Last time I ended with a formula for the ‘Gibbs distribution’: the probability distribution that maximizes entropy subject to constraints on the expected values of some observables.
This formula is well-known, but I’d like to derive it here. My argument won’t be up to the highest standards of rigor: I’ll do a bunch of computations, and it would take more work to state conditions under which these computations are justified. But even a nonrigorous approach is worthwhile, since the computations will give us more than the mere formula for the Gibbs distribution.
I’ll start by reminding you of what I claimed last time. I’ll state it in a way that removes all unnecessary distractions, so go back to Part 20 if you want more explanation.
The Gibbs distribution
Take a measure space  with measure
with measure 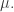 Suppose there is a probability distribution
Suppose there is a probability distribution  on that maximizes the entropy
on that maximizes the entropy

subject to the requirement that some integrable functions  on have expected values equal to some chosen list of numbers
on have expected values equal to some chosen list of numbers 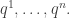
(Unlike last time, now I’m writing 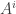 and
and 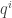 with superscripts rather than subscripts, because I’ll be using the Einstein summation convention: I’ll sum over any repeated index that appears once as a a superscript and once as a subscript.)
with superscripts rather than subscripts, because I’ll be using the Einstein summation convention: I’ll sum over any repeated index that appears once as a a superscript and once as a subscript.)
Furthermore, suppose depends smoothly on  I’ll call it
I’ll call it  to indicate its dependence on
to indicate its dependence on  Then, I claim is the so-called Gibbs distribution
Then, I claim is the so-called Gibbs distribution
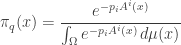
where
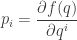
and
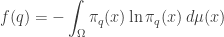
is the entropy of 
Let’s show this is true!
Finding the Gibbs distribution
So, we are trying to find a probability distribution that maximizes entropy subject to these constraints:

We can solve this problem using Lagrange multipliers. We need one Lagrange multiplier, say  for each of the above constraints. But it’s easiest if we start by letting range over all of
for each of the above constraints. But it’s easiest if we start by letting range over all of 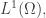 that is, the space of all integrable functions on
that is, the space of all integrable functions on  Then, because we want to be a probability distribution, we need to impose one extra constraint
Then, because we want to be a probability distribution, we need to impose one extra constraint
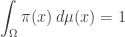
To do this we need an extra Lagrange multiplier, say 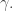
So, that’s what we’ll do! We’ll look for critical points of this function on 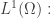
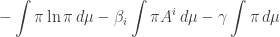
Here I’m using some tricks to keep things short. First, I’m dropping the dummy variable x which appeared in all of the integrals we had: I’m leaving it implicit. Second, all my integrals are over so I won’t say that. And third, I’m using the Einstein summation convention, so there’s a sum over i implicit here.
Okay, now let’s do the variational derivative required to find a critical point of this function. When I was a math major taking physics classes, the way physicists did variational derivatives seemed like black magic to me. Then I spent months reading how mathematicians rigorously justified these techniques. I don’t feel like a massive digression into this right now, so I’ll just do the calculations—and if they seem like black magic, I’m sorry!
We need to find obeying
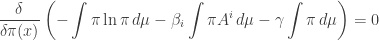
or in other words
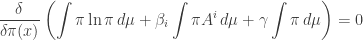
First we need to simplify this expression. The only part that takes any work, if you know how to do variational derivatives, is the first term. Since the derivative of 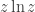 is
is  we have
we have
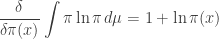
The second and third terms are easy, so we get
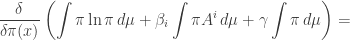
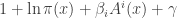
Thus, we need to solve this equation:

That’s easy to do:
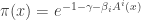
Good! It’s starting to look like the Gibbs distribution!
We now need to choose the Lagrange multipliers 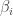 and
and  to make the constraints hold. To satisfy this constraint
to make the constraints hold. To satisfy this constraint

we must choose so that

or in other words
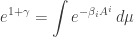
Plugging this into our earlier formula
we get this:

Great! Even more like the Gibbs distribution!
By the way, you must have noticed the “1” that showed up here:
It buzzed around like an annoying fly in the otherwise beautiful calculation, but eventually went away. This is the same irksome “1” that showed up in Part 19. Someday I’d like to say a bit more about it.
Now, where were we? We were trying to show that
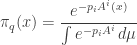
minimizes entropy subject to our constraints. So far we’ve shown
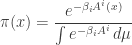
is a critical point. It’s clear that
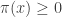
so really is a probability distribution. We should show it actually maximizes entropy subject to our constraints, but I will skip that. Given that, will be our claimed Gibbs distribution if we can show

