In parts 2-24 of this network theory series, we’ve been talking about Petri nets and reaction networks. These parts are now getting turned into a book. You can see a draft here:
• John Baez and Jacob Biamonte, A course on quantum techniques for stochastic mechanics.
There’s a lot more to network theory than this. But before I dive into the next big topic, I want to mention a few more odds and ends about Petri nets and reaction networks. For example, their connection to logic and computation!
As we’ve seen, a stochastic Petri net can be used to describe a bunch of chemical reactions with certain reaction rates. We could try to use these reactions to build a ‘chemical computer’. But how powerful can such a computer be?
I don’t know the answer. But before people got interested in stochastic Petri nets, computer scientists spent quite some time studying plain old Petri nets, which don’t include the information about reaction rates. They used these as simple models of computation. And since computer scientists like to know which questions are decidable by means of an algorithm and which aren’t, they proved some interesting theorems about decidability for Petri nets.
Let me talk about: ‘reachability’: the question of which collections of molecules can turn into which other collections, given a fixed set of chemical reactions. For example, suppose you have these chemical reactions:
C + O2 → CO2
CO2 + NaOH → NaHCO3
NaHCO3 + HCl → H2O + NaCl + CO2
Can you use these to turn
into
It’s not too hard to settle this particular question—we’ll do it soon. But settling all possible such questions turns out to be very hard
Reachability
Remember:
Definition. A Petri net consists of a set 

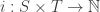
saying how many copies of each state shows up as input for each transition, and a function

saying how many times it shows up as output.
Today we’ll assume both
Jacob and I like to draw the species as yellow circles and the transitions as aqua boxes, in a charmingly garish color scheme chosen by Dave Tweed. So, the chemical reactions I mentioned before:
C + O2 → CO2
CO2 + NaOH → NaHCO3
NaHCO3 + HCl → H2O + NaCl + CO2
give this Petri net:

A ‘complex’ is, roughly, a way of putting dots in the yellow circles. In chemistry this says how many molecules we have of each kind. Here’s an example:

This complex happens to have just zero or one dot in each circle, but that’s not required: we could have any number of dots in each circle. So, mathematically, a complex is a finite linear combination of species, with natural numbers as coefficients. In other words, it’s an element of 
Given two complexes, we say one is reachable from another if, loosely speaking, we can get to it from the other by a finite sequence of transitions. For example, earlier on I asked if we can get from the complex I just mentioned to the complex
which we can draw like this:

And the answer is yes, we can do it with this sequence of transitions:


This settles the question I asked earlier.
So in chemistry, reachability is all about whether it’s possible to use certain chemical reactions to turn one collection of molecules into another using a certain set of reactions. I hope this is clear enough; I could formalize it further but it seems unnecessary. If you have questions, ask me or read this:
• Petri net: execution semantics, Wikipedia.
The reachability problem
Now the reachability problem asks: given a Petri net and two complexes, is one reachable from the other?
If the answer is ‘yes’, of course you can show that by an exhaustive search of all possibilities. But if the answer is ‘no’, how can you be sure? It’s not obvious, in general. Back in the 1970’s, computer scientists felt this problem should be decidable by some algorithm… but they had a lot of trouble finding such an algorithm.
In 1976, Richard J. Lipton showed that if such an algorithm existed, it would need to take at least an exponential amount of memory space and an exponential amount of time to run:
• Richard J. Lipton, The reachability problem requires exponential space, Technical Report 62, Yale University, 1976.
This means that most computer scientists would consider any algorithm to solve the reachability problem ‘infeasible’, since they like polynomial time algorithms.
On the bright side, it means that Petri nets might be fairly powerful when viewed as computers themselves! After all, for a universal Turing machine, the analogue of the reachability problem is undecidable. So if the reachability problem for Petri nets were decidable, they couldn’t be universal computers. But if it were decidable but hard, Petri nets might be fairly powerful—though still not universal—computers.
In 1977, at the ACM Symposium on the Theory of Computing, two researchers presented a proof that reachability problem was decidable:
• S. Sacerdote and R. Tenney, The decidability of the reachability problem for vector addition systems, Conference Record of the Ninth Annual ACM Symposium on Theory of Computing, 2-4 May 1977, Boulder, Colorado, USA, ACM, 1977, pp. 61–76.
However, it turned out to be flawed! I read about this episode here:
• James L. Peterson, Petri Net Theory and the Modeling of Systems, Prentice–Hall, New Jersey, 1981.
This is a very nice introduction to early work on Petri nets and decidability. Peterson had an interesting idea, too:
There would seem to be a very useful connection between Petri nets and Presburger arithmetic.
He gave some evidence, and suggested using this to settle the decidability of the reachability problem. I found that intriguing! Let me explain why.
Presburger arithmetic is a simple set of axioms for the arithmetic of natural numbers, much weaker than Peano arithmetic or even Robinson arithmetic. Unlike those other systems, Presburger arithmetic doesn’t mention multiplication. And unlike those other systems, you can write an algorithm that decides whether any given statement in Presburger arithmetic is provable.
However, any such algorithm must be very slow! In 1974, Fischer and Rabin showed that any decision algorithm for Presburger arithmetic has a worst-case runtime of at least

