Could we grow the whole universe with all its seeming complexity starting from a little seed? How much can you do with just a little information?
People have contests about this. My programmer friend Bruce Smith points out this animation, produced using a program less than 4 kilobytes long:
As he notes:
…to be fair, the complexity of some of the OS, graphics drivers, and hardware should be included, but this is a lot less than you might think if you imagine rewriting it purely for compactness rather than for speed, and only including what this sort of program needs to produce output.
Sampo Syreeni pointed me to this video, all generated from under 64 kilobytes of x86 code:
As he points out, one trick is to use symmetry.
These fancy images produced from tiny amounts of information are examples of the ‘demoscene’. a computer art subculture where people produce demos: non-interactive audio-visual computer presentations that run in real time.
According to the Wikipedia article on the demoscene:
Recent computer hardware advancements include faster processors, more memory, faster video graphics processors, and hardware 3D acceleration. With many of the past’s challenges removed, the focus in making demos has moved from squeezing as much out of the computer as possible to making stylish, beautiful, well-designed real time artwork […]
The old tradition still lives on, though. Demo parties have competitions with varying limitations in program size or platform (different series are called compos). On a modern computer the executable size may be limited to 64 kB or 4 kB. Programs of limited size are usually called intros. In other compos the choice of platform is restricted; only old computers, like the 8-bit Commodore 64, or the 16-bit Amiga, or Atari ST, or mobile devices like handheld phones or PDAs are allowed. Such restrictions provide a challenge for coders, musicians and graphics artists and bring back the old motive of making a device do more than was intended in its original design.
What else can you do with just a little information? Bruce listed a couple more things:
• Bill Gates’ first commercial success was an implementation of a useful version of BASIC in about 4000 bytes;
• the complete genetic code of an organism can be as short as a few hundred thousand bytes, and that has to be encoded in a way that doesn’t allow for highly clever compression schemes.
So if quite complex things can be compressed into fairly little information, you can’t help but wonder: how complex can something be?
The answer: arbitrarily complex! At least that’s true if we’re talking about the Kolmogorov complexity of a string of bits: namely, the length of the shortest computer program that prints it out. Lots of long strings of bits can’t be compressed. You can’t print most of them out using short programs, since there aren’t enough short programs to go around.
Of course, we need to fix a computer language ahead of time, so this is well-defined. And we need to make sure the programs are written in binary, so the comparison is fair.
So, things can be arbitrarily complex. But here’s a more interesting question: how complex can we prove something to be?
The answer is one of the most astounding facts I know. It’s called Chaitin’s incompleteness theorem. It says, very roughly:
There’s a number L such that we can’t prove the Kolmogorov complexity of any specific string of bits is bigger than L.
Make sure you understand this. For any number,
we can prove there are infinitely many bit strings with Kolmogorov complexity bigger than that. But we can’t point to any particular bit string and prove its Kolmogorov complexity is bigger than 
Over on Google+, Allen Knutson wrote:
That’s an incredibly disturbing theorem, like driving to the edge of the universe and finding a wall.
I call
My friend Bruce estimates that the complexity barrier is a few kilobytes.
I’d like to see a program a few kilobytes long that produces a video showing a big bang, the formation of stars and galaxies, then planets, including one where life evolves, then intelligent life, then the development of computers… and finally someone writing the very same program.
I can’t prove it’s possible… but you can’t prove it isn’t!
Let’s see why.
For starters, we need to choose some axioms for our system of math, so we know what ‘provable’ means. We need a system that’s powerful enough to prove a bunch of basic facts about arithmetic, but simple enough that a computer program can check if a proof in this system is valid.
There are lots of systems like this. Three famous ones are Peano arithmetic, Robinson arithmetic (which is less powerful) and Zermelo-Fraenkel set theory (which is more powerful).
When you have a system of math like this, Gödel’s first incompleteness theorem kicks in: if the system is consistent, it can’t be complete. In other words, there are some questions it leaves unsettled. This is why we shouldn’t be utterly shocked that while a bunch of bit strings have complexity more than
Gödel’s second incompleteness theorem also kicks in: if the system can prove that it’s consistent, it’s not! (If it’s not consistent, it can prove anything, so you shouldn’t trust it.) So, there’s a sense in which we can never be completely sure that our system of math is consistent. But let’s assume it is.
Given this, Chaitin’s theorem says:
There exists a constant
How can we get a number that does the job? Any number

will do. Here:
• 


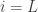
• 
The length of 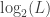

and for the proof of Chaitin’s incompleteness theorem to work, we need this to be smaller than 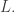

Given all the stuff I’ve told you, the proof of Chaitin’s theorem almost writes itself! You run this bigger program I just described. If there were a bit string whose Kolmogorov complexity is provably greater than
So, we just need to pick a computer language and a suitable system of math, and estimate 
I picked the language C and Peano arithmetic and asked Bruce if he could guess, roughly, what answer we get for
I don’t think it can be done in C, since C semantics are not well-defined unless you specify a particular finite machine size. (Since C programs can do things like convert pointers to integers and back, tell you the size of any datatype, and convert data of any specified datatype to bytes and back.) On a finite machine of
bits, all programs either finish in time less than about
or take forever.
