Here’s how Fisher stated his fundamental theorem:
The rate of increase of fitness of any species is equal to the genetic variance in fitness.
But clearly this is only going to be true under some conditions!
A lot of early criticism of Fisher’s fundamental theorem centered on the fact that the fitness of a species can vary due to changing external conditions. For example: suppose the Sun goes supernova. The fitness of all organisms on Earth will suddenly drop. So the conclusions of Fisher’s theorem can’t hold under these circumstances.
I find this obvious and thus uninteresting. So, let’s tackle situations where the fitness changes due to changing external conditions later. But first let’s see what happens if the fitness isn’t changing for these external reasons.
What’s ‘fitness’, anyway? To define this we need a mathematical model of how populations change with time. We’ll start with a very simple, very general model. While it’s often used in population biology, it will have very little to do with biology per se. Indeed, the reason I’m digging into Fisher’s fundamental theorem is that it has a mathematical aspect that doesn’t require much knowledge of biology to understand. Applying it to biology introduces lots of complications and caveats, but that won’t be my main focus here. I’m looking for the simple abstract core.
The Lotka–Volterra equation
The Lotka–Volterra equation is a simplified model of how populations change with time. Suppose we have 
For example, the replicators could be organisms of one single biological species, and the types could be different genotypes. Or the replicators could be genes, and the types could be alleles. Or the replicators could be restaurants, and the types could be restaurant chains. In what follows these details won’t matter: we’ll have just have different ‘species’ of ‘replicators’.
Let 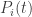


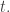
Let’s assume the population obeys the Lotka–Volterra equation:

where each function 
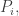
We call
To write the Lotka–Volterra equation more concisely, we can create a vector whose components are all the populations:
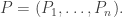
Let’s call this the population vector. In terms of the population vector, the Lotka–Volterra equation become
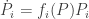
where the dot stands for a time derivative.
To define concepts like ‘mean fitness’ or ‘variance in fitness’ we need to introduce probability theory, and the replicator equation.
The replicator equation
Starting from the populations 
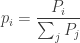
As a mnemonic, remember that the big Population 
How do these probabilities

Then the Lotka–Volterra equation gives

Using the definition of

The expression in parentheses here has a nice meaning: it is the mean fitness. In other words, it is the average, or expected, fitness of a replicator chosen at random from the whole population. Let us write it thus:
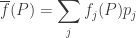
This gives the replicator equation in its classic form:

where the dot stands for a time derivative. Thus, for the fraction of replicators of the
The moral is clear:
To become predominant you have to be fitter than average.
This picture by David Wakeham illustrates the idea:

The fundamental theorem
What does the fundamental theorem of natural selection say, in this context? It says the rate of increase in mean fitness is equal to the variance of the fitness. As an equation, it says this:
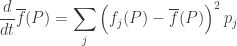
The left hand side is the rate of increase in mean fitness—or decrease, if it’s negative. The right hand side is the variance of the fitness: the thing whose square root is the standard deviation. This can never be negative!
A little calculation suggests that there’s no way in the world that this equation can be true without extra assumptions!
We can start computing the left hand side:
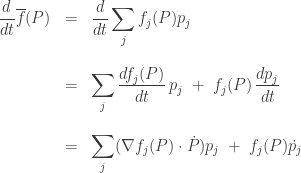
Before your eyes glaze over, let’s look at the two terms and think about what they mean. The first term says: the mean fitness will change since the fitnesses 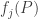
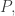
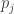

We could continue the computation by using the Lotka–Volterra equation for 

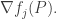

does not!
This suggests an extra assumption we can make. Let’s assume those gradients 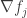
In other words, let’s assume that the fitness of each replicator is a constant, independent of the populations:

where 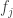
Then we can redo our computation of the rate of change of mean fitness. The gradient term doesn’t appear:

We can use the replicator equation for 
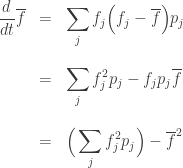
This is the mean of the squares of the
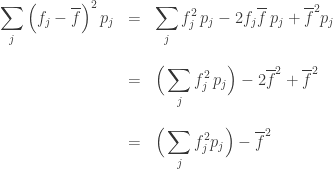
Same thing.
So, we’ve gotten a simple version of Fisher’s fundamental theorem. Given all the confusion swirling around this subject, let’s summarize it very clearly.
Theorem. Suppose the functions
obey the equations
for some constants
Define probabilities by
Define the mean fitness by
and the variance of the fitness by
Then the time derivative of the mean fitness is the variance of the fitness:
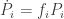



