This post is just for fun. I’ll start with Pascal’s triangle and show you the number e hiding inside it. Using this, we’ll see how the product of all numbers in the nth row of Pascal’s triangle is related to the nth triangular number.
That’s cute, because Pascal’s triangle looks so… triangular!
But then, with a massive amount of help from Greg Egan, we’ll dig a lot deeper, and meet strange things like superfactorials, the magic properties of the number 1/12, and the Glaisher–Kinkelin constant.
First let’s get warmed up.
Warmup
Pascal’s triangle is a famous and much-studied thing. It was discovered long before Pascal. It looks like this:

We write 1’s down the edges. We get every other number in the triangle by adding the two numbers above it to its left and right. People call these numbers binomial coefficients, since you can also get them like this:
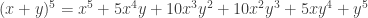
We get the 10 in 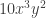

where the binomial coefficient 
Since we can permute n things in
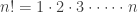
ways, there are

ways to take n things and choose k of them to be x’s and (n-k) of them to be y’s. You see, permuting the x’s or the y’s doesn’t change our choice, so we have to divide by 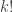
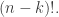
So, the kth number in the nth row of Pascal’s triangle is:
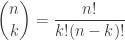
All this will be painfully familiar to many of you. But I want everyone to have an fair chance at understanding the next section, where we’ll see something nice about Pascal’s triangle and the number

The hidden e in Pascal’s triangle
In 2012, a guy named Harlan Brothers found the number e hiding in Pascal’s triangle… in a very simple way!
If we add up all the numbers in the nth row of Pascal’s triangle we get 


This may seem mysterious, but in fact it’s rather simple once you see the trick. I’ll use a nice argument given by Greg Egan.
We’ve said 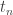

And since this is so much fun, let’s do it again! Divide this quantity by its next value:
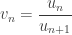
Now look:
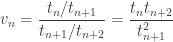
So, this is the thing that should approach e.
But why does it approach e? To see this, first take Pascal’s triangle and divide each number by the number to its lower left. We get a second triangle of numbers. Then take each number in this second triangle and divide it by the number to its lower right! We get a third triangle, like this:

If you think a bit, you’ll see:
• In the first triangle, the product of all numbers in the nth row is
• In the second, the product of all numbers in the nth row is 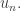
• In the third, the product of all numbers in the nth row is 
And look—there’s a cool pattern! In the third triangle, all the numbers in any given row are equal. In the row with n numbers, all those numbers equal

So, the product of all these numbers is
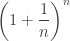
But it’s a famous fact that

Some people even use this as a definition of e. So,

which is just what we wanted!
Puzzle 1. Use the formula I mentioned:
to show all the numbers in the same row of the third triangle are equal.
Triangular numbers

The number of balls in a triangular stack with n balls at the bottom is called the nth triangular number,
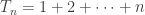
If you chop a square of balls in half along a diagonal you get a triangle, so 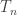

But if you chop the square in half this way, the balls on the diagonal get cut in half, so to get the nth triangle number we need to include their other halves:
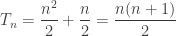
These numbers go like

and they are one of the simple pleasures of life, like sunshine and good bread. Spotting them in a knight-move zigzag pattern in the multiplication table was one of my first truly mathematical experiences. You can also see them in Pascal’s triangle:
because

But today it’s time to see how
If we subtract each triangular number from the the one before it we get the numbers 

Here we’re dividing instead of subtracting. But if take logarithms, we’ll be subtracting, and we get



What can we do with this? Well, suppose 
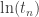
But since

or

This was my hope. But how good are these approximations? I left this as a puzzle on Google+, and then Greg Egan stepped in and solved it.
For starters, he graphed the ratio 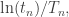
_over_T_n.jpg)
That looks pretty good: it looks like it’s approaching 1. But he also graphed the ratio 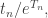
.jpg)
Not so good. Taking exponentials amplifies the errors. If we want a good asymptotic formula 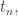
Digging deeper
So far we’ve talked a lot about
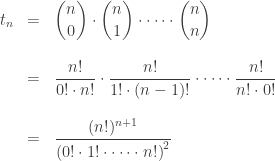
So, we’re seeing the superfactorial
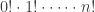
raise its pretty head. This is also called the Barnes G-function, presumably by people who want to make it sound more boring.
Actually that’s not fair: the Barnes G-function generalizes superfactorials to complex numbers, just as Euler’s gamma function generalizes factorials. Unfortunately, Euler made the mistake of defining his gamma function so that

when 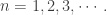
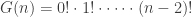
So, we’ll have to be careful when looking up formulas on Wikipedia: the superfactorial of n is 

so

Now, there’s a great approximate formula for the logarithm of a factorial. It’s worth its weight in gold… or at least silver, so it’s called Stirling’s formula:
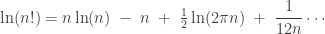
where the dots mean stuff that goes to zero when divided by the last term, in the limit