This is interesting! It’s saying our Lagrange multipliers actually equal the so-called conjugate variables  given by
given by
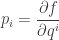
where 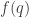 is the entropy of
is the entropy of 
There are two ways to show this: the easy way and the hard way. The easy way is to reflect on the meaning of Lagrange multipliers, and I’ll sketch that way first. The hard way is to use brute force: just compute and show it equals 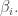 This is a good test of our computational muscle—but more importantly, it will help us discover some interesting facts about the Gibbs distribution.
This is a good test of our computational muscle—but more importantly, it will help us discover some interesting facts about the Gibbs distribution.
The easy way
Consider a simple Lagrange multiplier problem where you’re trying to find a critical point of a smooth function
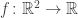
subject to the constraint
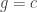
for some smooth function
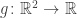
and constant c. (The function f here has nothing to do with the f in the previous sections.) To answer this we introduce a Lagrange multiplier  and seek points where
and seek points where
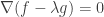
This works because the above equation says

Geometrically this means we’re at a point where the gradient of  points at right angles to the level surface of
points at right angles to the level surface of 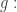

Thus, to first order we can’t change by moving along the level surface of 
But also, if we start at a point where
and we begin moving in any direction, the function will change at a rate equal to times the rate of change of  . That’s just what the equation says! And this fact gives a conceptual meaning to the Lagrange multiplier
. That’s just what the equation says! And this fact gives a conceptual meaning to the Lagrange multiplier 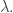
Our situation is more complicated, since our functions are defined on the infinite-dimensional space and we have an n-tuple of constraints with an n-tuple of Lagrange multipliers. But the same principle holds.
So, when we are at a solution of our constrained entropy-maximization problem, and we start moving the point by changing the value of the ith constraint, namely  the rate at which the entropy changes will be times the rate of change of
the rate at which the entropy changes will be times the rate of change of  So, we have
So, we have
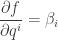
But this is just what we needed to show!
The hard way
Here’s another way to show
We start by solving our constrained entropy-maximization problem using Lagrange multipliers. As already shown, we get
Then we’ll compute the entropy
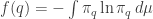
Then we’ll differentiate this with respect to 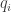 and show we get
and show we get
Let’s try it! The calculation is a bit heavy, so let’s write 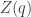 for the so-called partition function
for the so-called partition function

so that
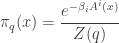
and the entropy is

This is the sum of two terms. The first term
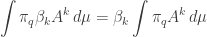
is  times the expected value of
times the expected value of 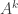 with respect to the probability distribution
with respect to the probability distribution 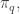 all summed over
all summed over  But the expected value of is
But the expected value of is 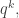 so we get
so we get

The second term is easier:
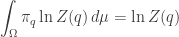
since  integrates to 1 and the partition function doesn’t depend on
integrates to 1 and the partition function doesn’t depend on 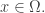
Putting together these two terms we get an interesting formula for the entropy:

This formula is one reason this brute-force approach is actually worthwhile! I’ll say more about it later.
But for now, let’s use this formula to show what we’re trying to show, namely
For starters,

where we played a little Kronecker delta game with the second term.
Now we just need to compute the third term:

Ah, you don’t know how good it feels, after years of category theory, to be doing calculations like this again!
Now we can finish the job we started:
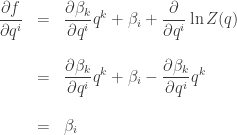
Voilà!
Conclusions
We’ve learned the formula for the probability distribution that maximizes entropy subject to some constraints on the expected values of observables. But more importantly, we’ve seen that the anonymous Lagrange multipliers that show up in this problem are actually the partial derivatives of entropy! They equal

Thus, they are rich in meaning. From what we’ve seen earlier, they are ‘surprisals’. They are analogous to momentum in classical mechanics and have the meaning of intensive variables in thermodynamics:
|
Classical Mechanics |
Thermodynamics |
Probability Theory |
| q |
position |
extensive variables |
probabilities |
| p |
momentum |
intensive variables |
surprisals |
| S |
action |
entropy |
Shannon entropy |
Furthermore, by showing 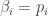 the hard way we discovered an interesting fact. There’s a relation between the entropy and the logarithm of the partition function:
the hard way we discovered an interesting fact. There’s a relation between the entropy and the logarithm of the partition function:
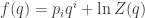
(We proved this formula with replacing 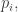 but now we know those are equal.)
but now we know those are equal.)
This formula suggests that the logarithm of the partition function is important—and it is! It’s closely related to the concept of free energy—even though ‘energy’, free or otherwise, doesn’t show up at the level of generality we’re working at now.
This formula should also remind you of the tautological 1-form on the cotangent bundle  namely
namely
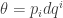
It should remind you even more of the contact 1-form on the contact manifold  namely
namely
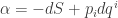
Here  is a coordinate on the contact manifold that’s a kind of abstract stand-in for our entropy function
is a coordinate on the contact manifold that’s a kind of abstract stand-in for our entropy function 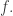
So, it’s clear there’s a lot more to say: we’re seeing hints of things here and there, but not yet the full picture.
For all my old posts on information geometry, go here:
• Information geometry.