But if you take “C without size-specific operations”, or a higher level language like Python, or for that matter a different sort of low-level language like a Turing machine, then that’s not an issue — you can define a precise semantics that allows it to run a program for an arbitrarily long time and allocate an arbitrary number of objects in memory which contain pointers to each other. (To stick with the spirit of the question, for whatever language you choose, you’d want to disallow use of any large external batch of information like a “standard library”, except for whatever is so basic that you think of it as part of the native language. This is not a serious handicap for this problem.)
The main things that the program ‘
• recognize a syntactically correct statement or proof;
• check the validity of a purported proof;
• recognize certain statements as saying or implying “The Kolmogorov complexity of
is more than
Assuming that
This makes me think that even without trying to compact it much, in a reasonable language we could write
So
Does anyone know if Chaitin or someone actually went ahead a wrote a program that showed a specific value of


Hm.
For any finite number L, I can tabulate all possible programs shorter than L together with their output (or for non-halting programs, the first N digits of their output). I can then prove that the K-complexity of a number is greater than L by simply showing that it (or its first N digits) do not appear in the table. For sufficiently large N there must be at least one such number, where N cannot be larger than the number of unique outputs in the table.
Am I missing something? I suppose there is always the possibility of a non-halting non-cyclical program producing no output in finite time, therefore we can never in principle tabulate its output?
… so L is the length of the shortest non-cyclical non-halting program that does not produce any output in finite time? But of course we can’t prove that any program doesn’t halt…
gah, that should be “N cannot be larger than the logarithm of the number of unique outputs”. And log(unique outputs) <= L
andrewdotcom wrote:
Right, there are programs that never print anything out, and also programs that take a very long time to print anything out, and the undecidability of the halting problem says it’s impossible to write a program that always successfully distinguishes between these two kinds of programs.
So, we can’t prove that the Kolmogorov complexity of a number is greater L by taking all programs of length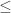 L, running them, and noting that our number does not appear as the output of any one. If in fact it doesn’t, we’ll never know this for sure! Instead, we’ll see that there are a bunch of programs that keep chugging away and not printing anything… but we’ll never be sure that these programs will never print anything out. There will always be a chance, as far as we can tell, that one will eventually print out our number.
L, running them, and noting that our number does not appear as the output of any one. If in fact it doesn’t, we’ll never know this for sure! Instead, we’ll see that there are a bunch of programs that keep chugging away and not printing anything… but we’ll never be sure that these programs will never print anything out. There will always be a chance, as far as we can tell, that one will eventually print out our number.
My argument for Chaitin’s incompleteness theorem, while informal, is watertight. So in fact it proves the undecidability of the halting problem as a corollary. Why? Because if the halting problem were decidable, we could play a trick like the one you suggested, after crossing the programs that don’t halt off our list.
Yes, it’s interesting how many arguments in computability boil down to the halting problem. I suppose the next question should then be: can we design a programming language in such a way that we can make L arbitrarily large? I’ve no idea how to begin tackling that question though.
That’s easy, but misguided. Or more precisely, it’s easy if by “the L for a specific language” you mean the smallest constant you can prove is an upper bound for the “real L” being discussed here, if you limit yourself to thinking about programs written in that specific language.
If you do that, and then just pick an extremely non-powerful language — either far from universal, or extremely inefficient at expressing things — then you can make “L for that language” larger, because using that language, you’d need a longer program to do the task U. (That fact would not be provable, it’s just what you’d experience.)
But all you’ve done by finding a “larger L”, by using a weaker language to find it, is weaken your knowledge about the “actual complexity barrier”, which is the smallest L anyone is able to prove (at a given time in history) by using any language.
BTW, this “smallest L you can find” is still not a “constant of nature”, since you can (probably) never be sure it won’t get smaller still, due to a new discovery (e.g. a smaller program equivalent to U, or some other proof of a smaller bound for how high a complexity is provable), or even a new convention about what formal theories are worth believing in. But if you try as hard as you can to make it smaller, you obviously have something “more like a constant of nature” than if you don’t.
Corrections:
• I should have noted that I was replying to andrewgdotcom’s suggested question about whether we can “design a language in such a way that we can make L arbitrary large”.
• what is easy is making L (for a specific language) larger — not necessarily making it “arbitrarily large” (but not infinite), which might be difficult since it depends on inventing a language which is almost, but not quite, too weak to express U at all. (Though I suppose you might do it in a trivial way like requiring all valid programs to have some very cumbersome syntactic structure that added huge amounts of padding. I see no reason that’s an interesting question, though.)
• what is misguided is thinking that finding a “language with a large L” would somehow make the “real L” larger, and/or that using a “language with a larger L” would somehow be “better”. Rereading your post, you didn’t say those things, so perhaps I read them into it without them being your intention.
I think there is a fun lacuna in that argument to program the universe: producing an automation that starts from the beginning of time and leads to the very programmer herself writing the program. I like this idea by the way. It makes me think of staring at myself in the mirror holding a mirror.
