Luke Muelhauser, executive director of the Machine Intelligence Research Insitute, has been doing some interviews:
• Scott Aaronson on philosophical progress.
• Greg Morrisett on secure and reliable systems.
• Robin Hanson on serious futurism.
Recently he interviewed me. Here’s how it went.
LM: In a previous interview, I asked Scott Aaronson which “object-level research tactics” he finds helpful when trying to make progress in theoretical research, and I provided some examples. Do you have any comments on the research tactics that Scott and I listed? Which recommended tactics of your own would you add to the list?
JB: What do you mean by “object-level” research tactics? I’ve got dozens of tactics. Some of them are ways to solve problems. But equally important, or maybe more so, are tactics for coming up with problems to solve: problems that are interesting but still easy enough to solve. By “object-level”, do you mean the former?
LM: Both! Conceiving of—and crisply posing—good research problems can often be even more important than solving previously-identified research problems.
JB: Okay. Here are some of my tactics.
(1) Learn a lot. Try to understand how the whole universe works, from the philosophical, logical, mathematical and physical aspects to chemistry, biology, and the sciences based on those, to the historical sciences such as cosmology, paleontology, archaeology and history, to the social sciences such as psychology, sociology, anthropology, politics and economics, to the aspects that are captured best in literature, art and music.
It’s a never-ending quest, and obviously it pays to specialize and become more of an expert on a few things – but the more angles you can take on any subject, the more likely you are to stumble on good questions or good answers to existing questions. Also, when you get stuck on a problem, or get tired, it can be really re-energizing to learn new things.
(2) Keep synthesizing what you learn into terser, clearer formulations. The goal of learning is not to memorize vast amounts of data. You need to do serious data compression, and filter out the noise. Very often people will explain things to you in crappy ways, presenting special cases and not mentioning the general rules, stating general rules incorrectly, and so on.
This process goes on forever. When you first learn algebraic topology, for example, they teach you. homology theory. At the beginner’s level, this is presented as a rather complicated recipe for taking a topological space and getting a list of groups out of it. By looking at examples you get insight into what these groups do: the nth one counts the n-dimensional holes, in some sense. You learn how to use them to solve problems, and how to efficiently compute them.
But later—much later, in my case—you learn that algebraic topology of this sort not really about topological spaces, but something more abstract, called “homotopy types”. This is a discovery that happened rather slowly. It crystallized around the 1968, when a guy named Quillen wrote a book on “homotopical algebra”. It’s always fascinating when this happens: when people in some subject learn that its proper object of study is not what they had thought!
But even this was just the beginning: a lot has happened in math since the 1960s. Shortly thereafter, Grothendieck came along and gave us a new dream of what homotopy types might actually be. Very roughly, he realized that they should show up naturally if we think of “equality” as a process—the process of proving two thing are the same—rather than a static relationship.
I’m being pretty vague here, but I want to emphasize that this was a very fundamental discovery with widespread consequences, not a narrow technical thing.
For a long time people have struggled to make Grothendieck’s dream precise. I was involved in that myself for a while. But in the last 5 years or so, a guy named Voevodsky made a lot of progress by showing us how to redo the foundations of mathematics so that instead of treating equality as a mere relationship, it’s a kind of process. This new approach gives an alternative to set theory, where we use homotopy types right from the start as the basic objects of mathematics, instead of sets. It will take about a century for the effects of this discovery to percolate through all of math.
So, you see, by taking something important but rather technical, like algebraic topology, and refusing to be content with treating it as a bunch of recipes to be memorized, you can dig down into deep truths. But it takes great persistence. Even if you don’t discover these truths yourself, but merely learn them, you have to keep simplifying and unifying.
(3) Look for problems, not within disciplines, but in the gaps between existing disciplines. The division of knowledge into disciplines is somewhat arbitrary, and people put most of their energy into questions that lie squarely within disciplines, so it shouldn’t be surprising that many interesting things are lurking in the gaps, waiting to be discovered.