for some constant 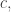

I hope you see why this is intriguing. Provability is a lot like reachability, since in a proof you’re trying to reach the conclusion starting from the assumptions using certain rules. Like Presburger arithmetic, Petri nets are all about addition, since they consists of transitions going between linear combinations like this:
That’s why the old literature calls Petri nets vector addition systems. And finally, the difficulty of deciding provability in Presburger arithmetic smells a bit like the difficulty of deciding reachability in Petri nets.
So, I was eager to learn what happened after Peterson wrote his book.
For starters, in 1981, the very year Peterson’s book came out, Ernst Mayr showed that the reachability problem for Petri nets is decidable:
• Ernst Mayr, Persistence of vector replacement systems is decidable, Acta Informatica 15 (1981), 309–318.
As you can see from the title, Mayr actually proved some other property was decidable. However, it follows that reachability is decidable, and Mayr pointed this out in his paper. In fact the decidability of reachability for Petri nets is equivalent to lots of other interesting questions. You can see a bunch here:
• Javier Esparza and Mogens Nielsen, Decidability issues for Petri nets—a survey, Bulletin of the European Association for Theoretical Computer Science 52 (1994), 245–262.
Mayr’s algorithm was complicated. Worse still, it seems to take a hugely long time to run. It seems nobody knows an explicit bound on its runtime. The runtim might even grow faster than any primitive recursive function. The Ackermann function and the closely related Ackermann numbers are famous examples of functions that grow more rapidly than any primitive recursive function. If you don’t know about these, now is the time to learn!
Remember that we can define multiplication by iterating addition:

where add 

where we multiply

Then we can define an operation 

This grows at an insanely rapid rate:



where we have a stack of 


In 1998 someone came up with a faster algorithm:
• Zakaria Bouziane, A primitive recursive algorithm for the general Petri net reachability problem, in 39th Annual Symposium on Foundations of Computer Science, IEEE, 1998, pp. 130-136.
Bouziane claimed this algorithm is doubly exponential in space and time. That’s very slow, but not insanely slow.
However, it seems that Bouziane made a mistake:
• Petr Jančar, Bouziane’s transformation of the Petri net reachability problem and incorrectness of the related algorithm, Information and Computation, 206 (2008), 1259–1263.
So: if I tell you some chemicals and a bunch of reactions involving these chemicals, you can decide when some combination of these chemicals can turn into another combination. But it may take a long time to decide this. And we don’t know exactly how long: just more than ‘exponentially long’!
What about the connection to Presburger arithmetic? This title suggests that it exists:
• Jérôme Leroux, The general vector addition system reachability problem by Presburger inductive separators, 2008.
But I don’t understand the paper well enough to be sure. Can someone say more?
Also, does anyone know more about the computational power of Petri nets? They’re not universal computers, but is there a good way to say how powerful they are? Does the fact that it takes a long time to settle the reachability question really imply that they have a lot of computational power?
Symmetric monoidal categories
Next let me explain the secret reason I’m so fascinated by this. This section is mainly for people who like category theory.
As I mentioned once before, a Petri net is actually nothing but a presentation of a symmetric monoidal category that’s free on some set of objects and some set of morphisms going between tensor products of those objects:
• Vladimiro Sassone, On the category of Petri net computations, 6th International Conference on Theory and Practice of Software Development, Proceedings of TAPSOFT ’95, Lecture Notes in Computer Science 915, Springer, Berlin, pp. 334-348.
In chemistry we write the tensor product additively, but we could also write it as 
Suppose we have a symmetric monoidal category freely generated by objects
and morphisms

Is there a morphism from
to
?



This is reminiscent of the word problem for groups and other problems where we are given a presentation of an algebraic structure and have to decide if two elements are equal… but now, instead of asking whether two elements are equal we are asking if there is a morphism from one object to another. So, it is fascinating that this problem is decidable—unlike the word problem for groups—but still very hard to decide.
Just in case you want to see a more formal statement, let me finish off by giving you that:
Reachability problem. Given a symmetric monoidal category 


Theorem (Lipton, Mayr). There is an algorithm that decides the reachability problem. However, for any such algorithm, for any 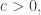