For the possibility of such a program being executed on a classical computer implies a polynomial equivalence between classical and quantum computation. In fact it also implies that there will not be another model of physics discovered that is potentially even more powerful than quantum computation. It’s not that we can’t prove that such a classical computer program could not be executed to simulate the birth of the universe up to the point of the very programmer writing the program, but the resource overhead in simulating the quantum model might require more time than the universe has left. This could rule out a classical solution! Of course, it is still a large open question if classical and quantum computation are polynomial equivalent, outside of the oracle model — inside this model, quantum computers are known to be more powerful.
The other issue is if even the existing classical models of computation need to be adapted to handle consciousness. Most think not. The future could hold blog writing androids that will write nonsense like this at my command, in exchange for battery life. :)
Here’s an earth-like planet generated by just 4K of code. Despite looking like a trailer for a BBC documentary, every single pixel you see there is synthetic. (Yes, it does make use of OS features so it’s not quite the same as a 4K Turing machine.)
Wow, a 4-kilobyte planet! That’s great, Dan!
That’s impressive, how was it done?
Of course, to be fair, we’d have to specify input and output of the program: If I write an empty C program capable to access the Windows API and compile it to a .DLL file with Visual Studio C++ under Windows 7 I get a file that is roughly 27 KB big.
@Tim There’s a whole lot of ‘infrastructure’ work to get things down to 4K. The executable is compressed and it’s not generated with the usual linker. (See http://www.crinkler.net/) The compression was always an important factor during development so the code was written with a view to ensuring the machine code instructions had high redundancy to ensure good compression. Having said that, much of what you see is generated by shader language, not C or assembly language.
Note that the music was also generated by the executable!
(I attended a talk by the developer.)
How does the situation change if we only care about programs that print out the string in some finite (perhaps very long) amount of time? (I’m guessing a lot.)
In the scenario I’m talking about, a program either runs a finite amount of time, halts, and prints a string, or it never halts.
So in one interpretation of your question, the answer is that I already only care about programs that print out the string in some finite (perhaps very long) amount of time. If they print it out at all, they print it in a finite time.
But I guess that’s an uncharitable interpretation. Here’s another.
Say we we start by fixing a time T, or more precisely a number of steps. Then ask “is there any string that we can prove is not printed by any program of length ≤ L in ≤ T steps?” And the answer is yes, infinitely many. We simply run all these programs for T steps and list the strings that get printed out. Most won’t be. This process can be turned into a proof that those not on the list aren’t printed by any program of length ≤ L in ≤ T steps.
So, it’s the “indefinite waiting” that’s the problem.
There’s an algorithm for answering the question “is string i printed out by a program of length ≤ L in ≤ T steps?”
But there’s no algorithm for settling the question “is string i printed out by a program of length ≤ L?”
This is not very surprising. The surprising part happens when we ask “is there any string that we can prove is not printed by any program of length ≤ L?” The answer becomes no when L is large enough.
It’s the complete ignorance that’s surprising here: you might have thought that at least for some strings we could prove this. But the clever proof of Chaitin’s incompleteness theorem shows how our ignorance becomes complete when L hits a certain critical value.
The linked rings in the first video remind me of an illustration in Gravitation. Evidently some other gravity theorists have taken the chain mail idea seriously . Now back to read more of the math…
Just another link about demos or intros. They are not limited only by video/sound. A 2004 3D shooter game .kkkriger is 97 kilobytes long. Here it is:
About Kolmogorov entropy and it’s estimation – It’s interesting that Kolmogorov entropy used explicitly here (more exactly its approximation as “empirical entropy”) as a regularizer for getting low-complexity solution of undetermined linear system. Reularizer = Bayesian prior. As I understand it’s the same as approximating “universal prior” by Solomonoff
That is a practical method which really works. I wonder how L enter here? Does it mean that regularizer is bounded => produce robust to outliers redescending maximum likelihood estimator?
Cosma Shalizi says it best:
“The first and still classic measure of complexity is that introduced by Kolmogorov, which is (roughly) the shortest computer program capable of generating a given string. This quantity is in general uncomputable, in the sense that there is simply no algorithm which will compute it. […] It plays a very important role in every discussion of measuring complexity: in a pious act of homage to our intellectual ancestors, it is solemnly taken out, exhibited, and solemnly put away as useless for any practical application.”
I looked through a collection of papers by Chaitin, Information, Randomness & Incompleteness, papers on Algorithmic Information Theory, Second Edition, February 1990, IBM Research Division, Thomas J. Watson Research Center.
One of these papers is entitled: “An Algebraic Equation for the Halting Probability”. It’s also been printed elsewhere, such as in the easily available book: The Universal Turing Machine: A Half-Century Survey, edited by Rolf Herken. Depending on the formatting, the paper is 4 or 5 pages long.