This is nice—but as you can see, our extra assumption that the fitness functions are constants has trivialized the problem. The equations
are easy to solve: all the populations change exponentially with time. We’re not seeing any of the interesting features of population biology, or even of dynamical systems in general. The theorem is just an observation about a collection of exponential functions growing or shrinking at different rates.
So, we should look for a more interesting theorem in this vicinity! And we will.
Before I bid you adieu, let’s record a result we almost reached, but didn’t yet state. It’s stronger than the one I just stated. In this version we don’t assume the fitness functions are constant, so we keep the term involving their gradient.
Theorem. Suppose the functions
for some differentiable functions
called fitness functions. Define probabilities by
Define the mean fitness by
and the variance of the fitness by
Then the time derivative of the mean fitness is the variance plus an extra term involving the gradients of the fitness functions:



The proof just amounts to cobbling together the calculations we have already done, and not assuming the gradient term vanishes.
Acknowledgements
After writing this blog article I looked for a nice picture to grace it. I found one here:
• David Wakeham, Replicators and Fisher’s fundamental theorem, 30 November 2017.
I was mildly chagrined to discover that he said most of what I just said more simply and cleanly… in part because he went straight to the case where the fitness functions are constants. But my mild chagrin was instantly offset by this remark:
Fisher likened the result to the second law of thermodynamics, but there is an amusing amount of disagreement about what Fisher meant and whether he was correct. Rather than look at Fisher’s tortuous proof (or the only slightly less tortuous results of latter-day interpreters) I’m going to look at a simpler setup due to John Baez, and (unlike Baez) use it to derive the original version of Fisher’s theorem.
So, I’m just catching up with Wakeham, but luckily an earlier blog article of mine helped him avoid “Fisher’s tortuous proof” and the “only slightly less tortuous results of latter-day interpreters”. We are making progress here!
(By the way, a quiz show I listen to recently asked about the difference between “tortuous” and “torturous”. They mean very different things, but this particular case either word would apply.)
My earlier blog article, in turn, was inspired by this paper:
• Marc Harper, Information geometry and evolutionary game theory.
The whole series:
• Part 1: the obscurity of Fisher’s original paper.
• Part 2: a precise statement of Fisher’s fundamental theorem of natural selection, and conditions under which it holds.
• Part 3: a modified version of the fundamental theorem of natural selection, which holds much more generally.
• Part 4: my paper on the fundamental theorem of natural selection.