At this point, tactics (1) and (2) really come in handy. If you study lots of subjects and keep trying to distill their insights into terse, powerful formulations, you’re going to start noticing points of contact between these subjects. Sometimes these will be analogies that deserve to be made precise. Sometimes people in one subject know a trick that people in some other subject could profit from. Sometimes people in one subject have invented the hammer, and people in another have invented the nail—and neither know what these things are good for!
(4) Talk to lots of people. This is a great way to broaden your vistas and find connections between seemingly different subjects.
Talk to the smartest people who will condescend to talk to you. Don’t be afraid to ask them questions. But don’t bore them. Smart people tend to be easily bored. Try to let them talk about what’s interesting to them, instead of showing off and forcing them to listen to your brilliant ideas. But make sure to bring them some “gifts” so they’ll want to talk to you again. “Gifts” include clear explanations of things they don’t understand, and surprising facts—little nuggets of knowledge.
One of my strategies for this was to write This Week’s Finds, explaining lots of advanced math and physics. You could say that column is a big pile of gifts. I started out as a nobody, but after ten years or so, lots of smart people had found out about me. So now it’s pretty easy for me to blunder into any subject, write a blog post about it, and get experts to correct me or tell me more. I also get invited to give talks, where I meet lots of smart people.
LM: You’ve explained some tactics for how to come up with problems to solve. Once you generate a good list, how do you choose among them?
JB: Here are two bits of advice on that.
(1) Actually write down lists of problems.
When I was just getting started, I had a small stock of problems to think about – so small that I could remember most of them. Many were problems I’d heard from other people, but most of those were too hard. I would also generate my own problems, but they were often either too hard, too vague, or too trivial.
In more recent years I’ve been able to build up a huge supply of problems to think about. This means I need to actually list them. Often I generate these lists using the ‘data compression’ tactic I mentioned in part (2) of my last answer. When I learn stuff, I ask:
• Is this apparently new concept or fact a special case of some concept or fact I already know?
• Given two similar-sounding concepts or facts, can I find a third having both of these as special cases?
• Can I use the analogy between X and Y to do something new in subject Y that’s analogous to something people have already done in subject X?
• Given a rough ‘rule of thumb’, can I state it more precisely so that it holds always, or at least more often?
as well as plenty of more specific questions.
So, instead of being ‘idea-poor’, with very few problems to work on, I’m now ‘idea-rich’, and the challenge is keeping track of all the problems and finding the best ones.
I always carry around a notebook. I write down questions that seem interesting, especially when I’m bored. The mere act of writing them down either makes them less vague or reveals them to be hopelessly fuzzy. Sometimes I can solve a problem just by taking the time to state it precisely. And the act of writing down questions naturally triggers more questions.
Besides questions, I like ‘analogy charts’, consisting of two or more columns with analogous items lined up side by side. You can see one near the bottom of my 2nd article on quantropy. Quantropy is an idea born of the analogy between thermodynamics and quantum mechanics. This is a big famous analogy, which I’d known for decades, but writing down an analogy chart made me realize there was a hole in the analogy. In thermodynamics we have entropy, so what’s the analogous thing in quantum mechanics? It turns out there’s an answer: quantropy.
I later wrote a paper with Blake Pollard on quantropy, but I gave a link to the blog article because that’s another aspect of how I keep track of questions. I don’t just write lists for myself—I write blog articles about things that I want to understand better.
(2) Only work on problems when you think they’re important and you see how to solve them.
This tactic isn’t for everyone, but it works for me. When I was just getting started I would try to solve problems that I had no idea how to solve. People who are good at puzzles may succeed this way, but I generally did not.
It turns out that for me, a better approach is to make long lists of questions, and keep thinking about them on and off for many years. I slowly make progress until—poof!—I think I see something new and important. Only then do a take a problem off the back burner and start intensely working on it.
The physicist John Wheeler put it this way: you should never do a calculation until you already know the answer. That’s a bit of an exaggeration, because it’s also good to fool around and see where things go. But there’s a lot more truth to it than you might think.
Feynman had a different but related rule of thumb: he only worked on a problem when he felt he had an “inside track” on it—some insight or trick up his sleeve that nobody else had.