Chaitin explains how he constructed an exponential Diophantine equation in ≅ 17000 variables, allowed to take any value in the natural numbers, N, plus a parameter denoted ‘n’. Each n ≥ 1 gives its own 17000-variable exponential Diophantine equation. Chaitin says that, if printed out, the parametrized exponential Diophantine equation would take up 200 pages. Quoting Chaitin:
So Chaitin gave one explicit definition of the halting probability Ω and exhibited a parametrized exponential
Diophantine equation with the property quoted above.
A question which I think relates to the complexity barrier topic is:
“How many consecutive bits of Ω does Peano Arithmetic “know” ?” or, “How many consecutive bits of Ω does ZFC “know” ? “.
How big is L? I don’t know.
David Bernier wrote:
I can’t tell you that. Of course it depends on the choice of universal Turing machine. But with a suitable choice, I can tell you how many bits these guys know:
• C. S. Calude and M. J. Dinneen, Exact approximations of omega numbers, Int. Journal of Bifurcation & Chaos, 17 (2007), 1937-1954.
They work out the first 43 bits.
You can’t prove that anything has Kolmogorov complexity above L, but (I’m guessing) you can say that long strings are more likely to have higher complexity than short strings, so you can (I assume) still reason about complexities above L, and do some statistics/combinatorics with them? Are there any particularly interesting results down this path?
Your initial statement would be more correct if you replaced “anything” by “any *specific* thing”.
But your guess is correct; in fact, you can easily show that almost all long strings have complexity almost as high as their length. You just can’t prove that any particular long string is an exception to that general rule, though you know there are a few exceptions. (Statistically, a *very* few exceptions.) So this looks like it leaves plenty of room for statistical conclusions about much higher complexities than L. As for particular interesting results, someone else needs to reply….
CORRECTION — what I just said is backwards in a crucial point. (I wish this forum allowed reply authors to edit their own replies, at least if they did so soon enough, as many forums allow. Then we could correct really embarrassing mistakes like this one!)
I was right that you can easily show that almost all long strings have complexity almost as high as their length. I was wrong that you can’t prove that any particular long string is an exception to that general rule — you can easily prove this (for some of them) by exhibiting a short program that generates it. What I should have said is that you can’t prove that any particular long string is a *non-exception* to the general rule, though you know (of course) that almost all of them are.
There’s no way for me to simply flip a switch and allow people to change their comments. However, if you post a followup comment saying “please replace this by that”, I’ll make the correction by hand and delete the followup comment. I do this a bunch. I’d do it now except your correction is hard to understand without seeing the original mistake.
I also spend a lot of time correcting formatting, grammar and spelling errors in people’s posts—whether they want it or not!
Here is a kind of “result” that you might or might not consider interesting. I also don’t know the answer to whether this kind of result is possible, so I’m asking everyone.
You know that most long strings are high complexity, but no single long string can be proven high complexity. (You could take “high complexity” to mean “complexity almost equal to its length”, or just “complexity more than L”, or something in between, and the question is different but perhaps interesting either way.)
Suppose you say “ok, I will have to accept that, but can you give me a specific *set* of strings and prove to me that *at least one of them* is high complexity, even though you won’t be able to tell me which one?”
Obviously someone can answer this by printing out more than 2**L different strings. But is there a *practical* answer? If there is, it means some (relatively small) algorithm can print out such a list which has a reasonable length, and a proof that “there is some i so that the ith member of this list has high complexity”, but is still (of course) unable to prove that for a specific i.
The question is vague, but for any way of making it specific, it would be interesting to me to know whether or not doing this is either known to be ruled out or known to be possible.
I should add that this is definitely not possible if we want the program which prints this list to be shorter than the complexity limit we’re interested in (whether that is L, or the length of the strings in the list). (Since none of the strings it prints can be more complex than the length of a slightly longer program which just prints the list and then picks one of the output strings as its own output.)
But if we permit the program to be longer than the complexity limit (or dispense with the program and just ask for a specific list of strings to be presented to us, plus a proof that “at least one of these strings is high complexity”), then I don’t yet see a way to rule it out. Intuitively, though, I suspect it’s impossible for a similar reason as the 1-string case is.
Wait, maybe I just did rule it out. Tell me, am I right? (If so, I’m sure it’s already a known result.)
Here is the argument: take the program which prints this list of strings. We know that it can’t work if it’s shorter than the complexity limit, so it has to be longer. But remember that we can never prove that the program itself is that complex. So what if it’s not? Then a shorter program could print this same list of strings, and thus, any specific string in the list. Thus all the strings in the list would be not highly complex.
Since we can’t rule this out (without proving our original program highly complex), we can’t prove even that “at least one of the strings in this list is highly complex”.
(The argument fails if the length of i itself is large compared to the complexity limit, which is just the trivial case of “printing 2**L different strings” which I mentioned earlier, since i has to be at least L long to pick one of them. So of course we define the problem to require the list to have a lot fewer than 2**L strings, where L is the complexity limit we’re interested in.)
Bruce wrote:
As you note later, it’s not always true that if some program prints out a list of strings, a shorter program can print out any specific string in that list. (The program that prints out all strings of some length will often be shorter than the shortest program that prints out a given string of that length.)
