of Balance, Yale U. Press, New Haven, 2008.
It is now possible to start elaborating on this theme. For instance, in the future learning problem, you can modify the "hypothetical data" to deviate from what your climate model predicts, in order to consider what would happen if the model is wrong and we observe something "unexpected". Then you can put that into an integrated assessment model to study how much being wrong would cost us, and how fast we need to learn that we’re wrong in order to change course, policy-wise. See that paper by Oppenheimer et al. for an example.
JB: Thanks for that tour of ideas! It sounds fascinating, important, and complex.
Now I’d like to move on to talking about a specific paper of yours. It’s this one:
• Nathan Urban and Klaus Keller, Probabilistic hindcasts and projections of the coupled climate, carbon cycle, and Atlantic meridional overturning circulation system: A Bayesian fusion of century-scale observations with a simple model, Tellus A 62 (2010), 737-750.
Before I ask you about the paper, let me start with something far more basic: what the heck is the "Atlantic meridional overturning circulation" or "AMOC"?
I know it has something to do with ocean currents, and how warm water moves north near the surface of the Atlantic and then gets cold, plunges down, and goes back south. Isn’t this related to the "Gulf Stream", that warm current that supposedly keeps Europe warmer than it otherwise would be?
NU: Your first sentence pretty much sums up the basic dynamics: the warm water from the tropics cools in the North Atlantic, sinks (because it’s colder and denser), and returns south as deep water. As the water cools, the heat it releases to the atmosphere warms the region.
This is the "overturning circulation". But it’s not synonymous with the Gulf Stream. The Gulf Stream is a mostly wind-driven phenomenon, not a density driven current. The "AMOC" has both wind driven and density driven components; the latter is sometimes referred to as the "thermohaline circulation" (THC), since both heat and salinity are involved. I haven’t gotten into salinity yet, but it also influences the density structure of the ocean, and you can read Stefan Rahmstorf’s review articles for more (read the parts on non-linear behavior):
• Stefan Rahmstorf, The thermohaline ocean circulation: a brief fact sheet.
• Stefan Rahmstorf, Thermohaline ocean circulation, in Encyclopedia of Quaternary Sciences, edited by S. A. Elias, Elsevier, Amsterdam 2006.

JB: Next, why are people worrying about the AMOC? I know some scientists have argued that shortly after the last ice age, the AMOC stalled out due to lots of fresh water from Lake Agassiz, a huge lake that used to exist in what’s now Canada, formed by melting glaciers. The idea, I think, was that this event temporarily killed the Gulf Stream and made temperatures in Europe drop enormously.
Do most people believe that story these days?
NU: You’re speaking of the "Younger Dryas" abrupt cooling event around 11 to 13 thousand years ago. The theory is that a large pulse of fresh water from Lake Agassiz lessened the salinity in the Atlantic and made it harder for water to sink, thus shutting down down the overturning circulation and decreasing its release of heat in the North Atlantic. This is still a popular theory, but geologists have had trouble tracing the path of a sufficiently large supply of fresh water, at the right place, and the right time, to shut down the AMOC. There was a paper earlier this year claiming to have finally done this:
• Julian B. Murton, Mark D. Bateman, Scott R. Dallimore, James T. Teller and Zhirong Yang, Identification of Younger Dryas outburst flood path from Lake Agassiz to the Arctic Ocean, Nature 464 (2010), 740-743.
but I haven’t read it yet.
The worry is that this could happen again — not because of a giant lake draining into the Atlantic, but because of warming (and the resulting changes in precipitation) altering the thermal and salinity structure of the ocean. It is believed that the resulting shutdown of the AMOC will cause the North Atlantic region to cool, but there is still debate over what it would take to cause it to shut down. It’s also debated whether this is one of the climate "tipping points" that people talk about — whether a certain amount of warming would trigger a shutdown, and whether that shutdown would be "irreversible" (or difficult to reverse) or "abrupt".
Cooling Europe may not be a bad thing in a warming world. In fact, in a warming world, Europe might not actually cool in response to an AMOC shutdown; it might just warm more slowly. The problem is if the cooling is abrupt (and hard to adapt to), or prolonged (permamently shifting climate patterns relative to the rest of the world). Perhaps worse than the direct temperature change could be the impacts on agriculture or ocean ecosystems, resulting from major reorganizations of regional precipitation or ocean circulation patterns.
JB: So, part of your paper consists of modelling the AMOC and how it interacts with the climate and the carbon cycle. Let’s go through this step by step.
First: how do you model the climate? You say you use "the DOECLIM physical climate component of the ACC2 model, which is an energy balance model of the atmosphere coupled to a one-dimensional diffusive ocean model". I guess these are well-known ideas in your world. But I don’t even know what the acronyms stand for! Could you walk us through these ideas in a gentle way?
NU: Don’t worry about the acronyms; they’re just names people have given to particular models.
The ACC2 model is a computer model of both the climate and the carbon cycle. The climate part of our model is called DOECLIM, which I’ve used to replace the original climate component of ACC2. An "energy balance model" is the simplest possible climate model, and is a form of "box model" that I mentioned above. It treats the Earth as a big heat sink that you dump energy into (e.g., by adding greenhouse gases). Given the laws of thermodynamics, you can compute how much temperature change you get from a given amount of heat input.
This energy balance model of the atmosphere is "zero dimensional", which means that it treats the Earth as a featureless sphere, and doesn’t attempt to keep track of how heat flows or temperature changes at different locations. There is no three dimensional circulation of the atmosphere or anything like that. The atmosphere is just a "lump of heat-absorbing material".
The atmospheric "box of heat" is connected to two other boxes, which are land and ocean. In DOECLIM, "land" is just another featureless lump of material, with a different heat capacity than air. The "ocean" is more complicated. Instead of a uniform box of water with a single temperature, the ocean is "one dimensional", meaning that it has depth, and temperature is allowed to vary with depth. Heat penetrates from the surface into the deep ocean by a diffusion process, which is intended to mimic the actual circulation-driven penetration of heat into the ocean. It’s worth treating the ocean in more detail since oceans are the Earth’s major heat sink, and therefore control how quickly the planet can change temperature.
The three parameters in the DOECLIM model which we treat as uncertain are the climate (temperature) sensitivity to CO2, the vertical mixing rate of heat into the ocean, and the strength of the "aerosol indirect effect" (what kind of cooling effect industrial aerosols in the atmosphere create due to their influence on cloud behavior).
JB: Okay, that’s clear enough. But at this point I have to raise an issue about models in general. As you know, a lot of climate skeptics like to complain about the fallibility of models. They would surely become even more skeptical upon hearing that you’re treating the Earth as a featureless sphere with same temperature throughout at any given time — and treating the temperature of ocean water as depending only on the depth, not the location. Why are you simplifying things so much? How could your results possibly be relevant to the real world?
Of course, as a mathematical physicist, I know the appeal of simple models. I also know the appeal of reducing the number of dimensions. I spent plenty of time studying quantum gravity in the wholly unrealistic case of a universe with one less dimension than our real world! Reducing the number of dimensions makes the math a lot simpler. And simplified models give us a lot of insight which — with luck — we can draw upon when tackling the really hard real-world problems. But we have to be careful: they can also lead us astray.
How do you think about results obtained from simplified climate models? Are they just mathematical warmup exercises? That would be fine — I have no problem with that, as long as we’re clear about it. Or are you hoping that they give approximately correct answers?
NU: I use simple models because they’re fast and it’s easier to expose and explore their assumptions. My attitude toward simple models is a little of both the points of view you suggest: partly proof of concept, but also hopefully approximately correct, for the questions I’m asking. Let me first argue for the latter perspective.
If you’re using a zero dimensional model, you can really only hope to answer "zero dimensional questions", i.e. about the globally averaged climate. Once you’ve simplified your question by averaging over a lot of the complexity of the data, you can hope that a simple model can reproduce the remaining dynamics. But you shouldn’t just hope. When using simple models, it’s important to test the predictions of their components against more complex models and against observed data.
You can show, for example, that as far as global average surface temperature is concerned, even simpler energy balance models than DOECLIM (e.g., without a 1D ocean) can do a decent job of reproducing the behavior of more complex models. See, e.g.:
• Isaac M. Held, Michael Winton, Ken Takahashi, Thomas Delworth, Fanrong Zeng and Geoffrey K. Vallis, Probing the fast and slow components of global warming by returning abruptly to preindustrial forcing, Journal of Climate 23 (2010), 2418-2427.
for a recent study. The differences between complex models can be captured merely by retuning the "effective parameters" of the simple model. For example, many of the complexities of different feedback effects can be captured by a tunable climate sensitivity parameter in the simple model, representing the total feedback. By turning this sensitivity "knob" in the simple model, you can get it to behave like complex models which have different feedbacks in them.
There is a long history in climate science of using simple models as "mechanistic emulators" of more complex models. The idea is to put just enough physics into the simple model to get it to reproduce some specific averaged behavior of the complex model, but no more. The classic "mechanistic emulator" used by the International Panel on Climate Change is called MAGICC. BERN-CC is another model frequently used by the IPCC for carbon cycle scenario analysis — that is, converting CO2 emissions scenarios to atmospheric CO2 concentrations. A simple model that people can play around with themselves on the Web may be found here:
• Ben Matthews, Chooseclimate.
Obviously a simple model cannot reproduce all the behavior of a more complex model. But if you can provide evidence that it reproduces the behavior you’re interested in for a particular problem, it is arguably at least as "approximately correct" as the more complex model you validate it against, for that specific problem. (Whether the more complex model is an "approximately correct" representation of the real world is a separate question!)