 Posted by John Baez
Posted by John Baez 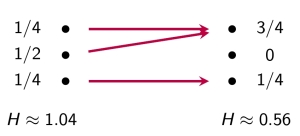

 equipped with a map sending each point
equipped with a map sending each point 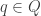 to a probability distribution
to a probability distribution 

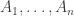 whose expected values serve as coordinates
whose expected values serve as coordinates  for points
for points 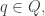 and
and  is
is  We can derive most of the interesting formulas of thermodynamics starting from this!
We can derive most of the interesting formulas of thermodynamics starting from this! which I’ll call
which I’ll call 

 This is the basic idea behind
This is the basic idea behind 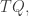 which is important in Amari’s approach to information geometry. You can read about this here:
which is important in Amari’s approach to information geometry. You can read about this here:
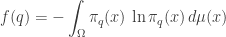

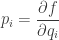
 this way gives a Lagrangian submanifold
this way gives a Lagrangian submanifold
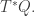 We can also get contact geometry into the game by defining a contact manifold
We can also get contact geometry into the game by defining a contact manifold  and a Legendrian submanifold
and a Legendrian submanifold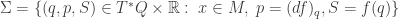


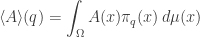
 is a function whose value at at any point
is a function whose value at at any point  with respect to the probability distribution
with respect to the probability distribution  Their expected values will be smooth functions on our manifold—and sometimes these functions will be a coordinate system!
Their expected values will be smooth functions on our manifold—and sometimes these functions will be a coordinate system! such that the differentials of the functions
such that the differentials of the functions 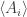 are linearly independent at this point, these functions will be a coordinate system in some neighborhood of this point, by the
are linearly independent at this point, these functions will be a coordinate system in some neighborhood of this point, by the  Let’s call these coordinates
Let’s call these coordinates 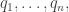 so that
so that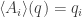
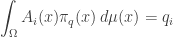

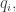 while
while 
 is energy,
is energy, 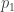 is 1/temperature.
is 1/temperature. is volume,
is volume, 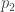 is –pressure/temperature.
is –pressure/temperature. is the number of particles,
is the number of particles, 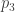 is chemical potential / pressure.
is chemical potential / pressure.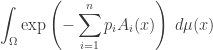
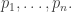 But in my discussion of Gibbsian statistical manifolds, I was assuming that an entropy-maximizing probability distribution
But in my discussion of Gibbsian statistical manifolds, I was assuming that an entropy-maximizing probability distribution 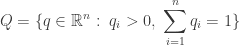
 We have a function
We have a function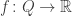

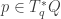 by
by
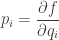

 is called the surprisal of the probability distribution at
is called the surprisal of the probability distribution at 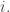 Intuitively, it’s a measure of how surprised you should be if an event of probability
Intuitively, it’s a measure of how surprised you should be if an event of probability 

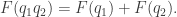
 must be of this form:
must be of this form: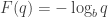
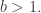 We shall choose
We shall choose 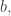 the base of our logarithms, to be
the base of our logarithms, to be 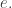 We had a similar freedom of choice in defining the Shannon entropy, and we will use base
We had a similar freedom of choice in defining the Shannon entropy, and we will use base  for both to be consistent. If we chose something else, it would change the surprisal and the Shannon entropy by the same constant factor.
for both to be consistent. If we chose something else, it would change the surprisal and the Shannon entropy by the same constant factor.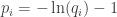
 is not all of
is not all of 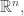 but just the subspace consisting of vectors whose components sum to zero:
but just the subspace consisting of vectors whose components sum to zero:


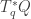 thus consists of linear functionals
thus consists of linear functionals  modulo those that vanish on vectors
modulo those that vanish on vectors  obeying the equation
obeying the equation
 with
with 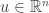 corresponds to the linear functional
corresponds to the linear functional
 vanishes on all vectors
vanishes on all vectors  has
has


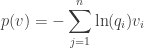
 We compute:
We compute:


 at some earlier time
at some earlier time 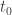 to the position
to the position  is a symplectic manifold and imposing the constraint
is a symplectic manifold and imposing the constraint 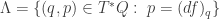
 along with
along with  and these constraints pick out a Legendrian submanifold
and these constraints pick out a Legendrian submanifold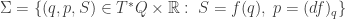
 possible states. We’ll call these
possible states. We’ll call these 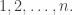 So, if you don’t want to think about physics, when I say microstate I’ll just mean an integer from 1 to n.
So, if you don’t want to think about physics, when I say microstate I’ll just mean an integer from 1 to n.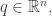 though not every vector in
though not every vector in 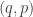 consisting of a point
consisting of a point 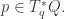 In classical mechanics the point
In classical mechanics the point 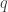
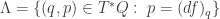
 vanishes when restricted to it:
vanishes when restricted to it: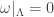
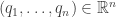
 on the cotangent bundle
on the cotangent bundle 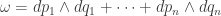
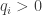 to ensure
to ensure 

