In these posts, we’re seeing how our favorite theories of physics deal with the idea that space and time are a continuum, with points described as lists of real numbers. We’re not asking if this idea is true: there’s no clinching evidence to answer that question, so it’s too easy to let ones philosophical prejudices choose the answer. Instead, we’re looking to see what problems this idea causes, and how physicists have struggled to solve them.
We started with the Newtonian mechanics of point particles attracting each other with an inverse square force law. We found strange ‘runaway solutions’ where particles shoot to infinity in a finite amount of time by converting an infinite amount of potential energy into kinetic energy.
Then we added quantum mechanics, and we saw this problem went away, thanks to the uncertainty principle.
Now let’s take away quantum mechanics and add special relativity. Now our particles can’t go faster than light. Does this help?
Point particles interacting with the electromagnetic field
Special relativity prohibits instantaneous action at a distance. Thus, most physicists believe that special relativity requires that forces be carried by fields, with disturbances in these fields propagating no faster than the speed of light. The argument for this is not watertight, but we seem to actually see charged particles transmitting forces via a field, the electromagnetic field—that is, light. So, most work on relativistic interactions brings in fields.
Classically, charged point particles interacting with the electromagnetic field are described by two sets of equations: Maxwell’s equations and the Lorentz force law. The first are a set of differential equations involving:
• the electric field 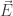
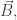
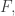
• the electric charge density 


By themselves, these equations are not enough to completely determine the future given initial conditions. In fact, you can choose 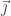

For any such choice, there exists a solution of Maxwell’s equations for 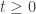

Thus, to determine the future given initial conditions, we also need equations that say what 


where 
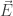

The trouble starts when we try to combine Maxwell’s equations and the Lorentz force law in a consistent way, with the goal being to predict the future behavior of the 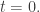
The first sign of a difficulty is this: the charge density and current associated to a charged particle are singular, vanishing off the curve it traces out in spacetime but ‘infinite’ on this curve. For example, a charged particle at rest at the origin has

where 
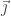

where 
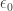
In short, the electric field is ‘infinite’, or undefined, at the particle’s location. So, it is unclear how to define the ‘self-force’ exerted by the particle’s own electric field on itself. The formula for the electric field produced by a static point charge is really just our old friend, the inverse square law. Since we had previously ignored the force of a particle on itself, we might try to continue this tactic now. However, other problems intrude.
In relativistic electrodynamics, the electric field has energy density equal to

Thus, the total energy of the electric field of a point charge at rest is proportional to
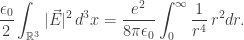
But this integral diverges near 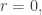
How, if at all, does this cause trouble when we try to unify Maxwell’s equations and the Lorentz force law? It helps to step back in history. In 1902, the physicist Max Abraham assumed that instead of a point, an electron is a sphere of radius 
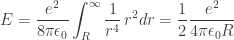
where
Abraham also computed the extra momentum a moving electron of this sort acquires due to its electromagnetic field. He got it wrong because he didn’t understand Lorentz transformations. In 1904 Lorentz did the calculation right. Using the relationship between velocity, momentum and mass, we can derive from his result a formula for the ‘electromagnetic mass’ of the electron:

where 
Putting the last two equations together, these physicists obtained a remarkable result:
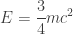
Then, in 1905, a fellow named Einstein came along and made it clear that the only reasonable relation between energy and mass is

What had gone wrong?
In 1906, Poincaré figured out the problem. It is not a computational mistake, nor a failure to properly take special relativity into account. The problem is that like charges repel, so if the electron were a sphere of charge it would explode without something to hold it together. And that something—whatever it is—might have energy. But their calculation ignored that extra energy.
In short, the picture of the electron as a tiny sphere of charge, with nothing holding it together, is incomplete. And the calculation showing 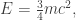

Nonetheless it is interesting to take the energy 
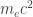
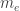

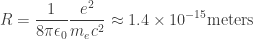
In the early 1900s, this would have been a remarkably tiny distance: 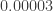
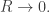
First, the electromagnetic field energy approaches 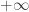


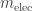
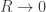