In fact, simple models are arguably more useful than more complex ones for certain applications. The problem with complex models is, well, their complexity. They make a lot of assumptions, and it’s hard to test all of them. Simpler models make fewer assumptions, so you can test more of them, and look at the sensitivity of your conclusions to your assumptions.
If I take all the complex models used by the IPCC, they will have a range of different climate sensitivities. But what if the actual climate sensitivity is above or below that range, because all the complex models have limitations? I can’t easily explore that possibility in a complex model, because "climate sensitivity" isn’t a knob I can turn. It’s an emergent property of many different physical processes. If I want to change the model’s climate sensitivity, I might have to rewrite the cloud physics module to obey different dynamical equations, or something complicated like that — and I still won’t be able to produce a specific sensitivity. But in a simple model, "climate sensitivity" sensitivity is a "knob", and I can turn it to any desired value above, below, or within the IPCC range to see what happens.
After that defense of simple models, there are obviously large caveats. Even if you can show that a simple model can reproduce the behavior of a more complex one, you can only test it under a limited range of assumptions about model parameters, forcings, etc. It’s possible to push a simple model too far, into a regime where it stops reproducing what a more complex model would do. Simple models can also neglect relevant feedbacks and other processes. For example, in the model I use, global warming can shut down the AMOC, but changes in the AMOC don’t feed back to cool the global temperature. But the cooling from an AMOC weakening should itself slow further AMOC weakening due to global warming. The AMOC model we use is designed to partly compensate for the lack of explicit feedback of ocean heat transport on the temperature forcing, but it’s still an approximation.
In our paper we discuss what we think are the most important caveats of our simple analysis. Ultimately we need to be able to do this sort of analysis with more complex models as well, to see how robust our conclusions are to model complexity and structural assumptions. I am working in that direction now, but the complexities involved might be the subject of another interview!
JB: I’d be very happy to do another interview with you. But you’re probably eager to finish this one first. So we should march on.
But I can’t resist one more comment. You say that models even simpler than DOECLIM can emulate the behavior of more complex models. And then you add, parenthetically, "whether the more complex model is an ‘approximately correct’ representation of the real world is a separate question!" But I think that latter question is the one that ordinary people find most urgent. They won’t be reassured to know that simple models do a good job of mimicking more complicated models. They want to know how well these models mimic reality!
But maybe we’ll get to that when we talk about the Monte Carlo Markov chain procedure and how you use that to estimate the probability that the "knobs" (that is, parameters) in your model are set correctly? Presumably in that process we learn a bit about how well the model matches real-world data?
If so, we can go on talking about the model now, and come back to this point in due time.
NU: The model’s ability to represent the real world is the most important question. But it’s not one I can hope to fully answer with a simple model. In general, you won’t expect a model to exactly reproduce the data. Partly this is due to model imperfections, but partly it’s due to random "natural variability" in the system. (And also, of course, to measurement error.) Natural variability is usually related to chaotic or otherwise unpredictable atmosphere-ocean interactions, e.g. at the scale of weather events, El Niño, etc. Even a perfect model can’t be expected to predict those. With a simple model it’s really hard to tell how much of the discrepancy between model and data is due to model structural flaws, and how much is attributable to expected "random fluctuations", because simple models are too simple to generate their own "natural variability".
To really judge how well models are doing, you have to use a complex model and see how much of the discrepancy can be accounted for by the natural variability it predicts. You also have to get into a lot of detail about the quality of the observations, which means looking at spatial patterns and not just global averages. This is the sort of thing done in model validation studies, "detection and attribution" studies, and observation system papers. But it’s beyond the scope of our paper. That’s why I said the best I can do is to use simple models that perform as well as complex models for limited problems. They will of course suffer any limitations of the complex models to which they’re tuned, and if you want to read about those, you should read those modeling papers.
As far as what I can do with a simple model, yes, the Bayesian probability calculation using MCMC is a form of data-model comparison, in that it gives higher weight to model parameter settings that fit the data better. But it’s not exactly a form of "model checking", because Bayesian probability weighting is a relative procedure. It will be quite happy to assign high probability to parameter settings that fit the data terribly, as long as they still fit better than all the other parameter settings. A Bayesian probability isn’t an absolute measure of model quality, and so it can’t be used to check models. This is where classical statistical measures of "goodness of fit" can be helpful. For a philosophical discussion, see:
• Andrew Gelman and Cosma Rohilla Shalizi, Philosophy and the practice of Bayesian statistics, available as arXiv:1006.3868.
That being said, you do learn about model fit during the MCMC procedure in its attempt to sample highly probable parameter settings. When you get to the best fitting parameters, you look at the difference between the model fit and the observations to get an idea of what the "residual error" is — that is, everything that your model wasn’t able to predict.
I should add that complex models disagree more about the strength of the AMOC than they do about more commonly discussed climate variables, such as surface temperature. This can been seen in Figure 10.15 of the IPCC AR4 WG1 report: there is a cluster of models that all tend to agree with the observed AMOC strength, but there are also some models that don’t. Some of those that don’t are known to have relatively poor physical modeling of the overturning circulation, so this is to be expected (i.e., the figure looks like a worse indictment of the models than it really is). But there is still disagreement between some of the "higher quality" models. Part of the problem is that we have poor historical observations of the AMOC, so it’s sometimes hard to tell what needs fixing in the models.
Since the complex models don’t all agree about the current state of the AMOC, one can (and should) question using a simple AMOC model which has been tuned to a particular complex model. Other complex models will predict something altogether different. (And in fact, the model that our simple model was tuned to is also simpler than the IPCC AR4 models.) In our analysis we try to get around this model uncertainty by including some tunable parameters that control both the initial strength of the AMOC and how quickly it weakens. By altering those parameters, we try to span the range of possible outcomes predicted by complex models, allowing the parameters to take on whatever range of values is compatible with the (noisy) observations. This, at a minimum, leads to significant uncertainty in what the AMOC will do.
I’m okay with the idea of uncertainty — that is, after all, what my research is about. But ultimately, even projections with wide error bars still have to be taken with a grain of salt, if the most advanced models still don’t entirely agree on simple questions like the current strength of the AMOC.
JB: Okay, thanks. Clearly the question of how well your model matches reality is vastly more complicated than what you started out trying to tell me: namely, what your model is. Let’s get back to that.
To recap, your model consists of three interacting parts: a model of the climate, a model of the carbon cycle, and a model of the Atlantic meridional overturning circulation (or "AMOC"). The climate model, called "DOECLIM", itself consists of three interacting parts:

• the "land" (modeled as a "box of heat"),
• the "atmosphere" (modeled as a "box of heat")
• the "ocean" (modelled as a one-dimensional object, so that temperature varies with depth)
Next: how do you model the carbon cycle?
NU: We use a model called NICCS (nonlinear impulse-response model of the coupled carbon-cycle climate system). This model started out as an impulse response model, but because of nonlinearities in the carbon cycle, it was augmented by some box model components. NICCS takes fossil carbon emissions to the air as input, and calculates how that carbon ends up being partitioned between the atmosphere, land (vegetation and soil), and ocean.
For the ocean, it has an impulse response model of the vertical advective/diffusive transport of carbon in the ocean. This is supplemented by a differential equation that models nonlinear ocean carbonate buffering chemistry. It doesn’t have any explicit treatment of ocean biology. For the terrestrial biosphere, it has a box model of the carbon cycle. There are four boxes, each containing some amount of carbon. They are "woody vegetation", "leafy vegetation", "detritus" (decomposing organic matter), and "humus" (more stable organic soil carbon). The box model has some equations describing how quickly carbon gets transported between these boxes (or back to the atmosphere).

In addition to carbon emissions, both the land and ocean modules take global temperature as an input. (So, there should be a red arrow pointing to the "ocean" too — this is a mistake in the figure.) This is because there are temperature-dependent feedbacks in the carbon cycle. In the ocean, temperature determines how readily CO2 will dissolve in water. On land, temperature influences how quickly organic matter in soil decays ("heterotrophic respiration"). There are also purely carbon cycle feedbacks, such as the buffering chemistry mentioned above, and also "CO2 fertilization", which quantifies how plants can grow better under elevated levels of atmospheric CO2.
The NICCS model also originally contained an impulse response model of the climate (temperature as a function of CO2), but we removed that and replaced it with DOECLIM. The NICCS model itself is tuned to reproduce the behavior of a more complex Earth system model. The key three uncertain parameters treated in our analysis control the soil respiration temperature feedback, the CO2 fertilization feedback, and the vertical mixing rate of carbon into the ocean.
JB: Okay. Finally, how do you model the AMOC?
NU: This is another box model. There is a classic 1961 paper by Stommel:
• Henry Stommel, Thermohaline convection with two stable regimes of flow, Tellus 2 (1961), 224-230.
which models the overturning circulation using two boxes of water, one representing water at high latitudes and one at low latitudes. The boxes contain heat and salt. Together, temperature and salinity determine water density, and density differences drive the flow of water between boxes.
It has been shown that such box models can have interesting nonlinear dynamics, exhibiting both hysteresis and threshold behavior. Hysteresis means that if you warm the climate and then cool it back down to its original temperature, the AMOC doesn’t return to its original state. Threshold behavior means that the system exhibits multiple stable states (such as an ocean circulation with or without overturning), and you can pass a "tipping point" beyond which the system flips from one stable equilibrium to another. Ultimately, this kind of dynamics means that it can be hard to return the AMOC to its historic state if it shuts down from anthropogenic climate change.