There’s also an approximate formula for the logarithm of the superfactorial! It’s a bit scary:

where the dots mean stuff that actually goes to zero as
What’s A? It’s the Glaisher–Kinkelin constant! If you’re tired of memorizing digits of pi and need a change of pace, you can look up the first 20,000 digits of the Glaisher–Kinkelin constant here, but roughly we have
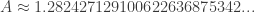
Of course most mathematicians don’t care much about the digits; what we really want to know is what this constant means!
Euler, who did some wacky nonrigorous calculations, once argued that
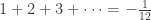
Riemann made this rigorous by defining

which converges when 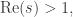


This fact has many marvelous ramifications: for example, it’s why bosonic string theory works best in 24 dimensions! It’s also connected to the 
But anyway, we might wonder what happens if we compute 

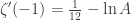
To me, this means that 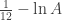

Now, let’s use this together with Stirling’s formula to estimate the logarithm of the product of all numbers in the nth row of Pascal’s triangle. Remember, that’s
So, we get
![\begin{array}{ccl} \ln(t_n) &\approx& \displaystyle{(n+1)\Big[ n \ln(n) - n + \tfrac{1}{2} \ln(2 \pi n) + \frac{1}{12n} \Big] } \\ \\ && - \displaystyle{ \Big[ \left( \ln(n+1) - \tfrac{3}{2}\right) (n+1)^2 + \ln(2\pi) \cdot (n+1) -} \\ \\ && \quad \displaystyle{ \tfrac{1}{6} \ln(n+1) + 2\zeta'(-1) \Big] } \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bccl%7D+%5Cln%28t_n%29+%26%5Capprox%26+%5Cdisplaystyle%7B%28n%2B1%29%5CBig%5B+n+%5Cln%28n%29+-+n+%2B+%5Ctfrac%7B1%7D%7B2%7D+%5Cln%282+%5Cpi+n%29+%2B+%5Cfrac%7B1%7D%7B12n%7D+%5CBig%5D+%7D+%5C%5C++%5C%5C++%26%26+-+%5Cdisplaystyle%7B+%5CBig%5B++%5Cleft%28+%5Cln%28n%2B1%29+-+%5Ctfrac%7B3%7D%7B2%7D%5Cright%29+%28n%2B1%29%5E2+%2B+%5Cln%282%5Cpi%29+%5Ccdot+%28n%2B1%29+-%7D+%5C%5C+%5C%5C++%26%26+%5Cquad+%5Cdisplaystyle%7B+++%5Ctfrac%7B1%7D%7B6%7D+%5Cln%28n%2B1%29+%2B+2%5Czeta%27%28-1%29+%5CBig%5D++%7D++%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
and exponentiating this gives a good approximation to
Here is a graph of

As you can see, the ratio goes to 1 quite nicely!
So, we’ve seem some nice relationships between these things:
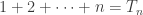

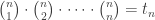
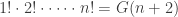
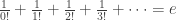
and Euler’s wacky formula
Puzzle 2. Can you take the formula
and massage it until it looks like 
References
Any errors in the formulas above are my fault. Here are the papers that first squeezed e out of Pascal’s triangle:
• Harlan J. Brothers, Pascal’s triangle: The hidden stor-e, The Mathematical Gazette, March 2012, 145.
• Harlan J. Brothers, Finding e in Pascal’s triangle, Mathematics Magazine 85 (2012), 51.
I learned the idea from here, thanks to Richard Elwes:
• Alexander Bogomolny, e in the Pascal Triangle, Interactive Mathematics Miscellany and Puzzles.
For how Euler derived his crazy identity
and how it’s relevant to string theory, try:
• John Baez, My favorite numbers: 24.


“You see, permuting the x’s or the y’s doesn’t change our choice, so we have divide[d] by and k! and (n-k)[!]” (coupla typos)
This symmetrical description of the 2-class case made me realize that I have always thought of it asymmetrically (as n!/(n-k)! ways of choosing k x’s, then dividing by k! if order irrelevant), even though I thought of the N-class case (for N>2) symmetrically. Maybe I subconsciously had trouble seeing a monomial and a binomial as peers. Duh (and thanks)!
Thanks! Typos fixed.
That Euler really had summability❢
I like that fat exclamation mark. I would like something of that sort as a notation for the hyperfactorial. Maybe something like this❗ Or this❣
Unicode 10082
There is also a hearty exclamation 10083
☞ http://inquiryintoinquiry.com/toolbox/
In the equation following “Now look:” the denominator in the RHS should be squared. It would be nice to label the lowest value (1) in the vertical axis of the last graph.
arch1 wrote:
Thanks—fixed!
True, but I’m not the one drawing the pictures here.
It is all very, very, interesting.