Upper-case vs lower-case P’s is an issue when using hand writing. Not so much when type-set, as you do here.
Even when hand-writing, there’s no problem with, say, distinguishing A from a.
Very interesting, I am curious to see the thing for non-constant f! Crazy question: If one would assume some structural relation between averages values and differentiation (like in the mean value theorem) then the variance would be related to second derivatives and we would have an analog of the heat equation. Is there some way to make sense of this?
I just added a version for nonconstant fitness functions that follows from all the calculations I already did. It’s not very charismatic.
I don’t know how to get second derivatives or the Laplacian into the game here.
There are other things to say, which I hope to discuss next time!
IIRC, if you view the replicator equation geometrically as deriving from the Fisher information metric, it’s possible to use standard methods from Riemannian geometry to compute a heat equation on the same metric. From the information geometry side, see Guy Lebanon’s thesis “Riemannian Geometry and Statistical Machine Learning”.
Thank you very much Mark, quite interesting! Now, I try to understand if we can give any sensical interpretation of replicator time evolution in terms of heat diffusion.
I’d say the heat equation is more connected to Brownian motion, which might serve as a way of thinking about a random walk, e.g. due to mutations. Someone should have tried this—I don’t know.
Hi John!
For a less trivial example, FFT (without the extra term) holds for linear symmetric fitness landscapes of the form where
where 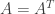 for the matrix
for the matrix  . This goes back at least to [1], to the earlier form of the replicator equation that explicitly described
. This goes back at least to [1], to the earlier form of the replicator equation that explicitly described  alleles at a gene locus (which is assumed to be linear and symmetric). More generally, FFT holds for landscapes
alleles at a gene locus (which is assumed to be linear and symmetric). More generally, FFT holds for landscapes  that are Euclidean gradients (see Theorem 19.5.1 of [2], or [3]).
that are Euclidean gradients (see Theorem 19.5.1 of [2], or [3]).
There’s a neat little calculation here that illuminates the difference between the replicator equation and the (Fisher / Shahshahani) gradient. If we have a fitness landscape that isn’t a Euclidean gradient we can nevertheless compute the (Shahshahani) gradient of the (IIRC half of the) mean fitness. Starting with for arbitrary
for arbitrary  , computing the gradient results in a replicator equation with landscape
, computing the gradient results in a replicator equation with landscape 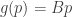 where
where  is the symmetrization of
is the symmetrization of  .
.
If we take a landscape for an anti-symmetric matrix like the rock-paper-scissors game, this gradient is zero everywhere, so the dynamic is motionless. In contrast, the phase portrait of the replicator equation for the RSP landscape consists of concentric cycles about a non-attracting equilibrium (with the KL-divergence constant along the cycles instead of being a Lyapunov function.)
In this case the mean fitness is zero, so away from the rest point at (1/3, 1/3, 1/3) FFT wouldn’t work without the extra terms as the variance would be non-zero. The extra term of is the negative of the variance, which can be directly shown by computing all the terms out.
is the negative of the variance, which can be directly shown by computing all the terms out.
In general (again IIRC, it’s been a while) the gradient is something like where
where  is the Jacobian matrix, which should reduce to the example above for
is the Jacobian matrix, which should reduce to the example above for  .
.
[1] S. Shahshahani, “A New Mathematical Framework for the Study of Linkage and Selection” (1979)
[2] Hofbauer and Sigmund, “Evolutionary Games and Population Dynamics” (1998)
[3] J. Hofbauer, “The selection-mutation equation” (1985)
I definitely want to talk about less trivial examples. Thanks for helping line them up. I was just reading Evolutionary Games and Population Dynamics. I couldn’t find where they talk about Fisher’s fundamental theorem. Theorem 19.5.1, eh? I’ll check it out.
It’s stated as equation 19.18 after the proof of Theorem 19.5.1 (which it follows from), but not named as FFT (or cited). Theorem 19.5.1 is part of Theorem 3 in [3]. See also Theorems 1, 2, and 3 in my paper, which are these theorems and the information theory analog of FFT.
I’m finding Theorem 19.5.1 a bit frustrating. The statement gives two mutually incompatible equations involving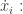