LM: And once you’ve chosen a problem to solve, what are some of your preferred tactics for actually solving it?
JB: By what I’ve said before, it’s clear that I get serious about a problem only after I have a darn good idea of how to solve it. At the very least, I believe I know what to do. So, I just do it.
But usually it doesn’t work quite that easily.
If you only officially tackle problems after absolutely every wrinkle has been ironed out by your previous musings, you’re being too cautious: you’ll miss working on a lot of interesting things. Many young researchers seem to fall prey to the opposite error, and waste time being completely stuck. The right balance lies in the middle. You break a problem down into sub-problems, and break those down into sub-subproblems… and you decide you’re ready to go when all these sub-subproblems seem likely to be doable, even before you’ve worked through the details.
How can you tell if they’re doable? This depends a lot on having previous experience with similar problems. If you’re a newbie, things that seem hard to you can be really easy to experts, while things that seem easy can turn out to be famously difficult.
Even with experience, some of sub-subproblems that seem likely to be routine will turn out to be harder than expected. That’s where the actual work comes in. And here it’s good to have lots of tricks. For example:
(1) If you can’t solve a problem, there should be a similar problem that’s a bit easier. Try solving that. And if you can’t solve that one… use the same principle again! Keep repeating until you get down to something you can solve. Then climb your way back up, one step at a time.
Don’t be embarrassed to simplify a problem to the point where you can actually do it.
(2) There are lots of ways to make a problem easier. Sometimes you should consider a special case. In math there are special cases of special cases of special cases… so there’s a lot of room for exploration here. If you see how enough special cases work, you’ll get ideas that may help you for your original problem.
(3) On the other hand, sometimes a problem becomes simpler when you generalize, leaving out potentially irrelevant details. Often people get stuck in clutter. But if it turns out the generalization doesn’t work, it may help you see which details were actually relevant.
(4) Sometimes instead of down or up the ladder of generality it pays to move across, by considering an analogous problem in a related field.
(5) Finally, a general hint: keep a written record of your efforts to solve a problem, including explanations of what didn’t work, and why. Look back at what you wrote from time to time. It’s amazing how often I come close to doing something right, forget about it, and come back later—sometimes years later—and see things from a slightly different angle, which makes everything fall into place. Failure can be just millimeters from success.


Very reassuring—I started keeping a list of problems to work on, 5 years ago, but kept getting stuck, trying to work on problems that were too vague at that time.
Ambitious youngsters tend to come up with problems that are difficult and vague. I know: I was one myself!
If you keep your list, keep thinking about it, keep adding to it, keep trying to make the problems more precise, eventually you’ll start making progress. It can easily take a decade or two to make progress on big problems, so patience is important. In the meantime, it’s really good to practice making up problems that are precise enough and easy enough that you have a good chance of solving them in a week or two! What you want is a big list of related problems to think about, ranging from quite easy to quite hard.
One way to quickly generate lists of interesting problems is to examine the boundary between X and not-X, where X can be almost anything – things, concepts, processes, or sometime when you’re bored, just words. Since X often has many attributes, it can have many such boundaries. This is an extremely prolific tool. Also, it forces one to examine the definition of X in more detail, usually forcing a “decent” to a more sophisticated characterization requiring the use of more advanced tools. It can be a little unnerving, however, since using recursive applications, one quickly reaches the end of human knowledge almost effortlessly. Some totally random examples of X: virus, alive, red, sweet, integer, isomorphism, symmetric, dog, democracy, religion, atonal, vitamin, torque, … and on and on… oh, yes, and infinity. Just pick your area of interest and turn the crank!
About thinking of equality as a process of proving two things to be the same — have you written more about that elsewhere? If not, what exactly do you mean by “process” — is it more than just “a way they are the same” (e.g. an isomorphism)?
Bruce wrote:
Yes. For example, back in 2006 I wrote this in “week227” of This Week’s Finds:
Later I gave a course on this stuff, and you can see the notes here:
• Classical versus quantum computation, Fall 2006.
It continued on to the winter and spring (follow the links).
More importantly, Vladimir Voevodsky invented a new foundations for mathematics in which we instead of mere equations we have ‘proofs of sameness’ (treated as paths), ‘proofs of sameness of proofs of sameness’ (treated as paths of paths), and so on ad infinitum. It’s called homotopy type theory, it’s very popular, and there’s a free book about it:
• Homotopy Type Theory: Univalent Foundations of Mathematics.
So, this vision has been worked out in great detail, and there’s a whole book of interesting things to say about it!
Reading my old article again, I can imagine someone thinking those two proof trees look so similar that it’s pointless to introduce a name for the 2-morphism going between them—why not just say they’re “equivalent”? The answer is that a rather large and interesting transformation between proofs can be built up out of lots of steps that individually look quite small and dull.
Does HoTT support circularity? Can the point being typed be a constituent of propositions supported by the point? For example, if the point or situation supports common knowledge between us, can there be propositions that the point or situation supports propositions that you know the situation and that I know the situation?
Reading vast amounts of material has always been my path from boredom and my problem vector. My interests are often stimulated from just following your blog regularly and I am always excited to see it come up on my email feed. If something like Network theory makes it into my magic memory I usually start to somehow see it again. I do have a naive question.. would network theory be a good approach to simplify a simple common geometric object, with the goal to somehow “recursively map it” to a useful computable algorithm? It may sound uninteresting but the object is a brick, which as far as I can see; in its iterative use it resembles an algorithm.. so can it be a confident assumption that the problem has a solution, or am I just imagining things?
I don’t see how network theory could simplify a simple geometric object like a brick. Network theory should help us better understand things like this:
Click for details!
You probably shouldn’t treat networks as simiple bricks, but you could treat them as complicated bricks that you could build even more complicated bricks out of.
See, for example, Spivak’s operad of wiring diagrams: http://arxiv.org/abs/1305.0297. A similar idea is implicit in my work: http://arxiv.org/abs/1208.1513
Hi, Eugene! Over on the n-Café you asked what I thought a network was, and I said “a graph with labelled vertices and/or edges, thought of as a morphism in a bicategory”. The point here is that if we take a labelled graph and decree some of its vertices to be inputs and some to be outputs, we can compose these labelled graphs by attaching the outputs of one to the inputs of the other. Composition is associative up to isomorphism so we get, not a category, but a bicategory. Alex Hoffnung and Mike Stay have shown that this kind of bicategory is compact closed, so we can “tensor” these graphs (lay them side by side “in parallel”), turn inputs around to be outputs, and so on: all the things you might want, I think.
Anyway, regardless of whether we use operads or n-categories to formalize it, I think we all agree that a key thing about networks is that you can stick them together to form larger networks. Turning this around, we can study the behavior of a large network by studying the behavior of its parts and how they interact.
I agree to agree with you :).
We can also study the behavior of a large network by looking at the maps into it from other networks and maps out of it to other networks. I think you would agree with that.
Definitely! Of course this is how I study objects in any category: by looking at the morphisms in and out of it. To me the extra cool thing about networks is that they’re also morphisms, so we can compose them. (When you’ve got a 1-morphism in a bicategory, it’s a morphism from the point of view of the objects, but an object from the point of view of the 2-morphisms. As Paul Simon said about life in a New York apartment, “one man’s ceiling is another man’s floor.)
From “There Goes Rhymin’ Simon” — fantastic album which I haven’t heard in decades. I didn’t remember the song was about apartment life; all I could remember were the tinkling piano triplets until I just looked it up on Youtube.
One thing that is bugging me is that physical systems have states and observables, so networks of physical systems should have phase spaces. And I don’t really see these phase spaces when a network is a “graph with labelled vertices and/or edges, thought of as a morphism in a bicategory”. Could you comment/clarify/elaborate?
I believe in your work you want to label the vertices with phase spaces. That’s an example of what I’m talking about. And I guess it’s a good sign of the bicategorical structure that we’re labelling the vertices with objects in a category, rather than elements of a set!
In the signal flow diagrams of control theory, as explained in my talk, the edges are labelled with spaces, while the vertices are labelled by relations from a product of spaces to another product of spaces. However, in the version of the theory I describe here, all these spaces are the same! They’re all the same space of ‘signals’, a vector space over the field of rational functions $\mathbb{R}(s).$ where
over the field of rational functions $\mathbb{R}(s).$ where  acts as
acts as 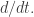 So, the labelling of edges is invisible in this example. It becomes visible in more general kinds of signal flow diagrams where we have different types of signal.
So, the labelling of edges is invisible in this example. It becomes visible in more general kinds of signal flow diagrams where we have different types of signal.
(And again, it’s a good sign that ‘type’ here is being used the way they do in computer science, meaning an object in a category.)
I believe the spaces I’ve just been talking about should be viewed as configuration spaces rather than phases spaces. As you’ll see near the end of that talk, when we get signal flow diagrams from electrical circuit diagrams the signals come in pairs: the voltage and current along a wire. These pairs should be thought of as lying in and the symplectic structure on
and the symplectic structure on  become important.
become important.
Thanks for prodding me: I had to have some new ideas to make up this explanation, and I’ll have to do more work to flesh it out! But the simple point is: if you want a network that “has phase spaces”, you’re going to take a graph and label its edges and/or vertices with phase spaces.
Enjoying John Baez’s blog Azimuth. Especially the posts on good research practices and an older post on levels of mathematical understanding.
[…] Finding and solving problems | Azimuth: Tactics for posing clear, crisp research problems: learn a lot, keep synthesizing, look in the gaps, talk to lots of people. Lists! I totally resonate with the part about keeping lists around. And breaking down problems. […]
John Carlos Baez did a really interesting interview with Luke Muelhauser, where Baez gave good advice on how to solve […]
I’ve been interested for some time in the problem of constructing a Friendly Artificial Intelligence—a general artifical intelligence that shares human values, instead of just killing us all or whatever. There’s this organization called MIRI which is doing research on this problem, and their director, Luke Muelhauser, recently interviewed John Baez. And in the comments of the interview on Baez’s blog, Baez started talking about Homotopy Type Theory, and Univalent Foundations! Anyway, may daydream is that maybe thinking about some of the problems (the Tiling Agents problem is the one I have in mind, specifically) from a HoTT perspective might yield some interesting insights. But that is still very far away, and just a dream for now…
Finally, humiliated and defeated, I gave up. I think it was October 2004.
This was the worst feeling: nearly a whole year gone with absolutely nothing to show for it. Worse, I was wracked with guilt, feeling I’d totally wasted Nick’s time.
…
Things soon got better. By a miracle my postdoc had been extended for a while, so at least I wasn’t on the job market straight away. Secondly, at the end of 2004 I went to a truly inspiring conference at the Isaac Newton institute where I met up with Guifre Vidal who showed me something amazing: the Multiscale Entanglement Renormalisation Ansatz, and I realised that what I should do is focus on more my core skill set (quantum entanglement and many body quantum spin systems). I began working on tensor networks, read a fantastic paper of Hastings, and got into the Lieb–Robinson game.
If I had my time again what would I do differently? I don’t regret working on this problem. It was worth a try. My mistake was to keep working on it, to the exclusion of everything else, for too long. These days I am mindful of the advice of Wheeler: you should never do a calculation until you already know the answer. I also try to keep a portfolio of problems on the go, some risky ones, and some safe ones. (More on that in a future post.) Finally, upon reflection, I think my motivation for working on this problem was totally wrong. I was primarily interested in solving a famous problem and becoming famous rather than the problem itself. In the past decade I’ve learnt to be very critical of this kind of motivation, as I’ve seldom found it successful.
John Baez, as part of an interview with Luke Muelhauser and the Machine Intelligence Research Institute has written up his intellectual habits, which include learning as much as possible about everything, looking for gaps, compressing knowledge and climbing the ladder of abstraction, a list of questions for doing so, analogy charts, and keeping a list of open problems. It’s in the same class as works like Gian-Carlo Rota’s “Ten Lessons I wish had been Taught” and Richard Hamming’s “You and Your Research,” which are also good reads.