 constant values.
constant values.
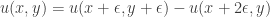



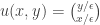
I am thinking that the Pascal’s triangle could be a solution of a differential equation, with one values along two direction, with a continuous solution on all the open triangle, and with integer value in the intersection grid that cover the Pascal’s triangle.
I am thinking that the binomial coefficients can be obtained from the relaxation equation:
that can be write in a differential form:
the complete differential equation have integer solution (like each differential equation with a border with an integer value) in a open triangle, along some axis with
It is possible to balance the equation on a vertex (with two Pascal rules):
so that:
I am thinking that can be possible to write a differential equation with infinite terms (a Polynomial differential equation), and I think that the not integer Binomial coefficient can be a solution in each real point of the triangle, so that
could be a solution (or it can be possible to evaluate a differential equation with this solution).
I am thinking that there is a class of differential equation (that is an approximation of a relaxation method) that solve a problem with a integer frontier, and that have integer solution on a grid (the solution of the differential Pascal equation is a real equation, with integer solution on a grid).
After originally writing this post I realized that because it’s not as complete as I’d like, I wanted to add this puzzle:
Puzzle: Can you take the formula
and massage it until it looks like plus ‘correction terms’? How big are these correction terms?
plus ‘correction terms’? How big are these correction terms?
Isn’t the nth triangular number ? I don’t think one can choose 2 things if there is only one thing to choose. Is there a way to see what numbers are hiding outside of the 1s in Pascal’s triangle?
? I don’t think one can choose 2 things if there is only one thing to choose. Is there a way to see what numbers are hiding outside of the 1s in Pascal’s triangle?
Aha, hybrid sets suggest that there are zeros outside of Pascal’s triangle. Above the triangle, however, is another triangle with a border of 1s. But this triangle has its zeros inside and its filling on the outside!
David wrote:
A typo there, maybe? It’s often defined as
and that’s the definition I’m using. This is the ‘big’ triangular where you chop a square of dots in half and keep the dots on the diagonal. There’s also the ‘small’ triangular number where you leave out those dots; that’s
The big triangular number is the number of states for a pair of identical bosons each of which can be in states. The The big triangular number is the number of states for a pair of identical fermions each of which can be in
states. The The big triangular number is the number of states for a pair of identical fermions each of which can be in  states.
states.
Very exciting. In the section named Triangular numbers, below the image of the Pascal Triangle, should be
should be  , since you’re using the ‘big’ triangular numbers.
, since you’re using the ‘big’ triangular numbers.
Also, there’s a nice way to see this: , and matches up to the diagrams showing the triangular numbers.
, and matches up to the diagrams showing the triangular numbers.
For n= 3, If you construct a 4X4 matrix with the elements being combinations of A,B,C,D, then the diagonal elements are not allowed and the table has to be symmetric. The lower or upper triangular matrix, excluding the diagonal, has all the possible combinations, i.e.
Arjun wrote:
Hi! Thanks for catching that mistake! Fixed.
Yes. This argument also generalizes to higher dimensions. For example, you can see that
is the nth tetrahedral number by looking at an n × n × n cube of numbers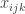 and counting the number of entries with
and counting the number of entries with 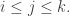
It’s perhaps easier to see that the ‘small’ tetrahedral number
counts the entries with since these corresponding to ways of picking a 3-element subset out of an n-element set.
since these corresponding to ways of picking a 3-element subset out of an n-element set.
The fun really starts when you use these ideas to think about identities like
since the left-hand side is a triangular number while the right-hand side is a tetrahedral number:
On the one hand, it’s obvious that
but on the other, it’s not obvious that there’s a systematic way to prove identities of this sort by rearranging piles of balls—for example, rearranging a triangle of 10 balls into a tetrahedron of 10 balls.
I think there’s a systematic (albeit recursive!) way of comparing arrangements of objects that represent equal generalised triangular numbers of different dimensions.
Define a generalised triangular number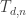 of dimension
of dimension  and size
and size  as the sum of the triangular numbers of up to the same size with dimension one lower:
as the sum of the triangular numbers of up to the same size with dimension one lower:
At dimension 1, define the number itself to be equal to its size:
Now, consider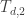 , which can be visualised as a
, which can be visualised as a  -dimensional pyramid of edge length 2, with one object at the origin and one object a unit distance away along each coordinate axis, for a total of
-dimensional pyramid of edge length 2, with one object at the origin and one object a unit distance away along each coordinate axis, for a total of 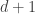 objects.
objects.
We can identify any set of this form with the one-dimensional set of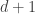 objects arranged at unit intervals along the coordinate axis, which corresponds to the triangular number
objects arranged at unit intervals along the coordinate axis, which corresponds to the triangular number 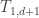 .
.
The relationship between triangular numbers of different dimensions that can be found via the symmetry of the binomial coefficient is:
and the identification we’ve just made:
is an example of that.
To extend the identification recursively, we need to look at two ways a triangular number can grow: when you increase its size, and when you increase its dimension.
When you increase the size of a triangular number, leaving the dimension the same, you’re just adding a triangular number of one lower dimension and one greater size to the original number:
This can be visualised as, say, adding a linear row of objects to a triangle to increase its size, or adding an extra triangle of objects to the base of a three-dimensional triangular pyramid, and so on.
When you increase the dimension of a triangular number, leaving its size the same, you’re doing essentially the same kind of gluing operation, but the roles of the original piece and the added piece are swapped: you add a piece of the new, higher dimension and a size one smaller than the original size.
For example, to increase the dimension of a 2-dimensional triangle of objects, you just treat that triangle as the base of a pyramid and stick on a pyramid one size smaller.
If we take our original identification between a triangular number of any dimension and size 2 and a 1-dimensional triangular number of size
and size 2 and a 1-dimensional triangular number of size 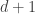 as a kind of primitive map, I believe we can recursively tear down any case of:
as a kind of primitive map, I believe we can recursively tear down any case of:
into multiple cases of that primitive map.
For example, we have:
We visualise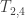 as a triangle of size 4, and
as a triangle of size 4, and 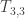 as a pyramid of size 3.
as a pyramid of size 3.
We break the triangle of size 4 into a triangle of size 3 and a linear row of size 4. We break the pyramid of size 3 into a triangle of size 3 and a pyramid of size 2.
Identifying the linear row of size 4 and the pyramid of size 2 is our primitive map.
The remaining pieces in this case are both triangles of size 3, but to be systematic we should continue breaking them down, one by size and one by dimension. So we break the first one into a triangle of size 2 and a linear row of size 3, and the second one into a linear row of size 3 and a triangle of size 2. Then we can identify each triangle of size 2 with a linear row of size 3 from the other pile.
I probably need to add a clearer description of the recursive decomposition of triangular numbers, because the formulas I gave previously were ways of building them up, rather than tearing them down.
To reiterate, the basic identity we get from the binomial coefficient is:
We can decompose the left-hand-side as:
and the right-hand side as:
In both cases, we’re just splitting off a lower-dimensional triangular number of the same size as the original, and leaving behind a piece of the original dimension that’s one size smaller. But we write the two equations above with the order of the pieces swapped, because the first items on the right of each equation are equal to each other, as are the second items. So we end up with two new comparisons:
and:
These are both just cases of the basic identity with different values for the dimension and size. And we just keep splitting things this way, with one of the dimensions growing smaller each time, until we end up with cases of:
That is, a linear row of size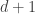 is equivalent to a pyramid of dimension
is equivalent to a pyramid of dimension  and size 2.
and size 2.
Greg wrote:
Great! Your description is a bit complicated, but I think this is inevitable. We’re trying to get a ‘bijective proof’ of the identity
where is the number of balls in a
is the number of balls in a  -dimensional simplex-shaped pyramid with
-dimensional simplex-shaped pyramid with  balls along each edge. And in this case the bijection is surprisingly subtle, even though the identity is elementary. I first heard the puzzle of describing this bijection from James Dolan.
balls along each edge. And in this case the bijection is surprisingly subtle, even though the identity is elementary. I first heard the puzzle of describing this bijection from James Dolan.
Here’s a very abstract way of describing it, which may unfold into your description if we try to make it explicit.
I’m going to use a standard trick that category theorists use for bijective proofs, and reuse standard notations for various numbers as notations for sets having these numbers as their cardinalities.
So, I’ll let
be the set of -element subsets of the set
-element subsets of the set 
There’s a bijection
sending each subset to its complement.
Let be the set of balls in a
be the set of balls in a  -dimensional pyramid with
-dimensional pyramid with  balls along each edge. This is a bit vague since it doesn’t give us a specific name for each ball—unlike my description of
balls along each edge. This is a bit vague since it doesn’t give us a specific name for each ball—unlike my description of 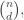 where we have a precise way to specify any subset, e.g.
where we have a precise way to specify any subset, e.g.
It can be hard to describe a bijection between sets if we don’t have names for the elements! However, we get a naming scheme for the balls in this pyramid if we think of this pyramid as the set of points
So that’s what I’ll do. This is neatly parallel to the fact that
Now, if we can describe a specific bijection
where , we’ll be done… since then we can compose bijections of the sort of we’ve found and get the bijection we’re looking for:
, we’ll be done… since then we can compose bijections of the sort of we’ve found and get the bijection we’re looking for:
(Here I’m leaving out all the fiddly little numbers on the s and