and
My guess is that the first equation for is “just for fun”, not something we should use, though we should use
is “just for fun”, not something we should use, though we should use
The second equation for is the one actually used in the proof.
is the one actually used in the proof.
Is that right?
Then in (19.18) below, is the time derivative of a point moving around on the probability simplex, defined to have components
is the time derivative of a point moving around on the probability simplex, defined to have components
Right?
Yes that proof isn’t the most enlightening / well explained — they reuse the dummy variable in a confusing way as you’ve noted.
in a confusing way as you’ve noted.
FFT can also be shown directly as follows.
Assuming that and that
and that  follows the replicator equation, using the chain rule we have that
follows the replicator equation, using the chain rule we have that
The last step is bit tricky and follows because we can subtract
That sum is zero because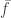 factors out (doesn’t depend on i) and so
factors out (doesn’t depend on i) and so
and since and
and  we have
we have
So FFT works for the gradient because of the chain rule. In the text Theorem 7.8.1 (on page 82) does this calculation for the special case that for a symmetric matrix
for a symmetric matrix  .
.
More generally, if one looks at the mean fitness for an arbitrary , there’s an extra term
, there’s an extra term  (like in Wakeham’s article). Why? If we start instead with a vector-valued function
(like in Wakeham’s article). Why? If we start instead with a vector-valued function  and ask about the time derivative of its mean, we have that
and ask about the time derivative of its mean, we have that
The right most term can be manipulated into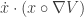 where
where  denotes the element-wise product (Hadamard product). The two terms are equal when
denotes the element-wise product (Hadamard product). The two terms are equal when  and it’s easy to see that happens if
and it’s easy to see that happens if 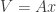 for a symmetric matrix
for a symmetric matrix  . That makes the two terms of
. That makes the two terms of  equal so we get twice the variance (e.g. the extra term in FFT is just another copy of the variance). Alternatively, we can start with
equal so we get twice the variance (e.g. the extra term in FFT is just another copy of the variance). Alternatively, we can start with  as the half-mean fitness so that the time derivative is just the variance.
as the half-mean fitness so that the time derivative is just the variance.
Thanks for your detailed reply—this is really helpful! I’ll try to explain some of this stuff in a nice way.
I fixed the typos, and I’m happy to do so because it gives me a chance to work through the equations in detail.
One thing I can’t fix is this:
Expert blog-commenters know to click “Reply”, not on the comment they’re replying to, but on the comment it was replying to.
If you do this, you create a comment that’s the same width as the comment you’re replying to. If you don’t do this, the comment thread gets skinnier and skinnier, which is especially unpleasant for comments with equations.
I’m still confused, Marc, about whether the in your argument are supposed to be probabilities or populations. That is: are they constrained to sum to 1, or not?
in your argument are supposed to be probabilities or populations. That is: are they constrained to sum to 1, or not?
In your calculation you say they sum to 1, so let’s assume that.
If they are constrained to sum to 1, I’m not sure what
means, since we can’t change just one while holding the rest fixed. Maybe
while holding the rest fixed. Maybe  is defined on the whole orthant
is defined on the whole orthant
so we know what
means, but then in your calculation below they sum to 1?
This would solves some problems, but not all, since when we derive the replicator equation from the Lotka–Volterra equation, the right-hand side of the replicator equation actually involves not just the probabilities but actually the populations:
(Here I’m using for probabilities and
for probabilities and  for populations.) So my next question is, when you write
for populations.) So my next question is, when you write
is this partial derivative being evaluated at (in the simplex) or
(in the simplex) or  (in the orthant)?
(in the orthant)?
For the replicator equation I assumed that the population is infinite and that . (Above I used
. (Above I used  from the reference which was intended to match your
from the reference which was intended to match your  .) Note if we start from the replicator equation, we have that
.) Note if we start from the replicator equation, we have that