The extent to which the real AMOC exhibits hysteresis and threshold behavior remains an open question. The model we use in our paper is a box model that has this kind of nonlinearity in it:
• Kirsten Zickfeld, Thomas Slawig and Stefan Rahmstorf, A low-order model for the response of the Atlantic thermohaline circulation to climate change, Ocean Dynamics 54 (2004), 8-26.
Instead of Stommel’s two boxes, this model uses four boxes:

It has three surface water boxes (north, south, and tropics), and one box for an underlying pool of deep water. Each box has its own temperature and salinity, and flow is driven by density gradients between them. The boxes have their own "relaxation temperatures" which the box tries to restore itself to upon perturbation; these parameters are set in a way that attempts to compensate for a lack of explicit feedback on global temperature. The model’s parameters are tuned to match the output of an intermediate complexity climate model.
The input to the model is a change in global temperature (temperature anomaly). This is rescaled to produce different temperature anomalies over each of the three surface boxes (accounting for the fact that different latitudes are expected to warm at different rates). There are similar scalings to determine how much freshwater input, from both precipitation changes and meltwater, is expected in each of the surface boxes due to a temperature change.
The main uncertain parameter is the "hydrological sensitivity" of the North Atlantic surface box, controlling how much freshwater goes into that region in a warming scenario. This is the main effect by which the AMOC can weaken. Actually, anything that changes the density of water alters the AMOC, so the overturning can weaken due to salinity changes from freshwater input, or from direct temperature changes in the surface waters. However, the former is more uncertain than the latter, so we focus on freshwater in our uncertainty analysis.
JB: Great! I see you’re emphasizing the uncertain parameters; we’ll talk more later about how you estimate these parameters, though you’ve already sort of sketched the idea.
So: you’ve described to me the three components of your model: the climate, the carbon cycle and the Atlantic meridional overturning current (AMOC). I guess to complete the description of your model, you should say how these components interact — right?
NU: Right. There is a two-way coupling between the climate module (DOECLIM) and the carbon cycle module (NICCS). The global temperature from the climate module is fed into the carbon cycle module to predict temperature-dependent feedbacks. The atmospheric CO2 predicted by the carbon cycle module is fed into the climate module to predict temperature from its greenhouse effect. There is a one-way coupling between the climate module and the AMOC module. Global temperature alters the overturning circulation, but changes in the AMOC do not themselves alter global temperature:
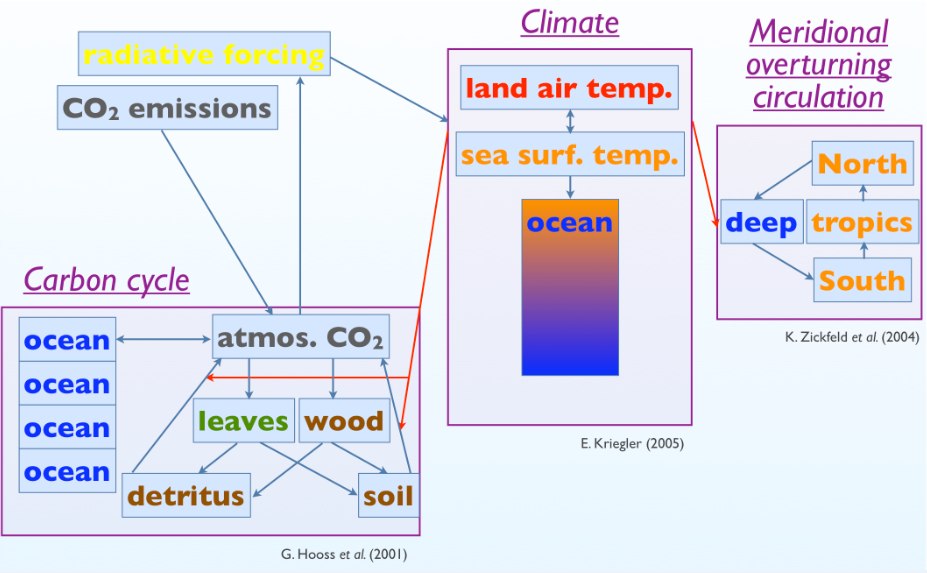
There is no coupling between the AMOC module and the carbon cycle module, although there technically should be: both the overturning circulation and the uptake of carbon by the oceans depend on ocean vertical mixing processes. Similarly, the climate and carbon cycle modules have their own independent parameters controlling the vertical mixing of heat and carbon, respectively, in the ocean. In reality these mixing rates are related to each other. In this sense, the modules are not fully coupled, insofar as they have independent representations of physical processes that are not really independent of each other. This is discussed in our caveats.
JB: There’s one other thing that’s puzzling me. The climate model treats the "ocean" as a single entity whose temperature varies with depth but not location. The AMOC model involves four "boxes" of water: north, south, tropical, and deep ocean water, each with its own temperature. That seems a bit schizophrenic, if you know what I mean. How are these temperatures related in your model?
You say "there is a one-way coupling between the climate module and the AMOC module." Does the ocean temperature in the climate model affect the temperatures of the four boxes of water in the AMOC model? And if so, how?
NU: The surface temperature in the climate model affects the temperatures of the individual surface boxes in the AMOC model. The climate model works only with globally averaged temperature. To convert a (change in) global temperature to (changes in) the temperatures of the surface boxes of the AMOC model, there is a "pattern scaling" coefficient which converts global temperature (anomaly) to temperature (anomaly) in a particular box.
That is, if the climate model predicts a 1 degree warming globally, that might be more or less than 1 °C of warming in the north Atlantic, tropics, etc. For example, we generally expect to see "polar amplification" where the high northern latitudes warm more quickly than the global average. These latitudinal scaling coefficients are derived from the output of a more complex climate model under a particular warming scenario, and are assumed to be constant (independent of warming scenario).
The temperature from the climate model which is fed into the AMOC model is the global (land+ocean) average surface temperature, not the DOECLIM sea surface temperature alone. This is because the pattern scaling coefficients in the AMOC model were derived relative to global temperature, not sea surface temperature.
JB: Okay. That’s a bit complicated, but I guess some sort consistency is built in, which prevents the climate model and the AMOC model from disagreeing about the ocean temperature. That’s what I was worrying about.
Thanks for leading us through this model. I think this level of detail is just enough to get a sense for how it works. And that I know roughly what your model is, I’m eager to see how you used it and what results you got!
But I’m afraid many of our readers may be nearing the saturation point. After all, I’ve been talking with you for days, with plenty of time to mull it over, while they will probably read this interview in one solid blast! So, I think we should quit here and continue in the next episode.
So, everyone: I’m afraid you’ll just have to wait, clutching your chair in suspense, for the answer to the big question: will the AMOC get turned off, or not? Or really: how likely is such an event, according to this simple model?
…we’re entering dangerous territory and provoking an ornery beast. Our climate system has proven that it can do very strange things. – Wallace S. Broecker


{kind=link}
Now that’s a cliffhanger!
:-)
Some random comments and questions after a first quick glance:
The difference is very important in engineering for testing, if you develop a gadget and test it yourself, that’s a white box test.
Your test design is inevitably biased, because you know how the gadget works.
Therefore sometimes a dedicated test team is employed to do the black box testing.
How many free parameters do the models have that we talk about? (Here is a quote of an experimental physicist about the standard model of particle physics: “With three free parameters you can match an elephant.”)
I’ve added it to the [[Recommended reading]] page, but it still needs a summary :-)
Are Gulf Stream and AMOC completely different phenomena or is the Gulf Stream the “wind-driven” part of the AMOC?
Educated guess: the vanishing of the AMOC would have widely different effects on different parts of Europe, I’d say that Italy would not change much while Iceland would become inhabitable…
Is the switching off of the AMOC a tipping point that is a transition from one stable local equilibrium point to another one, in the model? If yes: How do different equilibrium points emerge? Do you use some kind of potential that has multiple local minima?
Editorial side note:
Maybe it would be useful to insert sub headlines?
Parameters: I don’t know if you’re talking about box models, or big AOGCMs. The box models I work with typically have a dozen or two variables in them, some of them better known than others. Of the ones that are both uncertain and highly influential on the output of the model, maybe half a dozen.
AOGCMs have many, many more parameters … probably thousands. Again, far fewer of them are “uncertain and influential”. On the other hand, they also have much more data to tune and validate against (full spacetime fields of many different observables, rather than a few aggregated outputs).
I don’t think it’s possible to just tweak them all and fit any data set, as you can with a high order polynomial or whatever. There are always model structural limitations which will cause the model to fail in particular ways no matter what the parameters are set to. In some ways the existence of model limitations is worrying, since they can’t fully reproduce everything we observe. On the other hand, they are comforting reminders that physics actually constrains the outputs of these models — they can’t generate arbitrary output.
Gulf Stream: I don’t know if I would call the Gulf Stream part of the AMOC. It’s a wind driven current. The density driven thermohaline part also contributes to the Gulf Stream (maybe 20%, according to Rahmstorf).
Regionality: certainly a shutdown will affect different parts of Europe in different ways. See Stocker (2002 for maps of the regional temperature anomaly simulated by some climate models.
Bistability: yes, there are multiple equilibria in the AMOC model (“on” and “off” states). See the Stocker paper for a description of how they arise in a simple case.
Thanks, that is helpful!