s and  s, since they can be reconstructed and they don’t matter much for getting the idea across.)
s, since they can be reconstructed and they don’t matter much for getting the idea across.)
Note that
is the set of -element subsets of
-element subsets of 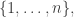 while
while
is the set of -element multisubsets of
-element multisubsets of 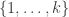 (meaning that elements can appear more than once). So, we just need an explicit bijection between these. And I think it’s not hard to find, but I’m getting sick of writing this!
(meaning that elements can appear more than once). So, we just need an explicit bijection between these. And I think it’s not hard to find, but I’m getting sick of writing this!
Anyway, this abstract approach is not really a substitute for a concrete description, just a strategy for finding such a concrete description.
Let’s see if the bijection between, say, 2-element multisubsets of {1,2,3} and 2-element subsets of {1,2,3,4} is evident.
Here are the 2-element multisubsets of {1,2,3}, where the elements included (perhaps more than once) are in bold:
1, 1, 2, 3
1, 2, 3
1, 2, 3
1, 2, 2, 3
1, 2, 3
1, 2, 3, 3
Here are the 2-element subsets of {1,2,3,4}, where the elements included are in bold:
1, 2, 3, 4
1, 2, 3, 4
1, 2, 3, 4
1, 2, 3, 4
1, 2, 3, 4
1, 2, 3, 4
We certainly get a bijection just by listing them both ‘lexicographically’ as I’ve done here, and then matching the first multisubset with the first subset, the second with the second etc. This is perfectly systematic and works in general to give a specific bijection
(using my previous notation). So, in a very abstract way, this completes my construction of a specific bijection
But it would be nice to describe this bijection a bit more directly, without listing everything… or some other bijection that does the job.
a bit more directly, without listing everything… or some other bijection that does the job.
I am not following this at all closely, so perhaps I’m missing something, such as the point of the exercise. The following seems like an explicit bijection.
Given an r-element subset of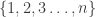 , write the elements out in increasing order:
, write the elements out in increasing order:
then subtract j-1 from the j'th number to get the multisets:
Graham, that certainly works! And it’s exactly equivalent to the lexicographic pairing. So it’s probably the most elegant way to convert between subsets and multisubsets.
The point of the exercise for me is to try to see why certain triangular numbers are equal. The identity is easy to prove, but it’s also nice to understand what’s happening geometrically and combinatorially.
Graham wrote:
Great—you just solved this problem:
As for the point of the exercise… the point of a getting a bijective proof of a combinatorial identity is that it brings us a step towards “categorifying” all of mathematics. Categorification doesn’t just mean “using categories”, it means something quite specific: replacing equations by isomorphisms. A bijective proof takes what had been a mere equation between numbers and boosts it up to an isomorphism between sets: that is, a 1-1 correspondence, or bijection.
Since numbers were invented to count sets, this is a way of bringing mathematics back to its roots. And in the hands of experts, isomorphisms are a lot more powerful than mere equations. An equation tells you two things are the same. An isomorphism says how.
But here we’re mainly just having fun, taking an identity that seems obvious:
reinterpreting it as a geometrical fact:
(where n = d+k-1), and then trying to get a direct geometrical way of seeing this latter fact… which amounts to a bijective proof.
If we couldn’t figure out how to do this, there’d be a hole in our understanding of binomial coefficients!
I thought of the map from multisubsets to subsets geometrically. A k-element multisubset X of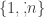 can be seen as a path on a grid (square lattice) from (1,0) to (n,k). The path goes up by the number of 1s in X, then along one unit to the right, then up by the number of 2s in X, and so on. The corresponding subset is the same but skewed, with the horizontals replaced by diagonals. I made a picture for John’s example at the bottom of http://www.azimuthproject.org/azimuth/show/Sandbox.
can be seen as a path on a grid (square lattice) from (1,0) to (n,k). The path goes up by the number of 1s in X, then along one unit to the right, then up by the number of 2s in X, and so on. The corresponding subset is the same but skewed, with the horizontals replaced by diagonals. I made a picture for John’s example at the bottom of http://www.azimuthproject.org/azimuth/show/Sandbox.
So each (hyper)cube in the pyramids can be labelled with paths.
Nice! That clarifies things a lot.
Ah, and if you flip Graham’s paths diagonally (that is, reverse the coordinates of each endpoint of a line segment in his two-dimensional diagram) you get a bijection that goes all the way through, from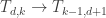 !
!
Actually, you can’t quite just flip the coordinates, if you want to start both paths at (1,0). But that’s just matter of tweaking the choice of coordinates; geometrically, the paths are flipped.
I don’t have time to draw a diagram of this right now, but it’s very easy to draw these paths by hand, and doing that for the first dimension-changing example:
… makes it easy to see what’s going on.
Using Graham’s path method, I figured out an explicit formula for the bijection:
If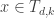 and
and  , the coordinates of
, the coordinates of  are given by:
are given by:
where is the count of the number of coordinates of
is the count of the number of coordinates of  that are equal to
that are equal to  .
.
Or to put this another way, is one more than the number of coordinates of
is one more than the number of coordinates of  that are less than or equal to
that are less than or equal to  .
.
Another way to describe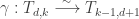 is by specifying the number of coordinates that take a given value.
is by specifying the number of coordinates that take a given value.
If , then the number of coordinates of
, then the number of coordinates of  that are equal to a certain value,
that are equal to a certain value,  , is:
, is:
where we define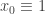 and
and  in addition to the actual coordinates
in addition to the actual coordinates  ,
,  .
.
There are two representations of a multisubset of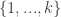 with length
with length  . One lists all the elements in ascending order, giving a
. One lists all the elements in ascending order, giving a  -tuple:
-tuple:
The other specifies the number of elements of each possible value, giving a -tuple:
-tuple:
The bijection between triangular numbers:
gives the “count representation” of one triangular number from a change of basis and origin of the “coordinate representation” of the other triangular number:
where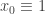 and
and  .
.
One more remark I should have added to my last comment: while the restriction on the “coordinate representation” of a multisubset is that the coordinates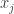 are positive integers in ascending order, the restriction on the “count representation” is that the counts
are positive integers in ascending order, the restriction on the “count representation” is that the counts 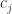 are non-negative integers that sum to the dimension of the coordinate representation. In other words, the
are non-negative integers that sum to the dimension of the coordinate representation. In other words, the 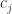 must lie in an affine hyperplane with the appropriate fixed value for their dot product with
must lie in an affine hyperplane with the appropriate fixed value for their dot product with 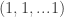 . And it’s easy to see that the formula:
. And it’s easy to see that the formula:
where:
will yield non-negative values for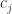 , and a dot product with
, and a dot product with 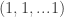 of
of  .
.
So what the bijection is doing is taking the -dimensional pyramid, changing the coordinates to embed it in the appropriate affine hyperplane, and then treating the new coordinates of each object in the pyramid as counts for the various values in the coordinates of each object of the
-dimensional pyramid, changing the coordinates to embed it in the appropriate affine hyperplane, and then treating the new coordinates of each object in the pyramid as counts for the various values in the coordinates of each object of the 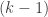 -dimensional pyramid.
-dimensional pyramid.
Cool! And it turns out that if I make the right choices, our definitions agree completely!
Using your lexicographical bijection, the composition of the three maps ends up taking a lexicographical ordering of into a reversed lexicographical ordering of
into a reversed lexicographical ordering of 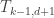 , because taking the complement of the subsets in the categorified binomial coefficients reverses their lexicographical order.
, because taking the complement of the subsets in the categorified binomial coefficients reverses their lexicographical order.
In my recursive approach, if I define the splitting of a triangular number by taking the lower-dimensional part to consist of those -tuples whose last coordinate (in the current dimension) is exactly equal to the size,
-tuples whose last coordinate (in the current dimension) is exactly equal to the size,  , the effect turns out to be the same as a kind of recursive lexicographical sort, and because I need to swap which part is mapped to which when I make the split, there’s a reversal of the ordering built into the process.
, the effect turns out to be the same as a kind of recursive lexicographical sort, and because I need to swap which part is mapped to which when I make the split, there’s a reversal of the ordering built into the process.
To make the agreement complete, I just need to choose my “primitive” bijection between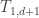 and
and 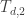 to be a reverse lexicographical map.
to be a reverse lexicographical map.
Oh, and I can drop my “primitive bijection” imposed by fiat and get exactly the same thing by continuing the recursion to a deeper level, if we define zero-dimensional triangular numbers as sets of one element:
I guess the most succinct way to describe the recursive approach is as follows. Define a triangular number of a given dimension as a disjoint union of triangular numbers of lower dimension:
with the recursive definition terminating at:
For any triangular number of dimension greater than zero, there is a natural way to cleave it into two disjoint parts. The first part has the same dimension and a smaller size:
The second part has the same size and a smaller dimension:
To establish a bijection between and
and 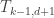 , we establish bijections between
, we establish bijections between  and
and  and between
and between 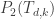 and
and 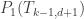 , with the process terminating when the pair of sets we want bijections between have cardinality 1.
, with the process terminating when the pair of sets we want bijections between have cardinality 1.
And if the triangular numbers are defined as multisubsets, this is the same as matching up two lexicographically sorted lists in reverse order.
There’s a way to use recursion to define the bijection:
where the binomial coefficient is defined as the set of subsets of
is defined as the set of subsets of  of size
of size  .
.
Just as we can cleave the triangular numbers into two parts, we can do the same with the binomial coefficients. We define:
and:
In the first case, is simply a subset of
is simply a subset of  . In the second case, we can embed
. In the second case, we can embed 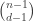 in
in  by adding the element
by adding the element  to every set in
to every set in 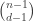 . So these two maps produce disjoint subsets that comprise the whole of
. So these two maps produce disjoint subsets that comprise the whole of  .
.
We then establish a bijection between and
and 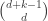 by establishing bijections between:
by establishing bijections between:
and
and between:
and
This recursive definition terminates when it calls for a bijection between two sets of cardinality 1.
Let me mention something one might try to do with the bijective proofs given above. Often bijective proofs can be copied in different contexts to gain new information.
I’ve been using
to mean, not the binomial coefficient, but a certain set whose size is that binomial coefficient: the set of -element subsets of
-element subsets of 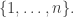 But this set corresponds to a basis of the
But this set corresponds to a basis of the  th exterior power of
th exterior power of 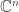 , usually called
, usually called 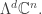 In quantum physics, this is the Hilbert space for
In quantum physics, this is the Hilbert space for  identical fermions each having
identical fermions each having  degrees of freedom.
degrees of freedom.
I’ve been using
to mean, not the number of balls in a -dimensional pyramid with edges of length
-dimensional pyramid with edges of length 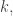 but a certain set whose size is that number: the set of
but a certain set whose size is that number: the set of  -element multisubsets of
-element multisubsets of 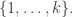 But this set corresponds to a basis of the
But this set corresponds to a basis of the  th symmetric power of
th symmetric power of  usually called
usually called  This is the Hilbert space for
This is the Hilbert space for  bosons each having
bosons each having  degrees of freedom.
degrees of freedom.
So, when we get our hands on a specific bijection
when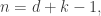 we also get an isomorphism of Hilbert spaces
we also get an isomorphism of Hilbert spaces
relating bosons and fermions. Is this good for something? I don’t know. But this is the kind of thing one can do.
If we subtract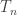 from the approximate formula for
from the approximate formula for 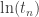 , we get correction terms:
, we get correction terms:
The “quadratic” term in (that is, the terms where an explicit
(that is, the terms where an explicit  is visible) is essentially linear:
is visible) is essentially linear:
However, the “linear” term in is dominated by a log times linear term:
is dominated by a log times linear term:
So the dominant correction term is:
followed by a linear correction term (including a contribution from the “quadratic” term):
This is followed by a log term:
and then a constant:
The rest of the correction goes to zero as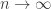
Just to clarify something, the plot for the ratio between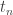 and the exponential of the approximation to
and the exponential of the approximation to 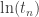 is not correct. I’ve emailed John the correct plot, but it’s the middle of the night in his current time zone.
is not correct. I’ve emailed John the correct plot, but it’s the middle of the night in his current time zone.
What I graphed in that plot was based on an approximation to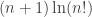 that differed from the one used in this blog post by a term
that differed from the one used in this blog post by a term 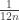 . Obviously the difference goes to zero, and both approximations are asymptotic formulas for the same thing, but in fact the version derived in the blog post yields a ratio that converges to 1 even faster than the version currently shown in the plot.
. Obviously the difference goes to zero, and both approximations are asymptotic formulas for the same thing, but in fact the version derived in the blog post yields a ratio that converges to 1 even faster than the version currently shown in the plot.
The old plot looked like this:
where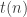 is what I’m now calling
is what I’m now calling 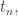 the product of all numbers in the nth row of Pascal’s triangle.
the product of all numbers in the nth row of Pascal’s triangle.
The new plot Greg sent me, showing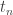 divided by the better approximation I actually give in my post, looks like this:
divided by the better approximation I actually give in my post, looks like this:
The converge is indeed much faster!
Very interesting! I had heard something about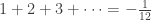 before, but I didn’t realize that it came straight from the Riemann zeta function (since I haven’t had a lot of experience with
before, but I didn’t realize that it came straight from the Riemann zeta function (since I haven’t had a lot of experience with  , unfortunately). Now I’ll have to investigate and see if I can understand why
, unfortunately). Now I’ll have to investigate and see if I can understand why  . :-)
. :-)
The formula given for just before Puzzle 2 seems to equal
just before Puzzle 2 seems to equal 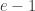 . It should probably be:
. It should probably be:
This kind of messes up its parallelism with the other formulas above it, but most of the other formulas could prepend an term/factor as well (aside from the definition of factorial, which obviously can’t start with a factor of zero).
term/factor as well (aside from the definition of factorial, which obviously can’t start with a factor of zero).
In particular, the formula for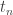 could prepend such a factor (thought it wouldn’t change the value), since
could prepend such a factor (thought it wouldn’t change the value), since  choose 0 is actually one of the values in the given row.
choose 0 is actually one of the values in the given row.
Terry Tao’s The Euler–Maclaurin formula, Bernoulli numbers, the zeta function, and real-variable analytic continuation is a good place to start reading.
(Hmm, that makes two Tao links on Azimuth by me in as many days.)
Spencer wrote:
Whoops, fixed! Yeah, that makes the parallelism a bit less cute. Oh well.
Instead of answering Puzzle 1 using the formula for the binomial coefficients, here’s a simple scenario that makes the result easy to see.
Suppose Alice is dealt cards from a deck of
cards from a deck of  solely black cards, and
solely black cards, and 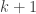 cards from a deck of
cards from a deck of  solely red ones.
solely red ones.
Bob gets exactly the same number of cards of each colour, but his cards are dealt from fresh decks of black cards and
black cards and  red ones.
red ones.
What is the ratio between the number of possible hands for Bob and the number of possible hands for Alice?
Because the numbers of cards are the same, in the ratio there’s no need to distinguish between combinations and permutations. So the difference comes down solely to the number of possibilities available as each card is dealt.
For the black cards, the number of possibilities for Bob’s first through to second-last cards agree with Alice’s second through to last, but he loses a factor of (Alice’s first card) while gaining a factor of
(Alice’s first card) while gaining a factor of 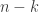 (his last card).
(his last card).
For the red cards, the numbers for Bob’s second through to last cards agree with Alice’s first through to second-last, but he gains a factor of (his first card) while losing a factor of
(his first card) while losing a factor of 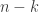 (Alice’s last card).
(Alice’s last card).
So overall, he gains a factor of , regardless of the value of
, regardless of the value of  .
.
These numbers can be seen in Pascal’s triangle by looking at the four corners of any “diamond” shape that surrounds a gap. For example, the diamond centred on the second gap of the fifth row has 3 at the top, 10 at the bottom, 4 on the left and 6 on the right. The product of the top and bottom corners divided by the product of the left and right corners is , and all diamonds in the same row have the same value.
, and all diamonds in the same row have the same value.
My contribution, a continuously variable aproximator to the binomial distribution offering full dynamic range for the variables n (number of permutables in the binomial set) and p (skew or bias of the distribution). I think this expression should be attributed to Abraham de Moivre.
DeMoivre1733 = (2.0/Sqrt[
2.0*\[Pi]*n])*(E^-(((Subscript[X, peak] – X)^2)/(n/2.0)))
(Obviously, I’m not knowing the best way to copy and paste an equation out of a Mathematica Notebook onto a Word Press blog article)
Joel, approximating the binomial coefficients with a Gaussian sounds like a good idea! I tried it out myself initially. But if you work through the calculations, the product of the Gaussian approximations for each row of Pascal’s triangle turns out not to be asymptotic to the product of the actual binomial coefficients.
I believe this is because the approximation works very well around the mean, but not so well at the tails, and while that doesn’t matter much if you’re summing the terms (which are small at the tails), when you’re taking their product it leads to large discrepancies.
Greg- I used the Table function in Mathematica to test De Moivre’s Approximator against Jacob Bernoulli’s Exact Function. Here are my results for n ranging from 1 through 10.
Bernoulli 0.5, De Moivre 0.798 | Bernoulli 0.5, De Moivre 0.564 | Bernoulli 0.375, De Moivre 0.461 | Bernoulli 0.375, De Moivre 0.399 | Bern 0.312, De M 0.357 | Bern 0.312, De M 0.326, | Bern 0.273, De M 0.302 | Bern 0.273, De M 0.282 | Bern 0.246, De M 0.266 | Bern 0.246, De M 0.252 |
The way I do it the approximation improves with increasing n. My goal is to set a lower bound on the number of genes having an influence on any given biological manifestation. So, for example, if the bell curve for adult height solves to a 12 element binomial (13 columns) I think that implies a minimum of 12 genes with an influence on cell production rate.
Joel, you’ve given a list of evaluations of the binomial probability distribution at the mean (or the integers either side of the mean), and the Gaussian approximation to that distribution at the mean. And sure, these values at the mean get closer together as n increases.
Unfortunately, though, that doesn’t help us obtain a good approximation for the product of all the numbers in each row of Pascal’s triangle, which is the aim of the calculations in this blog post. For n=1,..,10, the ratio between the actual product and the product of the numbers you get from the Gaussian approximation takes the values: 1.06747, 1.28577, 1.36777, 1.3446, 1.237, 1.07058, 0.87397, 0.674019, 0.49155, 0.339207. The limit of this ratio for large n turns out to be zero.
So, alas, this is one problem where the approximation you’ve described is not applicable.
Pi appears in Pascal’s triangle.
An unusual series that produces pi was discovered by Jonas Castillo Toloza in 2007; the series consists of the reciprocals of the triangular numbers and, as such, could be detected in Pascal’s triangle.
http://www.cut-the-knot.org/arithmetic/algebra/TriPiInPascal.shtml