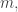
Second, it is wise to include conservation of energy-momentum as a requirement in addition to Maxwell’s equations and the Lorentz force law. Here is a more sophisticated way to phrase Poincaré’s realization. From the electromagnetic field one can compute a ‘stress-energy tensor’ 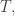

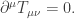
So far we have only discussed the simplest situation: a single charged particle at rest, or moving at a constant velocity. To go further, we can try to compute the acceleration of a small charged sphere in an arbitrary electromagnetic field. Then, by taking the limit as the radius 
In fact this whole program is fraught with difficulties, but physicists boldly go where mathematicians fear to tread, and in a rough way this program was carried out already by Abraham in 1905. His treatment of special relativistic effects was wrong, but these were easily corrected; the real difficulties lie elsewhere. In 1938 his calculations were carried out much more carefully—though still not rigorously—by Dirac. The resulting law of motion is thus called the ‘Abraham–Lorentz–Dirac force law’.
There are three key ways in which this law differs from our earlier naive statement of the Lorentz force law:
• We must decompose the electromagnetic field in two parts, the ‘external’ electromagnetic field 
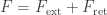
Here 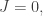
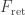





• Maxwell’s equations say that an accelerating charged particle emits radiation, which carries energy-momentum. Conservation of energy-momentum implies that there is a compensating force on the charged particle. This is called the ‘radiation reaction’. So, in addition to the Lorentz force, there is a radiation reaction force.
• As we take the limit 
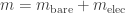
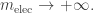
It is easiest to describe the Abraham–Lorentz–Dirac force law using standard relativistic notation. So, we switch to units where 

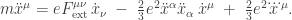
The first term at right is the Lorentz force, which looks more elegant in this new notation. The second term is fairly intuitive: it acts to reduce the particle’s velocity at a rate proportional to its velocity (as one would expect from friction), but also proportional to the squared magnitude of its acceleration. This is the ‘radiation reaction’.
The last term, called the ‘Schott term’, is the most shocking. Unlike all familiar laws in classical mechanics, it involves the third derivative of the particle’s position!
This seems to shatter our original hope of predicting the electromagnetic field and the particle’s position and velocity given their initial values. Now it seems we need to specify the particle’s initial position, velocity and acceleration.
Furthermore, unlike Maxwell’s equations and the original Lorentz force law, the Abraham–Lorentz–Dirac force law is not symmetric under time reversal. If we take a solution and replace 
The reason is that our assumptions have explicitly broken time symmetry. The splitting 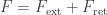

Worse, the Abraham–Lorentz–Dirac force law has counterintuitive solutions. Suppose for example that 
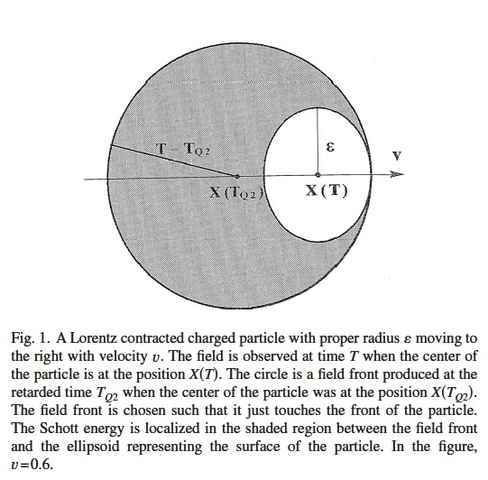
So, the notion that special relativity might help us avoid the pathologies of Newtonian point particles interacting gravitationally—five-body solutions where particles shoot to infinity in finite time—is cruelly mocked by the Abraham–Lorentz–Dirac force law. Particles cannot move faster than light, but even a single particle can extract an arbitrary amount of energy-momentum from the electromagnetic field in its immediate vicinity and use this to propel itself forward at speeds approaching that of light. The energy stored in the field near the particle is sometimes called ‘Schott energy’.
Thanks to the Schott term in the Abraham–Lorentz–Dirac force law, the Schott energy can be converted into kinetic energy for the particle. The details of how this work are nicely discussed in a paper by Øyvind Grøn, so click the link and read that if you’re interested. I’ll just show you a picture from that paper:
So even one particle can do crazy things! But worse, suppose we generalize the framework to include more than one particle. The arguments for the Abraham–Lorentz–Dirac force law can be generalized to this case. The result is simply that each particle obeys this law with an external field
This fact was discovered by C. Jayaratnam Eliezer in 1943. It is so counterintuitive that several proofs were required before physicists believed it.
None of these strange phenomena have ever been seen experimentally. Faced with this problem, physicists have naturally looked for ways out. First, why not simply cross out the 

has only trivial solutions. The reason is that with the particle’s path parametrized by proper time, the vector 


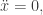
Another possibility is that some assumption made in deriving the Abraham–Lorentz–Dirac force law is incorrect. Of course the theory is physically incorrect, in that it ignores quantum mechanics and other things, but that is not the issue. The issue here is one of mathematical physics, of trying to formulate a well-behaved classical theory that describes charged point particles interacting with the electromagnetic field. If we can prove this is impossible, we will have learned something. But perhaps there is a loophole. The original arguments for the Abraham–Lorentz–Dirac force law are by no means mathematically rigorous. They involve a delicate limiting procedure, and approximations that were believed, but not proved, to become perfectly accurate in the 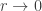
Calculations involving a spherical shell of charge has been improved by a series of authors, and nicely summarized by Fritz Rohrlich. In all these calculations, nonlinear powers of the acceleration and its time derivatives are neglected, and one hopes this is acceptable in the
Dirac, struggling with renormalization in quantum field theory, took a different tack. Instead of considering a sphere of charge, he treated the electron as a point from the very start. However, he studied the flow of energy-momentum across the surface of a tube of radius
Since this work, many authors have tried to simplify Dirac’s rather complicated calculations and clarify his assumptions. This book is a good guide:
• Stephen Parrott, Relativistic Electrodynamics and Differential Geometry, Springer, Berlin, 1987.
But more recently, Jerzy Kijowski and some coauthors have made impressive progress in a series of papers that solve many of the problems we have described.
Kijowski’s key idea is to impose conditions on precisely how the electromagnetic field is allowed to behave near the path traced out by a charged point particle. He breaks the field into a ‘regular’ part and a ‘singular’ part:
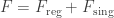
Here 
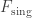

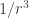
On the one hand, this eliminates the ambiguities mentioned earlier: in the end, there are no ‘nonlinear powers of the acceleration and its time derivatives’ in Kijowski’s force law. On the other hand, this avoids breaking time reversal symmetry, as the earlier splitting 
Next, Kijowski defines the energy-momentum of a point particle to be 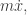

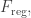
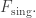
This equation is very simple:
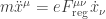
It is just the Lorentz force law! Since the troubling Schott term is gone, this is a second-order differential equation. So we can hope that to predict the future behavior of the electromagnetic field, together with the particle’s position and velocity, given all these quantities at
And indeed this is true! In 1998, together with Gittel and Zeidler, Kijowski proved that initial data of this sort, obeying the careful restrictions on allowed singularities of the electromagnetic field, determine a unique solution of Maxwell’s equations and the Lorentz force law, at least for a short amount of time. Even better, all this remains true for any number of particles.
There are some obvious questions to ask about this new approach. In the Abraham–Lorentz–Dirac force law, the acceleration was an independent variable that needed to be specified at 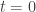
We mentioned that the singular part of the electromagnetic field, 
Another question is: where did the radiation reaction go? The answer is: we can see it if we go back and decompose the electromagnetic field as 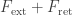
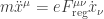
and rewrite it in terms of 
Unfortunately, this means that ‘pathological’ solutions where particles extract arbitrary amounts of energy from the electromagnetic field are still possible. A related problem is that apparently nobody has yet proved solutions exist for all time. Perhaps a singularity worse than the allowed kind could develop in a finite amount of time—for example, when particles collide.
So, classical point particles interacting with the electromagnetic field still present serious challenges to the physicist and mathematician. When you have an infinitely small charged particle right next to its own infinitely strong electromagnetic field, trouble can break out very easily!
Particles without fields
Finally, I should also mention attempts, working within the framework of special relativity, to get rid of fields and have particles interact with each other directly. For example, in 1903 Schwarzschild introduced a framework in which charged particles exert an electromagnetic force on each other, with no mention of fields. In this setup, forces are transmitted not instantaneously but at the speed of light: the force on one particle at one spacetime point 