Worse, I don’t see a general recipe to take a some program that prints out a list of, say, 10 long strings and get a shorter program that prints out a chosen one. I only see how to get a slightly longer program that does the job.
But this would be enough to get some sort of theorem out of your argument.
Me too. I took that as obvious. I think the overall conclusion still holds. (That is, I am claiming an actual theorem, though perhaps worded vaguely, e.g. leaving some technical conditions to the reader. I think that either (1) you will easily see a precise theorem in there, as soon as you look for it, or (2) I am wrong and am asking for this to be pointed out. If this was a math site I guess I’d be culturally expected to be more precise than that in the first place… or is it one, for postings like this one? :-) )
]
Bruce wrote:
Yes, I think I see one, now that I understand what you’re saying.
I haven’t seen this result before, but there’s a lot of literature in this subject, and I’m only familiar with a bit of it. This book lists lots of results:
• M. Li and P. Vitányi, An Introduction to Kolmogorov Complexity Theory and its Applications, Springer, Berlin, 2008.
so if anyone here has it, they could see if any results like this are known: limitations on being able to prove that a list of strings contains at least one string of Kolmogorov complexity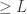 .
.
By the way, in case anyone didn’t notice: my post on Chaitin’s incompleteness theorem and the surprise examination paradox mentions a related result. It involves the fact that if someone hands you a list of strings, you can prove that you can’t prove that exactly one has Kolmogorov complexity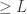 , so then you can prove that you can’t prove exactly two do…
, so then you can prove that you can’t prove exactly two do…
I’m a mathematician, like it or not, so maybe a little more precision would have helped me understand you faster… but it’s no big deal.
I did it. Like most WordPress blogs, this blog uses html for formatting, so you quote stuff like this:
<blockquote>
This is a quote.
</blockquote>
to get this:
Increparare wrote:
For starters, there are some basic results about Kolmogorov complexity here:
• Marcus Hutter, Algorithmic information theory, Scholarpedia.
For example, it’s claimed the Kolmogorov complexity of a number
of a number  (or in other words, the bit string representing
(or in other words, the bit string representing  in binary) obeys
in binary) obeys
for ‘most’ , and
, and
for all for suitable
for suitable  .
.
Why is there that term ? I don’t know.
? I don’t know.
I don’t know really interesting detailed statistical properties of Kolmogorov complexity. But there are lots of fun relations between Kolmogorov complexity and Shannon entropy. This book is a great tour of this circle of ideas:
• M. Li and P. Vitényi, An Introduction to Kolmogorov Complexity Theory and its Applications, Springer, Berlin, 2008.
Recently, Mike Stay and I have shown that Kolmogorov complexity can be seen as a special case of Shannon entropy! We’ve used this to apply lots of ideas from statistical mechanics to the study of Kolmogorov complexity and its many variants, such as Levin’s time-bounded complexity (which, unlike Kolmogorov complexity, is computable). I think these blog posts are the most fun way to get into this:
• John Baez, Algorithmic thermodynamics (part 1), Azimuth.
• John Baez, Algorithmic thermodynamics (part 2), Azimuth.
It turns out most of the basic facts about thermodynamics have algorithmic versions.
John wrote:
Probably from an upper bound for just “giving up on compression” and giving the number in binary, since you need a header to say you’re doing that (c) and to say how many digits the number has (presumably 2 log log n, which is plausible). This is coming from the need for the input to be “self-delimiting”.
John Baez mentioned a book by Li and Vitányi published in 2008. Over at arxiv, I found a preprint by Peter D. Grunwald and Paul M.B. Vitányi, “Algorithmic information theory”, that also appeared in 2008. Their preprint has 37 pages and contains at least one formal definition of the Kolmogorov complexity of a bit string using a variation on the usual Turing machine concept, which they call prefix machines. Their Definition 1, page 13, uses a reference `universal prefix machine’ U. This is done in their Section 4. In Section 4, Example 2 they give a proof that U-complexity and LISP-complexity are essentially the same thing (in bits), up to an additive constant, I think. The URL for their preprint is: http://arxiv.org/abs/0809.2754.
Thanks, David. I’ve added that reference to my summary of this whole discussion on my website.
Chaitin (http://www.umcs.maine.edu/~chaitin/ait2.html) showed that’s true for a variant of LISP that has a “readBit” instruction and whose programs are followed by a string of bits. If you leave off that ability, then the halting probability for LISP is not random;the fact that you can tell where a program ends just by counting parentheses means it’s not an optimal encoding. Cris Calude and I showed (http://arxiv.org/abs/cs.CC/0606033) that the halting probability for paren-balanced LISP is “asymptotically random”, i.e. it is (1-epsilon)-random for any epsilon > 0.
This might be relevant. David Moews held a contest using a clean-semantics variant of C:
See here: http://djm.cc/bignum-results.txt
So the idea that someone could write a program U, in a clean-semantics variant of C that can do those three tasks, in 1 or 2 kcharacters doesn’t seem all that unreasonable.
Also, Tromp’s work on binary lambda calculus seems relevant: http://homepages.cwi.nl/~tromp/cl/LC.pdf
Cool!
Why am I not surprised? There are lots of math jokes about contests to name the biggest number. The last player usually wins.
But if we let logicians into these contests, it becomes impossible for non-experts to even know who won! There’s some pretty scary work on fast-growing computable sequences of numbers, for example.
Graham’s number is fairly large, but probably nothing compared to the ones logicians can describe.
There are even smaller quite stunning “compos” in the demoscene.
This one here has only 256 Bytes – as it’s run in DOS, it doesn’t use any of the usual DirectX libraries as for Windows demos.
Great 1k demos are these:
For 4k in size, these are quite exceptional:
If you are interested in small sized demos, here are some playlists:
256b – 4kb
http://www.youtube.com/user/Annikras?feature=mhsn#p/c/A5E2FF8E143DA58C
64k
http://www.youtube.com/user/Annikras?feature=mhsn#p/c/EEAEFA88ADFAE0C8
Wow, those are impressive (I only looked at a few so far).
(BTW, in general, is the music also created by the demo, or added on separately when it’s posted on YouTube?)
These could almost make you believe that something complex enough to be alive in a simple environment could have a short enough genome to arise by chance… :-)
(To be clear, I do believe something similar to that, though stating exactly what, precisely, is pretty hard.)
The music is generated directly by the executables. If you have a fast (Windows) PC, you can run those demos in realtime. See the given Pouet Link on each of these videos if you are interested.
Here is some more information about the demoscene:
http://en.wikipedia.org/wiki/Demoscene
All true, and lovely graphics. But we’re embedded in a physical universe where Bekenstein bound and Bousso’s holographic bound limit how much data can be packed within a given radius on a plane.
The universal form of the bound was originally found by Jacob Bekenstein as the inequality
S <= 2 pi k R E / (ħ c)
where S is the entropy, k is Boltzmann's constant, R is the radius of a sphere that can enclose the given system, E is the total mass-energy including any rest masses, ħ is the reduced Planck constant, and c is the speed of light. Note that while gravity plays a significant role in its enforcement, the bound is independent of Newton’s Constant G.
In informational terms, the bound is given by
I <= 2 pi k R E / (ħ c ln2)
where I is the information expressed in number of bits contained in the quantum states in the sphere. The ln 2 factor comes from defining the information as the logarithm to the base 2 of the number of quantum states. The right-hand side of the foregoing relation is approximately equal to 2.5769087×10^43×(mass in kilograms)×(radius in meters).]
Bousso’s holographic bound : A simple generalization of the Black Hole entropy bound (cf. holographic principle) to generic systems is that, in quantum gravity, the maximum entropy which can be enclosed by a spatial boundary is given by a quarter of its surface area. However, as a general rule, this simple generalization appears to be false, because the spatial boundary can be taken to be within the event horizon of a black hole. It also fails in cosmological models.
Raphael Bousso came up with a modification that the spatial boundary should not be a trapped surface. This lead him to come up with Bousso’s holographic bound, also known as the covariant entropy bound. Basically, a spatial boundary is valid if, when you consider both null sheets orthogonal to its tangent space, the expansion factor both point in the same direction. This defines inside and outside. The entropy of the interior region is bounded by the surface area of the boundary.
What I've been playing with (i.e. 60-page draft paper) expands on this:
For the sake of argument, suppose that the 3-dimensions of space plus one dimension of time that we perceive the universe to be are a manifestation of a quantum cellular automaton operating according to discrete rules at a 2-dimensional boundary of the holographic cosmos.
Given an “oracle” in the Computational Complexity sense (the theory of classifying problems based on how difficult they are to solve), then a Physics Theory of Everything can violate the Church-Turing thesis. Given such a magical device, a hypercomputer, one could have what appears to be a finitely generated Turing Machine or Cellular automaton model of the universe, or the universe itself {see Appendix A: quantization of the membrane model of the Holographic Universe}, which can physically compute uncomputable functions, and do what does not violate physical law as such, but violates computational complexity limits.
I don’t understand how your second paragraph states the bound promised by your first one. Specifically, if you are about to give me a limit on “how much data can fit within a circle of radius R”, what is this “mass” you’re referring to in the Bekenstein formula in the second paragraph?
(Also, in the first paragraph did you really mean to say “plane”, so that I am trying to fit this data into a circular disk (as opposed to a spherical ball)?)
Bruce: vos Post grabbed his second paragraph from this Wikipedia article without crediting it. The Bekenstein bound has nothing to do with a circle or disk on a plane.
Yes, grabbed and ASCII-ized. I agree with properly citing sources, you’re right.
I got the idea of re-writing John Baez’ inequality as follows:
L – log2(L) > U + C,
That way, the dependence on L is all on one side of the inequality; another thing is that it makes clearer to me that smaller provably valid L are obtained when U, the size of the special program/function which depends on the input i, is made as small as possible.
Since what we’re after is Kolmogorov complexity, and the particular definition of Kolmogorov complexity used affects the size of the program/function with input ‘i’, what might be the most suitable definition of Kolmogorov complexity to use?
We want to get U, the size of the program or function with parameter ‘i’ small, and some part of the program has to deal with Kolmogorov complexity, since the function searches for a valid proof of Kolmogorov_complexity(x) > ‘i’ , with x standing in for some unknown bit-string.
One possible measure of Kolmogorov complexity would be Turing machines with three tape symbols 0, 1, 2 ; by convention, the tape would start with all zeros, and blocks of 1s and 2s once a Turing machine halts would be interpreted as forming “binary strings”, possibly interspersed with “whitespace” (the zeros on the tape once the machine has halted).
A drawback of Turing-machine complexity for strings is that the number of TMs with ‘n’ states grows faster than kn, for any integer ‘k’. One advantage of number of states of a smallest Turing machine that halts and produces a representation of some binary string is its simplicity. Also, the last time I visited Heiner Marxen’s web pages on the original (due to Tibor Rado) Busy Beaver problem, the 5-state problem was still open. The 6-state, two-symbol problem presents a truly astounding leap from the 5-state, two-symbol problem.
Σ(6) > 1018276. This is due to Pavel Kropitz, and has not yet been verified independently, all according to Heiner Marxen’s web pages on the Busy Beaver problem.
I think effective bounds are easiest to attain when the programming language for the program with length U is the same as the programming language used to measure Kolmogorov complexity. So, if the program of length U is in Python, for L – log2(L) > U + C to entail size L being at or beyond the complexity barrier, it seems to me that we need to assume that Kolmogorov complexity is defined in terms of program-size in Python …
There may be an easy way around this “same programming language” requirement, or maybe I missed something in John’s original post. To me, it’s a very interesting topic.
Provided I understand your question correctly then Chaitin claims to have written a LISP programme that does the job (cf. eg. http://www.umcs.maine.edu/~chaitin/howto.html).
If my memory serves me well, I have actually spend some time to check the code and found it convincing. However, that was more than 10 years ago and meanwhile I am in a state where too much ‘meta’ makes me dizzy.
Thanks, Uwe. In his talk, Chaitin sketches a description of a particular universal Turing machine and then says:
So, he’s getting a very concrete estimate on how complex a theory you need to compute n bits of Chaitin’s constant Ω, the probability that this Turing machine halts when you start it with a randomly chosen bit string on its tape.
This constant 7581 could easily be related to the constant L that I’m asking about, but it’s not obvious how. They involve somewhat different ideas. Furthermore, the constant L depends, not only on a universal Turing machine (or programming language), but also on a theory of math.
I think I’ll just ask Chaitin if he has an estimate for L.
Here’s a related result by Chaitin, still not exactly the one I’m looking for, but closer:
This means that if we fix a theory, there’s an explicit limit on how long a string can be if we want to prove that any given LISP program is the shortest one that prints it out.
Okay, looking around a bit further I found this:
• Gregory Chaitin, The Limits of Mathematics.
He says that for a certain universal Turing machine, the complexity barrier is 2359 bits (or less) plus the number of bits in the axioms for your theory of math. More precisely, he writes:
BTW, what does he mean by the bit-length of a formal axiomatic system? I’m sure he says this somewhere… the most natural answer for fitting it into this topic might be the size of a program to print out all its theorems (in an order that makes it easy to check whether a specific statement is present in the output), or of a program to check a proof for validity.
Bruce wrote:
For a full answer, you may need to look at both these books, which are free online:
• Gregory Chaitin, Algorithmic Information Theory.
• Gregory Chaitin, The Limits of Mathematics.
Here’s what I’m getting after 20 minutes of work. The first book defines the LISP complexity of a set of propositions (‘theorems’) to be the length of the shortest LISP program that prints them all out… where he’s using a specific version of LISP. The second book gives a way to write LISP programs in binary:
So, taken together, we get a way to assign a bit-length to any finitely axiomatizable system. It doesn’t depend on the specific choice of the axioms, only on the set of theorems the system can prove.
Interesting. It’s similar to my first guess above, but without the order condition — which is good, since as I noticed long after posting that, the “order” condition is impossible to satisfy (at least you’d better hope it is), since doing so would mean there’d be a provability-determining algorithm. When I noticed that mistake I thought it meant my first guess was completely wrong, since I don’t immediately see how to use a “printer of all theorems, in no special order” (as opposed to a checker of proofs) as the sole formalization of a theory in other algorithms.
Now if that program U didn’t need to iterate over proofs, but only over theorems, then I guess you could use it in U… and I guess that might be all that U really needs… but if that is what was going on in his proof about L, it either means the proof was a bit mis-stated, or there’s some justification for thinking that any “printer of all theorems” can be thought of as an “iterator over all proofs”. (Whereas my natural guess would be that that’s only one way of implementing that, not “essentially the only way”. The latter would not completely surprise me, but it would be interesting, so I’d like to know it explicitly.)
(BTW there must not be many logicians hanging out here right now, or my mistake would have been pounced on by now!)
I should also ask whether he actually gave an upper bound for the bit length of any specific interesting axiomatic system. Adding that to 2359 (if it was for “the right” system) would finally give us his estimate for L. Anyway it’s pretty clear that the total will end up being consistent with “a few thousand”.
If a few thousand times as many people were interested in this as actually are, then there might be a substantial prize offered for lowering this number — not that I know of any practical purpose for doing so. There actually is a prize for improving the compression of a specific long text file (around 100Mbytes IIRC). (I forget where I learned that, so it might have been this blog.)
Bruce wrote:
I don’t know. If he did, it’s probably in the stuff I linked to.
Actually I’d be more inclined to offer a substantial prize for this if I felt more sure that nobody would try to win it!
BTW, when I wrote
I forgot to specify units (bytes vs bits). In fact I forgot to think about them, which can be bad. My earlier “few thousand, or perhaps much less” guess was in “bytes or digits”. Chaitin’s 2359 is in bits. His estimate for L, 2359 + N, is still unknown to this blog. I’d guess N > 2359 bits (simply because axioms for, say, ZF seem more complex than U does to me), but probably not enough greater for the total to reach a few thousand bytes.
My point, following Vitanyi, is that Kolmogorov Complexity has a use at a higher level than merely being about data, but can be about data and a theory together, and thus play a role in axiomatizing Occam’s razor, as derived from Solomonoff’s notion of axiomatizing prediction from a theory.
In a sense, a short video from the demoscene surprises you because of
your theory of the complexity of the visual dynamics.
“Minimum Description Length Induction, Bayesianism, and Kolmogorov Complexity”, Paul M. B. Vitanyi and Ming Li, IEEE Trans. Info. Theory, Vol. 46, No. 2, March 2000, pp. 446-464.
Another trick is to use complementary to achieve task specialization, like we do with sex…
Azimuth explained the complexity barrier of Chatin’s incompleteness theorem […]
But.. to cross the complexity barrier… one needs to realize that IF you had models sufficiently complex to mimic reality you’d have no better way to understand how they work than you do by directly studying real emergent behaviors themselves.
The step that opens up a variety of productive methods is changing from imagining physical systems as driven by our explanatory models, to seeing that we’d need models that behave by themselves to emulate real complex systems that behave by themselves.
That change in perspective amounts to a new paradigm I think, and to the idea of “using math to help discover real complex systems from their behavior, rather than to represent them. That being unfamiliar it might take a bunch of exploratory puzzlement to start.
It becomes more than an idle curiosity when you realize that complex systems display constantly accumulating change in organization, everywhere at once, in response to both their internal and external environments. So while they “exist” as observed entities, after a fashion, they also display a kind of strictly accumulative evolutionary process.
That changes the rules of science, to attempt to study what an observer does not see about how their internal organization is changing. One has to switch from studying how they are “controlled” to more what they are “learning”. Of course, in reality complex systems are neither ever exactly ‘controlled’ nor exactly ‘learning’, but we bend those and other words to fit the reality if we want our research to be productive.
If i understand it right, then this piece of music has the highest Kolmogorov complexity for his class (being a piano piece of a given length):
http://tedxtalks.ted.com/video/TEDxMIAMI-Scott-Rickard-The-Wor
Its Kolmogorov complexity is indeed very low. It is based on Costas arrays for which there are algorithms to generate. Indeed in the video such an algorithm is given: 1*3=3, 3*3= 9, 9*3=27 …
The 88-length array mentioned can be generated by a single Haskell string:
Which compresses the information of
There is a small program to generate it, hence the complexity is low.
I see, thanks.
Then the claim of this being completely “pattern free” is not true. Then it is probably the case that the way in which we humans process (look for patterns) in sounds must be based on a fixed mechanism (something like a FSM) looking for distance between notes. In other words we look only for very specific patterns and can’t use “mod” but only simpler functions based on the difference between notes … not sure, just thinking out loud.
I’d be curious to see the Kolmogorov complexity of a piece by e.g. Bach though.
Giampiero Campa wrote:
If you’ve been reading this thread I guess you know that Kolmogorov complexity is uncomputable, in general, and nobody can prove anything has a Kolmogorov complexity exceeding a few thousand bytes or so. What we can do is compute upper bounds: we can have a contest to see who can write the shortest program to print out a Bach fugue (in some standard format), and the winner will count as an upper bound. But we may never know the shortest program that works—and if the actual Kolmogorov complexity of the piece exceeds the complexity barrier, we know we’ll never know what it is.
So, the fun thing would be to have a contest.
Thus, if O’Rear’s work is correct, we can only determine BB(1919) if we can determine whether ZF set theory is consistent or not. We cannot do this using ZF set theory—unless we find an inconsistency in ZF set theory.
For details, see:
• Stefan O’Rear, A Turing machine Metamath verifier, Metamath, 15 May 2016.
I haven’t checked his work, but it’s available on GitHub.
What’s the point of all this? At present, it’s mainly just a game. However, it should have some interesting implications. It should, for example, help us better locate the ‘complexity barrier’.
I explained that idea here:
• John Baez, The complexity barrier, Azimuth, 28 October 2011.
[…] “The Complexity Barrier” blog post by John Baez https://johncarlosbaez.wordpress.com/2011/10/28/the-complexity-barrier/ […]