Both, actually, my knowledge of climate models is, well, incomplete, and I don’t know much about any of them :-)
It would be wiser if I shut up and try to digest the provided material :-) but anyway, here is the naive follow up question: The data you mention is available now, but certainly not for the last thousands of years. I implicitly assumed that climate models are always about long time trends of at least thousand of years, that seems to be wrong. What is the time scale of AOGCMs?
AOGCMs are typically run on time scales of a few centuries, although a few of them have been run on scales of thousands of years. It’s not really computationally possible to run them for longer. The most ambitious attempt I know of so far is an 8,000 year run in Liu et al. (2009).
There is paleodata available for such time scales. The data for the last thousand years isn’t terribly useful because the signal-to-noise ratio is small and the forcings are uncertain. Glacial-interglacial transitions have bigger signals and somewhat better understood causes, so those are better constraints on models. Such paleoconstraints so far have not been used too much for GCM development.
Given that a PC today has more computing power than a super computer 10 years ago (at least that’s what I think) I’m a little bit surprised: What are, roughly, the underlying data of such an computation (what processors, how many processors, RAM, runtime, programming language)?
My gut feeling was that my PC may be fast enough, but that it would take me years to understand and program a useful model, so that the problem is really BMAS (between monitor and seat).
BTW, the monte carlo markov chain, as described in the interview, is used to explore the parameter space, correct? When you simulate noise, i.e. a stochastic process, for a time series produced by a model, do you use white noise only, or are there models with colored noise, too?
BTW: this keeps reminding me of stochastic resonance.
I’ll try and put what Nathan said in high-level terms about MCMC in the interview in technical terms that may make things clearer. (I’m sure Nathan can point expand on this or point to a reference if necessary.)
The idea is that you’ve got a space and a probability distribution
and a probability distribution  that is proportional to some computable function
that is proportional to some computable function  . What you want to do is get some number of samples according to the distribution
. What you want to do is get some number of samples according to the distribution  . The problem is that for multidimensional and complicated
. The problem is that for multidimensional and complicated  it’s not clear how to sample from that in any direct way. So you basically say “if I do a random walk starting from some chosen initial state
it’s not clear how to sample from that in any direct way. So you basically say “if I do a random walk starting from some chosen initial state  , moving to neighbouring states proportional to
, moving to neighbouring states proportional to  , then after a big, big number of steps my probability of being at a point
, then after a big, big number of steps my probability of being at a point 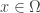 will tend to be
will tend to be  regardless of what
regardless of what  I chose“. (There are technical requirements I skip here.) Although there are clever things you can do to walk “more efficiently” you unavoidably have to do a lot of random steps to have the position forget the original state (“burn-in”). This desire to be a “correct” sample from
I chose“. (There are technical requirements I skip here.) Although there are clever things you can do to walk “more efficiently” you unavoidably have to do a lot of random steps to have the position forget the original state (“burn-in”). This desire to be a “correct” sample from  , rather than say the maximum of
, rather than say the maximum of  , is what requires the long run-time.
, is what requires the long run-time.
Tim,
The models are in Fortran. I just went to a talk today where the speaker mentioned that the GCM he was using simulates about 25 model years per realtime day, on 8 cores, at roughly 3 x 2 degree spatial resolution. So that’s hundreds of days to simulate thousands of model years.
You can of course increase cores (to extent that you can parallelize your code), but there are many people wanting to run model experiments and so you tend to partition cores to different runs, rather than using all your cores for very long runs.
Also, models tend to “drift” over time and very long integrations can expose numerical problems with the code, which can require even higher resolution or a change in the numerical solver.
Yes.
Many people have used white noise for parameter estimation, but this is a mistake in my opinion, because the actual climate noise is quite red. I have used AR(1) processes. That’s decent for global temperature, somewhat less so for global ocean heat. A truly stochastic model can generate its own noise (but then it’s hard to do the parameter estimation if you don’t have a closed-form solution for its spectrum).
Stochastic resonance of course emerged out of climate science … but I’ve never run into it in my own work.
Tim wrote:
Yeah, that’s wrong for AOGCMs. For obvious reasons, people are desperately interested in knowing what will happen in the next 100 years or so. So, the biggest, most computationally intensive, and (we hope!) most accurate computer models have typically been deployed to tackle this question. These are the AOGCMs, or atmospheric / oceanic general circulation models, which attempt to simulate the motion of the world’s ocean and atmosphere in detail. And that takes a lot of computation.
It may be obvious to you, but I want it to be clear to everyone: these models are enormously more complicated than the simple model Nathan was describing in this interview!
Nathan’s model was deliberately chosen to be simple so he could run it thousands of times, probably on a PC, as part of the ‘Markov chain Monte Carlo’ procedure where he explores the result of changing the parameters in this model — ‘turning the knobs’, as I put it.
Nathan wrote:
Tim replied:
Your surprise here makes me very surprised, which is why I felt the need to add some elementary comments — not so much for you, as for other people reading this! Everyone needs to learn about this stuff: the fate of our planet hangs in the balance.
First of all, we can’t even predict the weather extremely well for more than a week, thanks in part to the chaotic behavior of fluid flows. So, any sort of climate model is faced with a lot of difficult choices. People creating these models must try to separate out the fine-grained unpredictable details of weather from the coarse-grained, hopefully more predictable aspects of climate. And this is a very hard problem. It requires a lot of careful thought — but also, the more computer power we have, the better!
So, if people had any sort of model which could simulate the Earth’s atmosphere and oceans for thousands of years on a PC with some level of precision, then they would instantly want to build a bigger, better model with more precision, to see how it compares to their previous model.
So it shouldn’t be surprising that the biggest, best models — the AOGCMs — eat up all the computer power we have, just to look ahead a couple hundred years.
Later I’ll interview Tim Palmer, and he’ll tell us how climate scientists could really use a dedicated supercomputer in the petaflop range.
JB said:
I’d like to know more about the kind of complexity, and – related question – if models fail, for what reasons.
There are several aspects of complexity with regard to software systems (off the top of my head):
1) LOC (lines of codes): An operating system has an enormous amount of code, because it has to handle a lot of tasks and situations (some complex, most of them rather trivial).
2) Some 3D-engines of computer games have methods that are very hard to understand, because they perform nontrivial computations that are optimized for performance (and therefore not for readability),
3) Simulations of lattice QCD are hard to understand because QCD is hard to understand :-) That is, just to understand what the code does takes some years of training as a physicist.
4) Weather forecast code may be hard to understand (I don’t know anything about this topic though), because the layer of abstraction is hard to understand (there are real phenomena and there are equations and data flows in the code, how do they match and why does it work or is supposed to work?).
5) A software system may be complex because it manages a huge amount (terabyte, say) of data (customer database of a big company),
6) A software system may need a huge amount of CPU time, but the task itself is rather trivial – for example a Monte Carlo integration of an integral in very very high dimensions, I’d guess that a lot of CPU time is needed to generate random numbers, while the generator itself is rather simple.
Now my gut feeling is that the complexity of climate models is in item 4, and the hard question in the design of climate science models is which effects have to be included, at what level of abstraction, and which effects have to be ignored. More CPU time won’t help if the model is flawed.
Nathan said:
Here is the link to the explanation of AR on Wikipedia:
autoregressive random process.
Tim wrote:
I hope Nathan answers your questions, since he knows infinitely more about this than I do. Your first question is a lot easier than the second one!
Some AOGCMs are described here, at the Canadian Centre for Climate Modelling and Analysis. Let’s take the 4th-generation model — the newest, fanciest one. Let me try to describe it, based on what I’m reading from the website. Since I’m not an expert, I may make lots of mistakes:
The atmosphere and ocean are described in two separate modules.
The atmosphere is sliced into 35 layers, going from 50 feet above the ground to the point where the troposphere hits the stratosphere. These layers are not equally spaced. The air in each layer is described by a “63 wave triangularly truncated spherical harmonic expansion” — some kind of funky variant of spherical harmonics, I guess.
Hows is the dynamics of the atmosphere described? These are the updates since the last model:
“The radiative transfer scheme in The Third Generation Atmospheric General Circulation Model has been replaced by a new scheme that includes a new correlated-k distribution model and a more general treatment of radiative transfer in cloudy atmospheres using the McICAmethodology. In conjunction with other parameterizations, the radiative transfer scheme accounts for the direct and indirect radiative effects of aerosols. A prognostic bulk aerosol scheme with a full sulphur cycle, along with organic and black carbon, mineral dust, and sea salt has been added. A new shallow convection scheme has been added to the model. Approaches to local and non-local turbulent mixing by Abdella and McFarlane and McFarlane et al. were improved for AGCM4. AGCM4 has two strategies to deal with the artifacts of spectral advection (Gibbs effect)…”
In short, there’s a lot of stuff to understand here — even if we already understood AGCM3!
What about the ocean?
Vertically the ocean is chopped into 40 layers, not equally spaced. Horizontally it’s chopped into a grid spacings approximately 1.41 degrees in longitude and 0.94 degrees in latitude.
As for the ocean dynamics:
“Vertical mixing is via the K-profile parameterization scheme of Large et al., to which is added an energetically constrained, bottom intensified vertical tracer diffusivity to represent effects of tidally-induced mixing; the latter is computed in a manner similar to Simmons et al. Horizontal friction is treated using the anisotropic viscosity parameterization of Large et al. Isoneutral mixing is according to the parameterization of Gent and McWilliams as described in Gent et al., with layer thickness diffusion coefficients optionally determined according to the formulation in Gnanadesikan et al. The model incorporates the equation of state for seawater of McDougall et al. In treating shortwave penetration, a fraction 0.45 of the incident radiation is photosynthetically active and penetrates according to an attenuation coefficient which is the sum of a clear-water term and a term that varies linearly with chlorophyll concentration as in Lima and Doney. Chlorophyll concentrations in the physical version of the model are specified from a seasonally varying climatology constructed from SeaWiFS observations, and in the ESM version are a prognostic variable. The remaining (red) incident shortwave flux is absorbed in the topmost layer. The Strait of Gibraltar, Hudson Strait and pathways through the Canadian Archipelago that are unresolved are treated by mixing water properties instantaneously between the nearest ocean cells bordering intervening land. To prevent excessive accumulation of freshwater adjacent to river mouths, half of runoff from each modelled river is distributed across the AGCM cell (encompassing six OGCM cells) into which the river drains, with the remaining half distributed among all adjoining ocean-coupled AGCM cells.”
Then there’s the coupling between the atmospheric model (AGCM) and the ocean model (OGCM)…
… but I think you get the general flavor. There’s a lot of data and the program must be complicated too, consisting of a lot of modules that address different specific physical effects. Each one of these effects takes time and expertise to understand well.
None of these effects seems as mindblowingly abstract and unfamiliar as, say, quantum chromodynamics. But the math required for a good description of these effects is a lot more complicated! For example, if you’re talking to a reasonably smart person at a party, it’s easier to explain the idea of chlorophyll concentrations in the ocean depending on the season, than to explain Wilson loops in lattice gauge theory. But it’s a lot easier to describe the second one mathematically!
Tim,
I’m not an AOGCM modeler myself and haven’t really looked at GCM code very much.
About complexity: people often assume that the complexity lies in the numerical solver (or “dynamical core”): the finite-grid implementation of the Navier-Stokes equations, laws of thermodynamics, and whatnot. My understanding is that this is not the case.
Dynamical cores get more complicated when you start coupling components together (e.g., the atmosphere model to the ocean model), and you have to get the equations to mesh and compute stable answers.
A lot (most?) of the scientific complexity is in the “parametrizations”, which are approximations of physics which either we don’t know very well, or don’t have the spatial/time resolution to express directly in the model.
For example, if the ocean resolution isn’t high enough, the ocean model won’t generate its own turbulent eddies. But eddies are important in mixing heat and other tracers (salinity, carbon, etc.) around the ocean. If your model doesn’t have eddies, you have to add explicit approximations to the fluid dynamics equations (e.g., extra advection/diffusion terms) to simulate their effects. This means “changing the laws of physics” in a way that is carefully crafted to emulate the behavior of physics that should be in the models, but can’t be, for one reason or another.
Another fluid dynamics example of such tweaking is “hyperviscosity”, which means artificially increasing the viscosity of the fluid equations to mimic the dissipation of enstrophy by unresolved sub-grid scale processes. There are related “closure schemes”, which are basically ways of keeping the resolved macro physics consistent with the unresolved micro physics.
Another classic example is cloud parameterizations. GCMs currently have a horizontal grid resolution of about 100 kilometers. That is far too large to resolve individual clouds (which can be less than a kilometer). But clouds have a huge impact on the Earth’s radiation/moisture balance. So you have to put in “parametrizations” which approximate what clouds would be doing over a 100 km domain. It’s kind of like “mean field theory” in physics, where you have to put in the right “average” behavior of microphysics in order to reproduce the correct large-scale behavior of the system.
Parametrizations can be very complicated and hard to get right. They are also why climate scientists feel a need for all the resolution and computing power they can get. Unfortunately, for reasons of numerical stability — the CFL instability, treatment of gravity waves (not gravitational waves!), etc. — the computational requirements go up fast with resolution. You have to increase the time step resolution if you want to increase the spatial resolution. I Googled a random paper which suggests that in one common solver (a spectral domain solver), increasing the spatial resolution in one dimension (e.g. latitude) causes CPU time to go up with the cube of spatial resolution. I’m not sure if I’m reading that right, but I do know that CPU time increases faster than linearly with resolution, which is why people are talking about petascale computation.
Returning to model complexity: in addition to the atmospheric-ocean code, AOGCMs are now becoming “Earth System Models” with dynamic simulations of the biogeochemsistry (terrestrial vegetation, plankton, etc.). This adds a lot of scientific complexity too, because it’s not just a simple core of Navier-Stokes equations. Now you have ecosystem dynamics to deal with.
Then, in addition to all the “scientific” numerical code, there is a lot of pure “software engineering” code. Code to glue modules together, code to load in and output data (e.g., checkpointing by saving “restart files” with system state), code to swap in different assumptions about forcings, parameterizations, solvers, etc.
As you can probably tell by now, these models are among the most complex, if not the most complex, scientific simulations in existence.
There is a computer scientist professor at Toronto, Steve Easterbrook (publications), who studies climate models from a software engineering perspective. You might like his blog, Serendipity.
You might also like to view the source code for an actual AOGCM. One such model, NASA GISS ModelE, has an online code browser, and you could download all the source if you really wanted to. Another downloadable GCM is the NCAR Community Earth System Model (CESM) (code here). And a “simple” GCM you can download and run on your PC is EdGCM, an educational version of the NASA GISS Model II used by James Hansen and others in the 1980s.
Nathan wrote:
Never heard that one before, which proves that I need to learn some hydrodynamics…
Yes! That one should be added to the “blogroll” of Azimuth.
1. In looking at all these models which require parameterization from experimental data, theory, and sometimes a mix of both, is anyone doing any sort of error analysis?
I’ve been looking around the net a bit, and I’m seeing all sorts of interesting things about SST data collection:
and
and that’s for the period between 1850 and the present, although fragmentary records mostly by the Royal Navy go back to the 1750s.
If the adjustments taken (or assumed) are as large as the resultant effect, then how do you determine whether an effect exists or not? And what’s the error in measurement, and the accuracy and precision; all of these are quantities that must be known, it seems, or else you can’t really make any prediction, one way or another, about what happens to the AMOC.
2. We’re also talking about apples and oranges here: the influx of a large volume of freshwater into seawater over the course of less than a year, perhaps a lot less than a year, from Lake Agassiz 10000 years ago vs. the influx of smaller (by orders of magnitude) volumes of freshwater into seawater over a far longer timescale. In the first case, it’s a one-time shock event, in the second, a steady flow which might allow for quicker equilibration and attenuation of any effects.
3. The model used by Zickfeld et al assume four boxes, of which three are surface boxes, and one of which is a deep water box, and the boxes are not very well characterized as compared to the phenomena they are supposedly modeling. It’s difficult for me to see how you could draw *any* conclusion from these model runs, much less state that the AMOC might be overturned. Here’s a paper you might want to have a look at: Wallcraft, Alan J., A. Birol Kara, Harley E. Hurlburt, Peter A. Rochford, 2003: The NRL Layered Global Ocean Model (NLOM) with an Embedded Mixed Layer Submodel: Formulation and Tuning*. J. Atmos. Oceanic Technol., 20, 1601–1615. doi: 10.1175/1520-0426(2003)0202.0.CO;2
“A bulk-type (modified Kraus–Turner) mixed layer model that is embedded within the Naval Research Laboratory (NRL) Layered Ocean Model (NLOM) is introduced. It is an independent submodel loosely coupled to NLOM’s dynamical core, requiring only near-surface currents, the temperature just below the mixed layer, and an estimate of the stable mixed layer depth. Coupling is achieved by explicitly distributing atmospheric forcing across the mixed layer (which can span multiple dynamic layers), and by making the heat flux and thermal expansion of seawater dependent upon the mixed layer model’s sea surface temperature (SST). An advantage of this approach is that the relative independence of the dynamical solution from the mixed layer allows the initial state for simulations with the mixed layer to be defined from existing near-global model simulations spun up from rest without a mixed layer (requiring many hundreds of model years). The goal is to use the mixed layer model in near-global multidecadal simulations with realistic 6-hourly atmospheric forcing from operational weather center archives.”
streamfortyseven,
1. That’s kind of a broad question. Yes, of course there are people who do error analysis. As in any body of literature, some are more complete than others. With respect to historic surface temperature, Brohan et al. (2006) is one example.
Whether an effect “exists or not” in the presence of adjustments depends on the size of the uncertainty in the bias adjustment relative to the size of the signal, not the size of the adjustment.
As for prediction, I tend not to directly adopt published error estimates in my statistical calibrations. They’re only one part of the total uncertainty, anyway (the others include natural variability and model error). My approach has been to compute empirical estimates of the total residual error between the observed data and the models (due to all of these processes), sometimes using the published error estimates as lower bounds on my priors if the estimated discrepancy seems too small.
2. Yes, I know that the Younger Dryas was very different from how the AMOC is likely to change in the future. Our paper doesn’t predict another such abrupt event, although it does predict collapses under some circumstances.
3. I devoted a significant fraction of the above interview to explaining when I think simple models are useful for prediction. (Short answer: when they can be shown to reproduce the dynamics of more complex models with respect to the variables of interest.) I’m not sure what the relevance is of the paper you cite to this discussion.
streamfortyseven wrote:
True.
Just to be clear, Nathan didn’t claim a possible shutdown of the AMOC in the next century would be similar to the Younger Dryas. He’s also not using data from the Younger Dryas episode to calibrate his model.
I mainly brought up the Younger Dryas because it’s an example of abrupt climate change due (perhaps) to the AMOC shutting down, and its dramatic nature helps concentrate the audience’s attention.
So some of the good questions you’re raising include:
1) What would a plausible scenario for a near-term shutdown of the AMOC look like? What have scientists written about this?
2) When Nathan runs his model and the AMOC shuts down (yes, I believe sometimes it does), what does that look like? What makes it happen?
3) How well does 2) match 1)?
I’ll probably ask Nathan some questions like this in his next interview.
The following is off topic, strictly speaking, sorry, but I’d like to know more about this story:
Recently I read about lactose intolerance: Some Archeologists (reference needed, I don’t have one at hand) say that lactose tolerance developed in a culture called Linear Pottery culture in south east Europe and spread suddenly – during a very short period of 300 years – from there through Germany and France to the Atlantic coast. Genetic analysis of ancient bones shows, that the hunter-gatherers did not adapt and did not breed with the lactose tolerant people from the linear pottery culture, but became extinct. This sudden “invasion” was attributed to a sudden temperature increase that considerably weakened the hunter-gatherers, but favored the lactose tolerant farmers.
It would seem that the date of this event (7000 or 6000 BC, I’m not sure) does not match that of the younger dryas, or am I mistaken?
That’s all I know about this story, further recommended reading would be welcome.
I’m hoping Nathan will answer your on-topic questions, because he can do a better job than me. So I’ll answer your off-topic questions, which are also interesting.
According to the Wikipedia article you cite, the Linear Pottery Culture flourished 5500–4500 BC near the middle Danube, the upper and middle Elbe, and the upper and middle Rhine. According to a Scientific American article quoted below, the spread of lactose tolerance may have started around 5500 BC. This is quite a bit later than the 6000-7000 BC date you mention, and vastly later than the Younger Dryas episode, which occurred around 10800-9500 BC.
Here’s what the Scientific American has to say:
By the way, if you’re interested in the relation between changing climates and changing human culture, I really recommend Brian Fagan’s book The Long Summer, which starts near the end of the last glacial period, 18000 years ago.
If you’re looking for exciting climate events around 5500 BC, you can go back to 5600 BC, when rising waters in the Mediterranean may have poured into the ‘Euxine Lake’, which was below sea level, and formed what is now the Black Sea. Manmade structures have been found 100 meters below the current water level. Some believe the water level rose in a catastrophic way. Some even blame various famous flood myths on this event!
You can read more about this in The Long Summer. We have really been lucky to have a quite stable climate for the last 2000 years.
A correspondent writes:
Interesting. I can easily imagine that cold, hungry Northern Europeans would want to drink cows’ milk regardless of whether it had much vitamin D in it. They would be very happy just for the fat, which causes us so many problems now.
Drifting further off-topic, here is another intriguing example of a possible link between “lifestyle”, survival and environment. Scientific American published an article ca. twenty years ago (Google tells me the author was Bert L. Vallee, “Alcohol in the Western World”, June 1998) about how the widespread use of fermented beverages in all traditional cultures (as well as of boiled beverages such as tea) can be understood as an adaptation to a world in which running water was more often than not a vector for disease. It seems that until the late 19th century many people in Europe spent their lives more or less permanently inebriated! The temperance movement only became effective when modern sanitation methods made water and other non-alcoholic beverages safe for drinking.
Far-fetched? Perhaps not. Until a generation ago, it was still possible to hear elders from the more backward rural areas in the South Europe attribute their advanced age to the wholesome habit of tippling, drinking nothing else! This strange attitude to alcoholism makes sense if we recall that when public health officials started monitoring the quality of water from public fountains in smaller towns and villages (as late as the 1940’s), many were found to be unsuited to human consumption (mostly due to percolates from tilled fields and livestock entering the water table). Several centuries ago the problem can have been only worse.
This must be the event that I was looking for, these rising waters could have erased the fishermen on the coast that blocked the way of the pottery people into Europe.
Yes, that seems to be the kind of book I was looking for (yeah I know, it’s on the recommended reading page, but now I know of direct link of this topic to my own ancestry :-).
I just noticed there’s a bunch of stuff about the Linear Pottery culture — or ‘Linearbandkeramik’ (it’s so cute how you Germans mash up words) — in the section of The Long Summer dealing with the Euxine flood.
Even a picture of a Linearbandkeramik farm! But I don’t see anything about milk or lactose; I guess those theories are newer.
On the web I found several references to a computer model and a paper published in 2009, but the newspaper article I read referred to genetic analysis of bones from several find spots, not a computer model…I threw away the newspaper, but they usually don’t have any references anyway :-(
BTW: I confused “7000 BC” and “7000 years ago”. All of this supposedly happened aroung 5000 BC.
Tim wrote:
It’s easy to do. Lots of paleontologists use “BP”: “before present”. That makes me nervous because I’ve noticed that the present actually moves! I prefer to write so that my statements will remain true for all time.
Many historians use “BCE”.
In the “BP” time scale, “before present” is fixed to 1950, and the acronym has sometimes been redefined to be “before physics” (meaning the development of radiocarbon dating).
Oh, so the present is officially in 1950? For the purposes of science I’m glad they nailed it down, but there’s something awfully postmodern about living in the year 60 AP.
I read a facetious comment years ago that to counter existential angst BP should instead stand for “Before Presley”. (OK, 1950 is a few years before his first recording so it doesn’t quite work.)
One question that arises is if there are interpolation vs extrapolation issues?
[When I say “predict” below that includes things like as a contribution to an ensemble model for extracting things like average ocean temperature, not necessarily “one-shot predict”.]
Basically, if you’re fitting model parameters based upon training data — whether in a Bayesian way or just as parameters — by construction your model will replicate behaviours in the training data well. For synthesising behaviours “within the kinds of behaviours present in the training set” (ie, interpolation) general expectations of continuity and smoothness of behaviour mean the model ought to still be reasonably accurate. When using a model to predict “behaviour noticeably outside the training set” (ie, extrapolation) one is much less certain that the model is going to be accurate.
So as a “devil’s advocate” question, what’s the feeling about using models to answer questions like whether even higher CO2 levels will lead to an AMOC shutdown? Is it feasible to extrapolate that far with models derived from the historical data (ie, training data) available?
The models aren’t really “derived from the historical data”. Their mathematical structure is derived from physics, and their parameters are tuned to historical data. (Of course, historical data is some guide in choosing what parts of the physics to model, but it’s not just some statistical trend-fitting exercise.)
Whether their predictions hold up in the future depends on (1) whether you think you have the physics right, and (2) whether you think the parameters change over time.
The main question is, “Do we think we have AMOC physics right” (even in the complex models). The answer is “No, we’re not sure”. So yes, you have to take extrapolation into the future with a grain of salt. It’s one reason why I’m interested in learning questions. (If the models are off, how fast do you learn that, and will it affect policy?)
Two questions inspired by financial models:
a) If you have data for the last 100 years, how about fitting your model to the data of the first 50 years and see how good it is able to “predict” the last 50 years? Do people do that routinely?
b) It’s always fun to compare the performance of financial experts and complicated strategies and programs with the most simple strategies imaginable. In finance the simple models usually win: in Germany there were several contests involving a fixed budget and a fixed time span for buying and selling stock. The simplest strategies always bet the experts. Do you have a similar strategy of comparing your models to much much simpler ones? (The simplest model would of course be: Nothing changes. This is surprisingly good in predicting share prices).
(@Eric: please countercheck what I say here :-)
a) You can do such “leave-out validation” experiments, but they’re not too informative with globally aggregated data and leaving out half of an already small data set – especially considering that variables like temperature track the forcing input fairly closely (i.e., the model isn’t terribly nonlinear). But as it happens, I am currently using our box model to conduct “historical learning” experiments.
As for more complicated models like AOGCMs, people don’t do these experiments routinely because they’re generally not fit or “tuned” to historical time series in the first place. Subcomponents of the models are tuned, but it’s usually to reproduce the spatial structure of some kind of “snapshot”, rather than fitting a historic time series (e.g., does the distribution of clouds in 1990-1995 look like the actual distribution of clouds in 1990-1995, rather than trying to fit some time trend in cloud albedo.)
b) I’m very interested in “hierarchies of models”, and I don’t view complex models as necessarily better predictors of everything, compared to simple models. But again it’s kind of hard to test this, since we just don’t have a very long time series of data, and there is a lot of stochastic “natural variability” in there confounding the climate-driven trends.
As I described above, it’s easy for a much, much simpler model (like an energy balance model) to do as well as a fancy GCM as far as global surface temperature goes. That’s not going to tell you a whole lot about other climate variables (like precipitation). You can construct some simple statistical-dynamical model of precipitation, but its skill relative to GCMs on historic data probably won’t say much about precipitation changes a century now, which depend a lot on atmospheric-ocean physics.
The unfortunate truth is that while you can validate the “climatology” of these models (i.e., how well they reproduce current dynamics), it’s really hard to verify their predictions over useful time scales. It takes decades for climate to change, and there aren’t too many decades in the data. So modelers keep testing the physical subcomponents against what they can observe and hope for the best.
It’s not like weather prediction or econometrics where you can test predictions continuously. The only continuous tests you can do on a climate model are of its “weather”, which isn’t going to be very good because of its coarse resolution relative to a true weather model, and isn’t going to tell you everything you need to know about skill at climate dynamics.
Thanks to Nathan for the insight.
In relation to Tim’s point (b), it’s worth bearing in mind that in doing a comparison you’re implicitly specifying a utility function on the results by how you score things, eg, you might minimise say the sums of the absolute differences between predicted and actual stock price. This kind of utility function is useful when playing a “basically stable” stock market, and it can be very hard to beat simple predictors (intuitively because they don’t have the complexity required to be able to go haywire and give really bad predictions). In contrast, you might have a utility function that basically only changes the score when there’s a “sudden, big market swing” and increases or decreases depending whether the model has correctly predicted it or not, and doesn’t modify the score for any other situations. You might use this model for trying to predict times when it’s not safe to have money in the market at all, and simple models generally perform badly at this. That’s not saying simple models are bad, but that in testing models it often takes heavy thought to figure out what performance feature you ought to be measuring.
The basic point is that, in theory you can’t do model comparison independently of the intended use. (Of course, in practice there’s not enough training data, researcher time or computer time to do this completely, but people do try and pick a roughly relevant scoring system.)
Point taken; I don’t know any successful model that predicts “phase changes” at all (10 years ago I read a few papers about a bunch of physicists that tried to apply stochastic processes with long range correlations to simulate these situations, which they compared to phase transitions of the financial markets, but I don’t know how successful these approaches are. Well, if they are successful, these people will be awfully rich by now.)
All models I know are basically linear with white noise and a threshhold strategy (sell if price is above b, buy if price is below a).
I saw the best minds of my generation destroyed by the madness of Wall Street. Except for a couple who drive milk trucks or teach college, my entire peer group of US scientists went to work for financial/insurance companies because no large corporate research has been done in the US for decades. You can see how successful they were: look on their works and despair.
Regarding training and learning, there is nothing sacrosanct about either. The best approach, with robustness avoiding overfitting, is always to do twice as much work as minimally needed, viz: leave half of training out for testing, and half the time alternate training using the testing half for training instead.
Going off-topic, but the impression that I get is that at the moment the quants are bringing in the money and enjoying their lives. That may change if high frequency trading gets disallowed or there are more market meltdowns like the “flash crash” of a couple of months ago. But they’re a different “subgroup” within the investment banks to the sub-prime/CDO/CDOsquared/etc people.
John F said
I saw the best minds of my generation destroyed by the madness of Wall Street.
Like Jim Simons? :)
As a quant myself, I’m curious on what basis you make this claim. Are your peers “unhappy”? Do they regret their career choice?
I have never once regretted my decision to work in finance. To be honest, I love it.
The mathematics and model building are just as satisfactory as playing with Maxwell’s equations and it is even more demanding because the “laws of physics” are constantly changing. In fact, models themselves can and do have impact the systems they are trying to model.
Maybe surprisingly, there is also less “office politics” in finance. My worst experience ever in having to deal with office politics was my two years at MIT Lincoln Lab. I shudder whenever I think of it. I’d much prefer Wall Street.
The big money being made on Wall Street today is in microtrading; look at the spikes in the Dow which occur more or less each day at 9am and 3pm. There’s no fundamental reason for these spikes, and there’s no way to predict them. Mathematical modeling of markets seems to depend on the Black-Scholes model (See http://en.wikipedia.org/wiki/Black-Scholes), and with microtrading, the assumption of instant, cost-less trading is more or less in accord with reality, much more so than in comparison with normal stock trading, so a limitation which is difficult to hedge against is removed. For everyone else except for the insiders who can operate the micro-trading systems, the market is a sure-fire way to lose money. In some ways, it feels a lot like the “pump and dump” schemes of the late 1990s and early 2000s. Due to insider speculation and the total lack of any sort of *effective* regulation, it’s impossible and foolhardy to predict the way the price on any stock will move. No theory of any sort can make any useful predictions about manipulated markets, and participating in such a market (unless you’ve got *real* inside info) is about as good a way of making money as playing three-card Monte. It’s a rigged game and individual investors can’t win, at least under the current rules.
Some readers may be more familiar with reverb in music than Green’s functions. You can record some music in a studio, then fire a gun inside a cathedral, record the echo, and convolve the music with the echo and it sounds like the music was played in a cathedral.
http://en.wikipedia.org/wiki/Convolution_reverb
Nice! I finally threw out my trusty ancient digital reverb box, now that free software does it all even better. Amazing how music can sound so much more rich and evocative just by convolving it with the right function. There’s no more information there — less, technically — but the ear likes it.
I am familiar with Bayesian MCMC techniques in a completely different area, that is, phylogenetic analysis.
http://en.wikipedia.org/wiki/Computational_phylogenetics#Bayesian_inference
There is sometimes concern that the Markov chain has not converged to the posterior distribution. Also, the choice of priors can be difficult and sometimes controversial, especially in high dimensional spaces, where interactions between the priors for different parameters can be complicated.
Do climate modellers worry about these issues too?
For the problems I work on, Markov chain convergence hasn’t been too much of a problem for me; the problems are relatively low-dimensional (especially compared to phylogenetics) and the posteriors fairly well behaved. I’ve been able to handle most of my sampling needs with straight Metropolis or adaptive Metropolis without a lot of tuning.
Priors, on the other hand, are a serious concern, with which I continuously wrestle. There has been a fairly prominent debate within my community about priors for climate sensitivity. The classic reference is Frame et al. (2009), although it has some somewhat confused advice about choosing priors); see Annan and Hargreaves (unpublished), Annan and Hargreaves (2006), Henriksson et al. (2010) (and response), and Annan and Hargreaves (2009) for some of the back-and-forth about this.
In short, when data are sparse and learning times are long, the posterior can be very prior-influenced, especially if you care (as I do) about estimating tail areas rather than best fits.
With climate sensitivity, even if you can come up with an informative prior (e.g., with paleodata), you can’t always come up with informative priors on other parameters that are correlated with it (like ocean vertical heat diffusivity), and those can just bring the prior-dependence back. One problem is that some of these parameters are “effective” parameters in a model and don’t correspond to anything physical you can measure in the real world.
Even when you think you have some informative priors, those themselves can be uncertain. For example, if you apply paleo constraints to climate sensitivity, different models and different data sets will give different answers, so you don’t have just one prior, you have a bunch of them. (You can mix over them or try to do some more sophisticated combination of multiple models and data, but it’s hard to do well.)
Economists have argued that the decision problem is tail- (and prior-) driven. See e.g., Weitzman (2009), although that paper is even more confused about Bayesian statistics; there are various responses out there, e.g. Nordhaus (2009), Smith et al., and others.
I guess this comment probably preempted some of what John was going to ask me in the next installment about my analysis …
That’s okay. I’ll get you to say it more slowly. Some people associated to the Azimuth Project know a lot about Bayesian statistics, Monte Carlo methods and the like: Graham Jones here and also David Tweed leap to mind. But most people, even most mathematicians and physicists, do not!
Now I know more about what questions to ask next…
here’s a few wiki pages which might help:
http://en.wikipedia.org/wiki/Metropolis-Hastings_algorithm
and
http://en.wikipedia.org/wiki/Markov_chain_Monte_Carlo
and
http://en.wikipedia.org/wiki/Bayesian_statistics
and
http://en.wikipedia.org/wiki/Bayesian_probability
and
http://en.wikipedia.org/wiki/Prior_probability (talks about “priors”)
and
http://en.wikipedia.org/wiki/Inductive_bias
Nathan, thanks for the reply and the refs on priors (Annan and Hargreaves, 2009 and others). I had looked for this sort of thing months ago, without finding what I wanted. Now I can use my own priors and decide whether to panic. ;-)
[…] This Week's Finds (Week 304) « Azimuth […]
Here is a short collection of questions, in the wake of this edition of TWF (feel free to ignore them or address them in some future edition of TWF, as you like it :-):
1. How are climate models (AOGCMs) evaluated, i.e. how do we know they are “correct”?
Answer so far: The model consists of modules that abstract certain parts of the physical world, like a part of the ocean or the atmosphere. The time evolution of the input-output behavior can be compared to the “real thing”, e.g. compare the cloud formation 1990-1995 of the model to the observed cloud formation.
An interpolation of historical data is less useful than e.g. in mathematical finance, because there is much less data available and the available data has a low signal-to-noise ratio. Historical data may be influenced by singular events that have to be ignored, rather than incorporated into the model, to predict the future.
2. When climate models fail, for what reasons? What are the most important deficiencies and what needs to be done to improve the models?
3. What knowledge is most important for people working on climate models? E.g. are most people working in the field meteorologists?
3.2 Let’s say a young student with a master in physics applies for a job in climate models to get a PhD, what books would you give her to read to get her up to speed? (I see that the STEP program offers postdoc positions only – let’s say someone with a PhD in solid state physics applies for such a position).
4. Are there open-source numerical libraries you use – or are the models themselves open-source? How does Fortran support concurrency? Did you ever consider using a more “modern” programming language? What are the most important numerical pitfalls? What about unwanted long range correlations of random numbers? Which random number generators do you use?
Oh sorry, STEP does have a PhD program, but it’s listed under “Degrees & Certificates” rather than under “Employment and Fellowship Opportunities”.
Re 4, whilst I’ve never used Fortran myself (as I’ve needed to do stuff like low-level device I/O as well as numerical programming in the same program), my understanding is that the currently widely supported “modern” languages don’t really have semantics as well-optimised for numerical programming, particularly for programs by people who aren’t language experts. (Eg, the default in Fortran is that variables can be aggressively assumed not to alias). There are certainly new languages that have ambitions to provide even better mechanisms (like SaC ( http://www.sac.org ) or Fortress ( http://projectfortress.sun.com )) for numerical computing, but I’m not sure their implementations are yet at the point that a pure user would want to make the jump. So Fortran is currently one of the best choices for this kind of software.
Thought so, my inquiry over at mathoverflow did not result in a “positive” answer, too.
1. It’s not typically the “time evolution” of data that GCM modelers tune their models to. More usually it’s “base climatology”, i.e., the mean state (at some time, or rather averaged over some times).
2. Unresolved sub-grid scale processes, and parametrizations thereof, are probably the biggest problem with GCMs, along with a lack of data to initialize and test the models at such scales. You have to worry whether the parametrization approximations are fundamentally changing the dynamical behavior of the model. This is hard to verify.
It’s also tricky to couple modules. For example, you can test an atmospheric component while holding ocean temperatures to observed values and vice versa. Individually the components may appear to work. But when you couple the two components together and actually allow real energy/moisture transfer between the atmosphere and ocean, the model will usually behave worse and need to be retuned. It can be difficult to detect the presence of “compensating errors” in different submodules.
3. Depends on what part of the model you want to work on. Atmosphere modelers are meteorologically trained, ocean modelers are oceanographers, both of them learn numerics as part of their training. Then there are ecosystem modelers (ecologists), ice modelers (glaciologists), etc. Modelers have to be familiar with both numerical analysis and observational data in addition to the theoretical models they’re implementing.
3.2. Some good intro climate modeling texts are A Climate Modelling Primer by McGuffie and Henderson-Sellers, and Introduction To Three-dimensional Climate Modeling by Washington and Parkinson. There are a few others. Not too many recent ones, though, for some reason. Beyond that, whatever textbooks are relevant to the kind of modeling they do (numerical analysis, plus meteorology or oceanography or whatever).
4. I don’t tend to work with climate models myself, I just use their output. I’m sure they do use some, from Netlib or whereever. The box models I happen to use come with hand-coded numerical integrators, not library routines.
I don’t know anything about Fortran concurrency. I don’t really write Fortran myself. Most of my programming is statistical analysis, in R.
Climate modelers probably aren’t going to move off Fortran anytime soon. When I write high-performance code it’s usually C, for familiarity. Search Steve Easterbrook’s blog (cited in a comment of mine which hasn’t appeared yet) for discussion of using other languages; Michael Tobis has also written about this on his blog (e.g. here).
I can’t tell you much about numerical pitfalls in climate models since I don’t write them. The usual numerical analysis problems (convergence of integrators, etc.), problems with plugging parametrization approximations into “clean” fluid dynamics equations, etc.
I don’t worry about long range random number correlations. I use the default PRNG in R; since R is written by statisticians, I assume it’s among the best available. Climate models are usually deterministic and don’t use RNGs. There are some stochastic climate models out there (mostly toy models), but I haven’t used them.
Nathan wrote:
Tim wrote:
Done!
Anyone else have suggestions for the blogroll? They don’t need to be about climate change. They just need to be for engineers and scientists who want to help “save the planet”, in this most general sense of that term.
(For example, “Less Wrong” is for people who think that we can improve the world by learning to be more rational.)
You might take a look at Michael Tobis’s Only In It For The Gold. He writes a lot on broad questions of sustainability, the compatibility of capitalism and traditional economic theory with environmental stewardship, media communication and public perception of climate change, “culture” clashes between scientists, economists, engineers, etc. He has a “best of” list of blog posts along the right-hand column if you want to check out whether it might be appropriate to Azimuth’s “mission”.
Some other worthwhile sites that come to mind, not necessarily appropriate for Azimuth’s blogroll:
Climate Ethics (run out of Penn State)
Real Climate Economics (not a blog by itself, but contains a group blog)
Yale Environment 360 (more a newsletter than a personal blog, but has a lot of interesting articles and commentary)
I’ll probably think of more …
Have a look at Gapminder.
Another interesting blog is Science of Doom, which is attempting to bridge between the climate science and “skeptic” communities by writing a lot of climate science tutorials (mostly atmospheric radiative transfer and thermodynamics). Read the “About” page for more information on the blog’s pseudonymous author and goals.
I’ve added most of the blogs recommended to my blogroll. Thanks! They look neat.
“The Science of Doom” looks like it’s doing something I might have wanted to do in This Week’s Finds: lead the reader through climate science starting at the beginning. Now I don’t need to! (Anyway, I want to roam over more topics.)
I find it impressive and also deeply depressing to watch the author struggle to teach basic facts about heat transfer to a stubborn and complaining crowd of doubters. With patience bordering on madness, he xeroxes half a dozen physics textbooks that explain how it works… and the first comment says:
“Only in it for the Gold” is too political, at least today: the top articles are 1) complaining about Republicans, 2) complaining about Republican Representative Joe Barton, 3) complaining about Bjørn Lomborg, 4) complaining about “Watts Up With That”, and 5) complaining about Tea Party activists. I probably agree with all these complaints, but I’m looking for more science and less of this incessant struggle. And it reminds me: I’m so happy to get away from the US for a while and have some new things to complain about.
“Gapminder” looks interesting but somehow not ‘bloggy’ enough for my blogroll. Maybe I just don’t understand it.
Personally, I hope the AMOC never enters a COMA…
[…] a tangential note, let me point out John Baez’ most recent “This Week’s Finds”, which has an accessible but fairly in-depth discussion of climate modelling. There have been […]
[…] This Week’s Finds (Week 304) by John Baez talks about the emptying of the lake Agassiz and Younger Driyas event – https://johncarlosbaez.wordpress.com/2010/10/15/this-weeks-finds-week-304/ […]
It took me a while to read all this but it was definitely worthy.
I am tempted of writing the model down using a system description language (the code would really look like the last figure) and do some simulations. Then i guess one could find a robust control law (that is, a policy) to minimize some weighted cost function while keeping into account the uncertainty.
This would be a great application of control but I haven’t found much (actually any) literature from the control engineering side. This thesis http://academic.csuohio.edu/embedded/Publications/Thesis/Vinay_thesis.pdf only deals with estimation, and it’s just an hydrology problem.
Question (for Nathan), are all the numerical parameters that characterize the models given in the paper ? I see there are a bunch of numerical parameters in Table 1, are those the only parameters needed ? If not, is there a place where i can download the code ?
Another question, the climate and carbon cycle modules seem to be only needed to generate a global average temperature history. So in theory one could just give different temperature histories to the AMOC model and still get approximate answers using only the AMOC module, is that right ?
I guess anyway that at the end the best way to generate temperature histories is having a climate model, that way you can also play with more parameters and see the effect (I’m just checking my understanding here).
From the economists’ camp:
Click to access RFF-DP-09-19.pdf
I don’t understand the article you’re pointing to, but it’s got some interesting stuff in it:
• Magnus Hennlockyz, Robust control in global warming management: an analytical dynamic integrated assessment.
‘Deeper uncertainty’ is a concept introduced by Knight. I don’t know if I like it:
There’s a lot of math in this paper. Amusingly, page 12 features a key concept from information geometry: the ‘Kullback-Leibler distance’.
That paper is relevant to my research on uncertainty and economic policy. “Deep uncertainty” is something that I think about. There are various approaches to it.
One is Dempster-Shafer theory. This alternate probability calculus allows you to assign probabilities to things, but also to quantify some amount of “I don’t know what the probability is”, and to propagate this “don’t know” factor through your calculations. It’s a little odd.
Another approach is “open Bayes”, a Bayesian approach that attempts to assign some probability to “hypotheses not considered explicitly”. Elmar Kriegler (who wrote the DOECLIM climate model I use) has written a number of papers on “imprecise probability” and belief functions.
Another Bayesian approach is robust Bayes, which considers a whole family of possible priors and computes the range of posteriors that can arise from these priors.
Alternative approaches to decision making (i.e., not expected utility maximization) include “robust decision making”, which is to give up on fully characterizing uncertainty, and to find policies that are “robust” to errors in your uncertainty assumptions. Rob Lempert has written a lot on this; see here.
Most Bayesian statisticians take a rather simple approach: they just explore the sensitivity of the conclusions to different prior and likelihood assumptions, and leave it at that. If the results are sensitive to assumptions, so be it. Policy turns this into a harder problem: you know your uncertainty estimates are sensitive to assumptions, but you still have to make a decision anyway. It’s a very hard problem!
There may be some classical control theory approaches to the policy problem, but most of them take a dynamic programming approach as in the economics paper you linked. The hydrology thesis involves a state estimation problem, which is different from the problems I usually consider, which are parameter estimation problems.
The parameters in Table 1 are only the ones that I am treating as uncertain. There are many more parameters in the models, whose values are not given in our paper. For those, you’d have to go back to the original source papers where those models were published.
You might be able to reimplement the AMOC model from scratch, but the climate model is a bit finicky (it uses perturbation theory), and the carbon model precomputes lookup tables so it’s fast enough. (Also, I’m not totally sure if it’s well documented enough in the original paper to easily recode.)
We intend to eventually release Fortran code for this model, as part of our economic integrated assessment model, but only after we write a paper documenting it. That probably won’t happen for at least 6 months. You could write the original authors of these models for their code. (That’s what I did.) I don’t know whether they’d share it with you. Right now we don’t have permission from them to release it.
You’re correct that the climate and carbon modules are ultimately used to produce temperature histories, which are what drives the AMOC model. If you have another way of getting temperature histories, you can run them through the AMOC model directly. We coupled in the other modules in order to propagate climate uncertainty through the AMOC model.
[…] first time I came across Azimuth was only Oct 15th – This Week’s Finds (Week 304) – a discussion about the Younger Dryas, which starts: About 10,800 BC, something dramatic […]
The Younger Dryas episode was a cold period lasting about 1,300 years […]