(even if we don’t assume the proportions sum to 1), so the sum has to be constant and preserved along trajectories (the replicator equation is “forward-invariant”). Anyway in my case only the proportions appear.
As for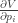 … I think they are just the formal partial derivatives (assuming variable independence) within the context of the multivariate chain rule for
… I think they are just the formal partial derivatives (assuming variable independence) within the context of the multivariate chain rule for  where all the
where all the  are implicitly functions of
are implicitly functions of  . IIUC we don’t need to consider the impact of holding some variables constant in this case. If we knew
. IIUC we don’t need to consider the impact of holding some variables constant in this case. If we knew  explicitly as functions of
explicitly as functions of  (satisfying constraints), it wouldn’t matter if we used the chain rule as above or rewrote
(satisfying constraints), it wouldn’t matter if we used the chain rule as above or rewrote  to a function of
to a function of  and then took the derivative.
and then took the derivative.
Your reply leaves me even more befuddled.
1) In the framework I’m describing in this post the population is never “infinite”. The populations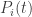 are treated as valued in
are treated as valued in 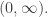 This is an idealization which works best for large populations, but using it we get the Lotka–Volterra equations and these equations are the starting-point of my post. These equations make mathematical sense for any positive finite real populations
This is an idealization which works best for large populations, but using it we get the Lotka–Volterra equations and these equations are the starting-point of my post. These equations make mathematical sense for any positive finite real populations 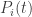 , so we don’t ask question like “what does a population of 2.5 mean?”—we just work with the math. From these equations we derive the replicator equation
, so we don’t ask question like “what does a population of 2.5 mean?”—we just work with the math. From these equations we derive the replicator equation
for the probabilities . But the replicator equation is not an autonomous system of differential equations for the probabilities, because it involves the populations as well, and many different choices of populations
. But the replicator equation is not an autonomous system of differential equations for the probabilities, because it involves the populations as well, and many different choices of populations 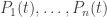 give the same probabilities
give the same probabilities
Thus, the time evolution of the probabilities does not depend on just the probabilities now, but also the choice of populations giving these probabilities. Unless, of course, we make an extra assumption on the nature of the fitness functions , such as that they depend only on the probabilities! This assumption is equivalent to demanding
, such as that they depend only on the probabilities! This assumption is equivalent to demanding
for all and all
and all  This in turn is equivalent to
This in turn is equivalent to
for all
2) A partial derivative with respect to one coordinate only makes sense if we know what other coordinate functions are being held constant: the answer depends on that choice. If we have a function defined on
defined on  or the positive orthant,
or the positive orthant,
makes sense because implicitly we are holding all the other coordinates
coordinates  constant. If we have a function
constant. If we have a function  defined only on the simplex, this partial derivative becomes ambiguous, since it’s impossible to change
defined only on the simplex, this partial derivative becomes ambiguous, since it’s impossible to change  without changing some of the other coordinates. I can imagine ways to disambiguate it, e.g.: take the directional derivative in the direction on the simplex that makes the smallest angle to the vector pointing in the
without changing some of the other coordinates. I can imagine ways to disambiguate it, e.g.: take the directional derivative in the direction on the simplex that makes the smallest angle to the vector pointing in the  direction in
direction in 
Theorem 19.5.1 in Evolutionary Games and Population Dynamics does not address either of these issues, making their proof (and yours) very hard to interpret. I’ve tried a number of ways to get it make sense, and they keep breaking down when I try to write up a proof. Right now I have yet another way in mind, but I’m nervous.
(1) As you point out, we’re talking about two different replicator equations. The reference and I are using an autonomous system of only the population proportions / probabilities that isn’t necessarily derived from a Lotka-Volterra equation.
For a combination of mathematical and conceptual reasons, from my experience with the literature, people tend to use models like
• the replicator equation for “very large” or infinite populations, involving only proportions and with fitness functions that only depend on proportions
• the Lotka-Volterra for finite yet “continuous” population sizes, so that derivatives or discrete dynamics systems can still be used
• Markov processes such as the Moran and Wright-Fisher processes for “more realistic” populations (finite with integral population sizes)
(Note I’m not taking issue with your approach and I understand that it retains all the as finite and unbounded.)
as finite and unbounded.)
(2) Along a trajectory of my replicator equation the population proportions are all functions of a single independent variable, time. Since we’re taking a derivative of a function along a trajectory of the system with respect to time, there’s no freedom to choose a direction for the derivative, even though
along a trajectory of the system with respect to time, there’s no freedom to choose a direction for the derivative, even though  is multivariate when not constrained to the trajectory. So it is a directional derivative with direction determined by the dynamical system. IIUC this applies in the abstract to both our formulations, but your equation has both
is multivariate when not constrained to the trajectory. So it is a directional derivative with direction determined by the dynamical system. IIUC this applies in the abstract to both our formulations, but your equation has both  and
and  (also functions of just time ultimately, and perhaps the directions are often the same up to normalization).
(also functions of just time ultimately, and perhaps the directions are often the same up to normalization).
In my case, the derivative of function (like the mean fitness) along a trajectory can then be understood as
(like the mean fitness) along a trajectory can then be understood as
where the gradient is given by the partial derivatives (with all other variables constant) and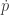 by the dynamical system. See [1] or a text like [2].
by the dynamical system. See [1] or a text like [2].
[1] https://en.wikipedia.org/wiki/Lyapunov_function#Basic_Lyapunov_theorems_for_autonomous_systems
[2] Hassan Khalil, “Nonlinear Systems”, just above Theorem 4.1
Thanks, Marc! I think I finally get it. Hofbauer and Sigmund are really talking about a conceptually different replicator equation in Theorem 19.5.1 of Evolutionary Games and Population Dynamics—different than the one I’ve been talking about, that is. And thanks to you I actually understand this other equation.
We could say it like this: we don’t have populations, we just have a time-dependent probability distribution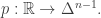 We can think of the simplex
We can think of the simplex  as sitting in
as sitting in  in the usual way, and pick a function
in the usual way, and pick a function  defined on a neighborhood of
defined on a neighborhood of  and demand this version of the replicator equation:
and demand this version of the replicator equation:
where
and
The vector field with
with
is tangent to the simplex, because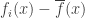 is the gradient of
is the gradient of  with its normal component subtracted out. So our replicator equation
with its normal component subtracted out. So our replicator equation
describes a point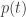 moving around on the simplex.
moving around on the simplex.
In fact is just the gradient of
is just the gradient of  restricted to the simplex, and the replicator equation describes gradient flow on the simplex.
restricted to the simplex, and the replicator equation describes gradient flow on the simplex.
The weird thing, from this point of view, is why we’re bothering to do such a roundabout procedure. All we needed to get our replicator equation was a function on the simplex. But what we do is this: arbitrarily extend
on the simplex. But what we do is this: arbitrarily extend  to a neighborhood of the simplex in
to a neighborhood of the simplex in 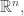 then take its gradient to get a vector field on that neighborhood, and then subtract off the normal component and restrict the result to the simplex to get our vector field
then take its gradient to get a vector field on that neighborhood, and then subtract off the normal component and restrict the result to the simplex to get our vector field 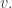
The only reason for doing this that I see is that
looks like “excess fitness”, so in the end we get a result reminiscent of Fisher’s fundamental theorem. But we don’t really have any populations, just probabilities, so the functions really don’t have any significance by themselves anymore: only the
really don’t have any significance by themselves anymore: only the  do.
do.
That explanation matches up with the information geometry formulation, where a relationship between a derivative of a mean of a function and its variance is given without a dynamic being involved, just the Fisher geometry of the simplex. In [1] Amari shows the following.
Let be a finite set of size
be a finite set of size  . We’ll equate the manifold of discrete probability distributions
. We’ll equate the manifold of discrete probability distributions  with the simplex
with the simplex 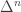 , where the elements of
, where the elements of  correspond to the obvious corner points of the simplex. So
correspond to the obvious corner points of the simplex. So
Let be a function and
be a function and ![E[A]: \Delta^n \to \mathbb{R}](https://s0.wp.com/latex.php?latex=E%5BA%5D%3A+%5CDelta%5En+%5Cto+%5Cmathbb%7BR%7D&bg=ffffff&fg=333333&s=0&c=20201002) denote the map computing the mean of
denote the map computing the mean of  at
at 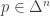 , i.e.
, i.e. ![p \mapsto E_p[A] = \sum_i{p_i A(i)}](https://s0.wp.com/latex.php?latex=p+%5Cmapsto+E_p%5BA%5D+%3D+%5Csum_i%7Bp_i+A%28i%29%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Then the variance is
. Then the variance is
where the norm is induced by the Fisher metric.
The proof basically boils down to that![A - E_p[A]](https://s0.wp.com/latex.php?latex=A+-+E_p%5BA%5D&bg=ffffff&fg=333333&s=0&c=20201002) is the gradient of
is the gradient of ![E[A]](https://s0.wp.com/latex.php?latex=E%5BA%5D&bg=ffffff&fg=333333&s=0&c=20201002) at
at  , and then the norm from the Fisher metric gives
, and then the norm from the Fisher metric gives
That’s basically your explanation of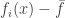 being the gradient of
being the gradient of  if
if  were the mean fitness — if the
were the mean fitness — if the  are all constants, then
are all constants, then
So then this version of FFT comes down, as you said above, to the replicator equation (sometimes) being the gradient flow of the mean fitness on the simplex.
[1] Amari, Methods of Information Geometry, 1995, p. 42.
“Tortuous” and “torturous” (and “torture”) however both come from the same basic Latin root, torquere, “to twist”, whence “torque” (obviously), “torsion”, and various other words.
John,
This is really really fine.
My introduction to maths in biology, as a post-Masters student, was reading Yodzis (1978), Competition for Space and the Structure of Ecological Communities (Lecture Notes in Biomathematics). And, of course, Lotka-Volterra makes into Hirsch and Smale (section 12.2), Differential Equations, Dynamical Systems, and Linear Algebra (1974) which I encountered during a course on nonlinear systems at Cornell University in the late 1980s.