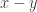
• Each particle exerts forces only on other particles, so we avoid the thorny issue of how a point particle responds to the electromagnetic field produced by itself.
• There are no electromagnetic fields not produced by particles: for example, the theory does not describe the motion of a charged particle in an ‘external electromagnetic field’.
• The principle of least action guarantees that ‘if 

Besides the reverse causality issue, perhaps one reason this approach has not been more pursued is that it does not admit a Hamiltonian formulation in terms of particle positions and momenta. Indeed, there are a number of ‘no-go theorems’ for relativistic multiparticle Hamiltonians, saying that these can only describe noninteracting particles. So, most work that takes both quantum mechanics and special relativity into account uses fields.
Indeed, in quantum electrodynamics, even the charged point particles are replaced by fields—namely quantum fields! Next time we’ll see whether that helps.
• Part 1: introduction; the classical mechanics of gravitating point particles.
• Part 2: the quantum mechanics of point particles.
• Part 3: classical point particles interacting with the electromagnetic field.
• Part 4: quantum electrodynamics.
• Part 5: renormalization in quantum electrodynamics.
• Part 6: summing the power series in quantum electrodynamics.
• Part 7: singularities in general relativity.
• Part 8: cosmic censorship in general relativity; conclusions.



 Posted by John Baez
Posted by John Baez 
 to every statement that is neither provable nor disprovable.
to every statement that is neither provable nor disprovable. 
 to mean the statement
to mean the statement  is provable from the Peano axioms of arithmetic. Gödel figured out how to encode statements in arithmetic as numbers, so let’s write
is provable from the Peano axioms of arithmetic. Gödel figured out how to encode statements in arithmetic as numbers, so let’s write 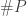 for the Gödel number of any statement
for the Gödel number of any statement 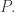 And Gödel figured out how to write a statement in arithmetic, say
And Gödel figured out how to write a statement in arithmetic, say 
 is provable using the Peano axioms.
is provable using the Peano axioms. So, this sentence says
So, this sentence says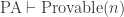

 You might want it to trust itself. In other words, you might want
You might want it to trust itself. In other words, you might want 

 extending
extending  where each
where each  , then all the
, then all the  and all the theories are sound for
and all the theories are sound for  sentences—that is, sentences with only one
sentences—that is, sentences with only one  quantifier outside the rest of the stuff.
quantifier outside the rest of the stuff.

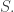 For example, in Keller and Urban’s model,
For example, in Keller and Urban’s model,  is a list of 18 numbers. To keep things simple, suppose the settings are element of some finite set. Suppose we also have huge hard disc full of historical measurements, and we want to use this to find the best estimate of
is a list of 18 numbers. To keep things simple, suppose the settings are element of some finite set. Suppose we also have huge hard disc full of historical measurements, and we want to use this to find the best estimate of  given that the measurements take some value. Let’s call the measurements
given that the measurements take some value. Let’s call the measurements  , and again let’s keep things simple by saying
, and again let’s keep things simple by saying 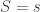 given that
given that 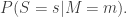 How can we compute this conditional probability? This is a somewhat tricky problem.
How can we compute this conditional probability? This is a somewhat tricky problem.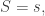 the model predicts measurements
the model predicts measurements 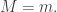 This again is a conditional probability, but now it is called
This again is a conditional probability, but now it is called 
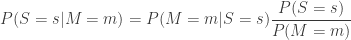
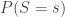 is the probability that the settings take a specific value
is the probability that the settings take a specific value 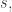 and similarly for
and similarly for 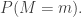 Bayes’ rule is quite easy to prove, and it is actually a general rule that applies to any random variables, not just the settings and the measurements in our problem [Y]. It underpins most methods of figuring out hidden quantities from observed ones. For this reason, it is widely used in modern statistics and data analysis [K].
Bayes’ rule is quite easy to prove, and it is actually a general rule that applies to any random variables, not just the settings and the measurements in our problem [Y]. It underpins most methods of figuring out hidden quantities from observed ones. For this reason, it is widely used in modern statistics and data analysis [K].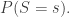 As mentioned, we can compute
As mentioned, we can compute  Finally,
Finally,  is independent of our choice of settings. So, we can use Bayes’ rule to compute
is independent of our choice of settings. So, we can use Bayes’ rule to compute  up to a constant factor. And since probabilities must sum to 1, we can figure out this constant.
up to a constant factor. And since probabilities must sum to 1, we can figure out this constant. related by
related by
 is some ‘noise’: an independent Gaussian random variable for each time
is some ‘noise’: an independent Gaussian random variable for each time  each with mean zero and some fixed standard deviation. Then the measurements
each with mean zero and some fixed standard deviation. Then the measurements  will have roughly sinusoidal behavior but with irregularity added by the noise at each time step, as illustrated in Figure 2.
will have roughly sinusoidal behavior but with irregularity added by the noise at each time step, as illustrated in Figure 2. 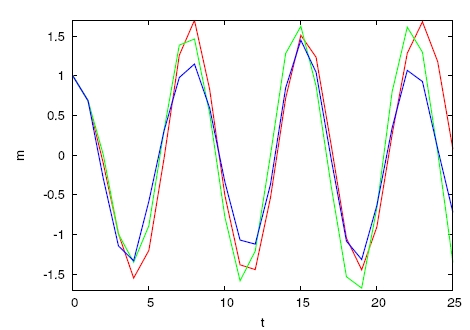

 how do we actually do this? The simplest way would be to run our model many, many times with the settings set at
how do we actually do this? The simplest way would be to run our model many, many times with the settings set at  and determine the fraction of times it predicts measurements equal to
and determine the fraction of times it predicts measurements equal to  This gives us an estimate of
This gives us an estimate of  Then we can use Bayes’ rule to work out
Then we can use Bayes’ rule to work out  at least up to a constant factor.
at least up to a constant factor.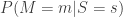 as a function of
as a function of 
 as a function of
as a function of 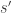 to the current settings
to the current settings 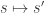 is randomly accepted with a probability equal to the ratio
is randomly accepted with a probability equal to the ratio
 in our example.
in our example.
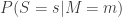 curves using Markov Chain Monte Carlo, showing the current distribution estimate at increasing intervals. The red line shows the current position of the random walk. Again the kinks are almost gone in the final distribution.
curves using Markov Chain Monte Carlo, showing the current distribution estimate at increasing intervals. The red line shows the current position of the random walk. Again the kinks are almost gone in the final distribution.

 and less than
and less than  , where
, where  Is that okay?
Is that okay? in first-order logic that lets us talk about natural numbers and also rational numbers. Let
in first-order logic that lets us talk about natural numbers and also rational numbers. Let 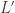 be the language
be the language 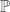 thrown in. We require that
thrown in. We require that  be a rational number whenever
be a rational number whenever 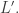 How can we say that the probability function
How can we say that the probability function  is the measure of the set of models in which
is the measure of the set of models in which  is satisfied. They show that
is satisfied. They show that  for all sentences
for all sentences 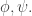
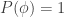 for each tautology.
for each tautology.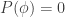 for each contradiction.
for each contradiction.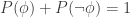 and thus 3). So either they’re giving a slightly redundant list of conditions because they feel in the mood for it, or they didn’t notice this list was redundant, or it’s not and I’m confused. It’s good to always say a list of conditions is redundant if you know it is. You may be trying to help your readers a bit, and it may seem obvious to you, but it you don’t come out and admit the redundancy, you’ll make some of your readers doubt their sanity.)
and thus 3). So either they’re giving a slightly redundant list of conditions because they feel in the mood for it, or they didn’t notice this list was redundant, or it’s not and I’m confused. It’s good to always say a list of conditions is redundant if you know it is. You may be trying to help your readers a bit, and it may seem obvious to you, but it you don’t come out and admit the redundancy, you’ll make some of your readers doubt their sanity.)

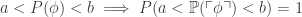
 is the Gödel number of the sentence
is the Gödel number of the sentence 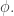 So, this principle says that if a sentence has some approximate probability of being true, the thinker—as described by
So, this principle says that if a sentence has some approximate probability of being true, the thinker—as described by 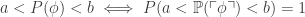
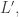 such that
such that