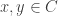


Haas (2002) says that it’s ! “well known” that some Petri nets are Turing equivalent.
“a Petri net is said to mimic a Turing machine—see
Motwani and Raghavan (1995, p. 16)—if, for any initial state of the machine, the net generates the same sequence of states as the machine under an appropriate mapping between the state spaces. It is well known that inhibitor input places are needed for Petri nets to have the same modelling power as Turing machines in the sense that for any Turing machine there exists a Petri net that mimics the machine; see Peterson (1981, Sec. 7.3).”
But then goes on to say that:
“This result is in contrast to the theorems in Section 4.3, which show that permitting inhibitor input places does not increase the modelling power of the spn formalism.”
A contradiction?
Jim wrote:
Hi!
Hmm, I hadn’t known until now that Turing equivalent was used to mean Turing complete, i.e., equivalent in computational power to a universal Turing machine. I don’t like that usage, because to me ‘equivalent’ always shows up in phrases like ‘A and B are equivalent’, not ‘A is equivalent’.
But never mind, that’s just me muttering to myself.
I’m quite sure it’s false that Petri nets can serve as universal computers, since that would contradict the decidability of the reachability problem. So, in this quote:
I’m quite sure that ‘inhibitor input places’ are not something plain old Petri nets can have, but instead a trick for generalizing the definition of Petri net to get more powerful machines.
I happen to have Peterson’s 1981 book, since that’s what got me interested in this stuff. I don’t see anything about this on page 73, but in the chapter on ‘extended and restricted Petri net models’ he writes:
That’s a bunch of jargon: a place is one of the yellow circles here (I’ve been calling them species):
A marking is a way of labeling each place with some number of dots, usually called tokens. A place is unbounded for a given marking if, as transitions occur starting from that marking, there is no upper bound on the number of tokens that can appear in that place.
Marching right along:
So, Petri nets don’t have a full-fledged ability to take a desired action if there happen to be no dots in one of the yellow circles. This turns out to prevent them from being Turing complete. And even before this was proved, people invented lots of generalizations of Petri nets that do have this ability, which are Turing complete:
I’m not so interested in modifications of the Petri net formalism designed to make them Turing complete. We have tons of Turing-complete models of computation, after all. To me it’s more exciting to look at a mathematically natural model of computation which is fairly powerful yet not Turing-complete!
Seeing how close you can get to Turing-completeness without actually hitting it sounds like a fun game… but doing so in a mathematically natural way is even more fun. To me, symmetric monoidal categories are about as mathematically natural as things get: they’re one of the entries of the periodic table.
Maybe now he’s talking about stochastic Petri nets, which are different than Petri nets?
Note that other “specifications of computation” (I don’t like calling them models because they’re run as software on regular “Turing equivalent” microprocessors) which aren’t Turing complete are of immense practical interest to computer scientists. This is because one often wants to give arbitrary untrusted people (including if one distrusts one’s own competence!) the ability to run programs on your machine with a “by-construction” guarantee that they won’t do certain things, like run forever. (There are typicaly independent checks for this kind of thing, but having it guaranteed by the method of specification helps matters.) However, one also wants the specification to be powerful enough to express the mechanisms required for solving actual problems. For example, defining functions recursively can be very helpful, but is non-terminating if suitable “base cases” are not encountered during evalution, and there’s a body of work about how you can minimally restrict the recursive funcitons one can write without losing the guarantee of hitting a base case. There are many other efforts to produce “constrained specification techniques” that can be used in the wild.
(Incidentally, I’m pretty sure “my” Petri net colour scheme just matched an existing diagram on wikipedia or somewhere else :-) )
I am starting to study the chemical reaction in virus with capsid (I am not a biologist).
The chain of reactions use peptides (in your model there are simple molecules), and there are some rna response to some multiple peptide (chemical input to chemical output).
I think that this is the starting of the human thought: some input sensorial peptide activate some rna response (peptides like human word).
It is like a logic chain: you can obtain OR, AND, XOR, NOT reaction for some inputs; these reaction are slow, and quantistic, reaction that work like a computer program, an human thought, a logic inference.
There are some stimulus in the bacteria, or molds, that produce a movement – or a response – without a brain (only with the rna): the evolution change the program, the thought or the logic inference.
I see that the Petri net is an interesting application of a peptide chain, but I cannot evaluate – now – if a direct quantum study of the interaction between rna and peptide can simplify the model.
Saluti
Domenico
It is only an idea: it is possible that a Petri net can represent the rna functions of a virus; so that there is a bijection between virus in an environment and a Petri net.
An other simple idea: the human dna can have a Petri net representation, so that can be possible to represent the protein production in a mathematical form, to simplify the biological representation of the dna function.
Saluti
Domenico
I know this comment is somewhat tangential to the thesis of the post, but I just wanted to point out that although in general the reachability problem is very hard, in practice it is usually very easy!
We often need to find a sequence of transitions that will take us from an initial state to a final state, and this can usually be done by formulating the problem as an integer linear programming problem, which can then be solved with off-the-shelf software (such as “glpk”) to give a “minimal” collection of transitions. In the presence of T-invariants, there will typically be infinitely many valid transition sequences. Indeed, some algorithms for rate constant inference routinely use MCMC methods to explore the space of all possible trajectories from an initial state to a final state, and these usually work well – see http://dx.doi.org/10.1007/s11222-007-9043-x for an early example. The above post makes it clear that such simple-minded methods will break in some scenarios, but these cases are in some sense pathological.
So if any readers find that they need to find a sequence of transitions from one state to another, they should go ahead and try and find one, and not be discouraged by the theoretical complexity of the problem!
Thanks, that’s great! Here’s a little conversation we had on Google+, on a somewhat similar theme:
Piotr Nowak wrote:
I wrote:
Then I read Daniel Lemire’s reply:
So I wrote:
Jerry Federspiel had another idea for why the chemists may have an easier time than the reachability problem suggests. He wrote:
I replied:
Of course a ‘multiset of species’ is what mathematical chemists call a complex.
This is known as the coverability problem. Unlike the reachability problem, its complexity is well understood, as the ExpSpace lower bound of Lipton is matched by an ExpSpace upper bound due to Rackoff:
• Charles Rackoff, The covering and boundedness problems for vector addition systems, Theoretical Computer Science 6 (1978), 223–231.
I should point out that Bouziane’s proof of an elementary upper bound for the reachability problem has been shown incorrect by Jančar:
• Petr Jančar, Bouziane’s transformation of the Petri net reachability problem and incorrectness of the related algorithm, Information and Computation, 206 (2008), 1259–1263.
At the moment there are no known upper complexity bounds for the problem (besides being decidable), not even Ackermannian ones (contrarily to what is stated in the post, or I would be happy to read a reference!).
Wow! Thanks for telling us the latest twist in the story! I’ll correct my blog article.
I have mystical reasons for wanting the reachability problem to only be solvable by an algorithm that’s not primitive recursive. Not very good reasons. I’ve gotten interested in the idea of problems that are decidable but only very slowly, or models of computation that fail to be Turing-complete but are still very powerful—I’d like to see results that probe the ‘borderline of computability’. I also like symmetric monoidal categories. So, I’m hoping they give natural examples of such results.
“What about the connection to Presburger arithmetic? This title suggests that it exists: […]”
Reachability sets in Petri nets go beyond what is expressible in Presburger arithmetic (Hopcroft and Pansiot, 1979, http://dx.doi.org/10.1016/0304-3975(79)90041-0). What Jérôme Leroux has shown is that, however, a proof of non-reachability can be expressed through a Presburger invariant, i.e. two disjoint Presburger sets: one containing the source configuration and all its reachable configurations, the other containing the target configuration and all the configurations that reach it. This yields a semi-algorithm for non-reachability: enumerate pairs of Presburger formulae, until you find a Presburger invariant; as there is a trivial smi-algorithm for reachability (enumerate paths until you find one from source to target), this means that the problem as a whole is decidable. Not a very constructive algorithm :)
Thanks for helping me understand this! Is a ‘Presburger set’ a subset of that can be described by a formula in Presburger arithmetic? It sounds like that’s what you’re saying.
that can be described by a formula in Presburger arithmetic? It sounds like that’s what you’re saying.
This is very nice.
Exactly, and indeed Jérôme Leroux’ algorithm is extremely nice and simple. He recently gave a new proof of its correctness—which does not rely on the (now) classical decompositions by Mayr, Kosaraju, and Lambert—in
Jérôme Leroux, Vector addition system reachability problem: a short self-contained proof, POPL 2011, ACM Press.
I always find it exciting to find someone interested in the intersection between computers and chemistry. You and your readers may find the following related work useful.
There’s quite a lot of related work, of course, since the field goes back over 40 years, to E.J. Corey’s 1969 Science publication “Computer-Assisted Design of Complex Organic Syntheses”, available at http://www.sciencemag.org/content/166/3902/178.full.pdf
Although, perhaps, a review article or two would contextualize the work better. Cook et al.’s “Computer-aided synthesis design: 40 years on” (http://onlinelibrary.wiley.com/doi/10.1002/wcms.61/full) and Todd’s “Computer-aided organic synthesis” (http://pubs.rsc.org/en/content/articlepdf/2005/cs/b104620a) may help.
Also, if you’re interested in other modern formulations of chemistry by computer scientists for computer scientists, you might check out Masoumi and Soutchanski’s “Reasoning about Chemical Reactions using the Situation Calculus (http://www.cs.ryerson.ca/~mes/publications/MasoumiSoutchanski_2012FallAAAI-DiscoveryInformaticsSymposium_Nov2-4.pdf) or my “Construction of New Medicines via Game Proof Search” (http://www.aaai.org/ocs/index.php/AAAI/AAAI12/paper/view/4936).
Enjoy!
Thanks! Sorry for the huge delay in thanking you, but I’m circling back to this area right now, and I will enjoy these references.
Last time I described the reachability problem for reaction networks, which has the nice feature of making links between chemistry, category theory, and computation. […]