What I have found, after looking into the eugenics roots of many statisticians of the late 19th century and early 20th (I’m reading Kevles, In the Name of Eugenics, 1985) is that a number of the ideas that Fisher was credited were around, notably those in his 1918 paper. Statisticians get off on his notions of experimental design there, but I can’t imagine those weren’t already known in mathematical combinatorics.
Indeed, a number of papers have remarked that others should have shared the platform with Fisher, notably Yule and Weinberg (as noted in Hill, 2018). The context is sketched by Visscher and Goddard (2019) on the anniversary of Fisher (1918).
Judging by notes in a modern course on population genetics, such as represented in the notes taught by Wilkinson (2015), Hardy and Weinberg have a prominent role. (Incidently, Wilkinson introduces the EM algorithm as an improvement upon the Fisher variance formula.) But strikingly, and perhaps in contrast to Fisher, according to Crow (1999), Hardy and Weinberg independently conceived of these rules as “routine applications of the binomial theorem” and so didn’t understand the fuss.
There’s an attempt to put this history all together by Edwards (2008).
‘fitness’–
Maybe a biologist would include learning as a part of fitness.
There is a laboratory experiment called ‘probability learning’ in which the laboratory animal forages optimally in the presence of changes in probability.
The set-up is a number of doors and a very hungry rat. The door to its cage opens. He faces in front of him a number of closed doors. Behind one of these closed doors there is food. If he guess correctly and goes to the correct door, the door will open when he gets there, and there will be food.
(By the way, all the other doors will open as well, showing him that there was food only behind the door that he chose.)
Now let’s say that he chooses incorrectly. The door he’s chosen will open, but there will be no food behind it. All of the other doors will open as well. And at that point, the rat sees the door he should have chosen, behind which there is food. But it is not the particular door that he did choose. Again, there is food behind only one of the doors.
Well, the rat ultimately goes back to his cage for water or to sleep. The door to his cage closes behind him.
And then, after some amount of time, the same situation repeats. The door to his cage opens and he has to make another choice between the closed doors.
Will he choose correctly or not?
(I never got involved in one of these experiments, and I know there may be ethical issues here about starving a rat.)
Little did the rat know that the experimenter had a random number generator and was randomly putting food behind, say, door A 75 percent of the time, and behind door B 25 percent of the time.
When all is said and done, the rat will have chosen door A 75 percent of the time and door B 25 percent of the time. He has ‘learned the probability’ and hence the name of the experiment: ‘probability learning.’
The equation goes like this:
Say the probability of the experimenter putting food behind a particular door is x.
And the probability of the rat choosing that particular door is y.
Then with a probability of (1-x) the experimenter will put the food behind some door other than that particular door.
And with a probability of (1-y) the rat will choose some door other than that particular door.
For each door, the model for the equation is that the rat will associate two different kinds of regret:
Regret at having chosen that particular door when he sees that the food occurred at some other door. Which for a particular door means that the rat will experience this kind of regret with probability ‘y(1-x)’
Regret at having NOT chosen that particular door when he has chosen some other door, and he sees that the food DID occur at that door. Which for a particular door means the rat will experience this kind of regret with probability ‘(1-y)x”
For each door, these two different kinds of regret in the model oppose each other in ‘force’, and the solution will be when these two forces of regret balance each other.
Here is the equation that the rat appears to solve unconsciously:
y(1-x)=x(1-y)
For each door behind which there is food, the answer is x=y.
Now I have to refer you to Randy Gallistel’s book ‘The Organization of Learning,’ chapter 11. There he reports a related foraging experiment with fish. But now instead of an individual animal in a laboratory, the experiment occurs in a fish pond.
Say there are two feeding tubes, out of which prey fish are sent with some probability by the experimenter.
Say that in a chosen window of time, the experimenter sends 7 prey fish out of tube A and 3 prey fish out of tube B. And, say that waiting for this prey is a school of 10 predator fish.
What happens is this:
7 of the predator fish will compete for prey at door A.
While 3 of the predator fish will compete for prey at door B.
It’s a Nash equilibirum.
No single predator fish can improve his chances for a prey fish by going to the other door. Very rarely is a predator fish observed to change doors.
A model for the result is this:
Regret #2, above, becomes dominated by a fear of the competitive group. Within its current group, a fish is probably experiencing some kind of order. While joining the other group is an unknown. Better the devil you know than the one you don’t, I guess.
Now substitute a dollar bill of cost for each predator fish and a dollar bill of benefit for each prey fish, and substitute for the feeding tubes– projects wit positive cash flow for financial investment. ‘Optimal capital budgeting’ would also be this kind Nash equilibirum. No dollar bill of cost could improve its payoff by changing to a different project for investment.
Improved fitness relative to these types of models might come from more evolved imagination and then language, where stories could be told and the language enables more and more things to be imagined, more and more things to regret, doubt and fear.
But then technology enters and the wilderness starts to be eliminated on a limited planet. Highly tuned imaginative story telling that supports ever increasing regret, doubt and fear about more and more things becomes a signal of reduced fitness, and some way of evolving or learning cooperation seems needed for survival.
What does seem evident to more and more people today is that human fitness on a limited planet requires reality-based cooperation rather than more and more highly evolved fantasy in story telling, story telling that’s clearly intended to generate ever increasing levels of doubt and fear.