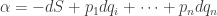
 where we remember that entropy is a function of the probability distribution
where we remember that entropy is a function of the probability distribution  and define
and define 
 with n position coordinates
with n position coordinates 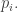
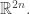 When we change coordinates, it turns out that the splitting of coordinates into positions and momenta is somewhat arbitrary. For example, the position of a rock on a spring now may determine its momentum a while later, and vice versa. What’s not arbitrary? It’s the so-called ‘
When we change coordinates, it turns out that the splitting of coordinates into positions and momenta is somewhat arbitrary. For example, the position of a rock on a spring now may determine its momentum a while later, and vice versa. What’s not arbitrary? It’s the so-called ‘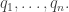 Its entropy will be a function of these variables, say
Its entropy will be a function of these variables, say
 having n coordinates called
having n coordinates called 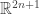 having one extra coordinate
having one extra coordinate 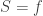
 You can check that this subset, say
You can check that this subset, say  is an n-dimensional submanifold. But even better, the contact 1-form vanishes when restricted to this submanifold:
is an n-dimensional submanifold. But even better, the contact 1-form vanishes when restricted to this submanifold: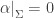
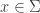 and suppose
and suppose  is a vector tangent to
is a vector tangent to  . It suffices to show
. It suffices to show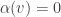
 this equation says
this equation says


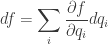
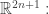 that is, an n-dimensional submanifold such that the contact 1-form vanishes when restricted to this submanifold. And the idea is that this submanifold tells you everything you need to know about a thermodynamic system.
that is, an n-dimensional submanifold such that the contact 1-form vanishes when restricted to this submanifold. And the idea is that this submanifold tells you everything you need to know about a thermodynamic system.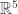 with coordinates energy, entropy, temperature, pressure and volume the ‘Gibbs manifold’, and he proclaims:
with coordinates energy, entropy, temperature, pressure and volume the ‘Gibbs manifold’, and he proclaims: on it called the
on it called the  we have to say what
we have to say what 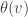 is. Using the projection
is. Using the projection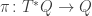
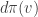 at the point
at the point 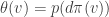
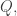 we get local coordinates
we get local coordinates  on the cotangent bundle of this open set in the usual way. On this open set you then get
on the cotangent bundle of this open set in the usual way. On this open set you then get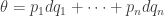
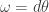
 , which we can think of as a map
, which we can think of as a map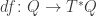
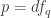
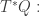 that is, an n-dimensional submanifold
that is, an n-dimensional submanifold  such that
such that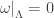
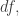 not the actual value of the entropy function
not the actual value of the entropy function 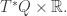 The extra dimension represents entropy, so we’ll use
The extra dimension represents entropy, so we’ll use 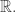
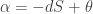
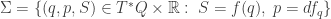
 of the ith type changing at a rate equal to
of the ith type changing at a rate equal to  of that type. Suppose the fitness
of that type. Suppose the fitness  . Let
. Let 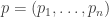 is a time-dependent probability distribution, and we prove that its speed as measured by the Fisher information metric equals the variance in fitness. In rough terms, this says that the speed at which information is updated through natural selection equals the variance in fitness. This result can be seen as a modified version of Fisher’s fundamental theorem of natural selection. We compare it to Fisher’s original result as interpreted by Price, Ewens and Edwards.
is a time-dependent probability distribution, and we prove that its speed as measured by the Fisher information metric equals the variance in fitness. In rough terms, this says that the speed at which information is updated through natural selection equals the variance in fitness. This result can be seen as a modified version of Fisher’s fundamental theorem of natural selection. We compare it to Fisher’s original result as interpreted by Price, Ewens and Edwards.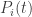 . Suppose
. Suppose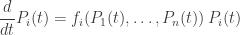
 is
is
 is the fraction of replicators of the ith type:
is the fraction of replicators of the ith type: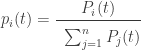

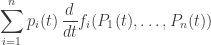
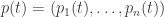
 changes with time, the rate at which information is updated is closely connected to its Fisher speed. Thus, our revised version of the fundamental theorem of natural selection can be loosely stated as follows:
changes with time, the rate at which information is updated is closely connected to its Fisher speed. Thus, our revised version of the fundamental theorem of natural selection can be loosely stated as follows:

